-
-
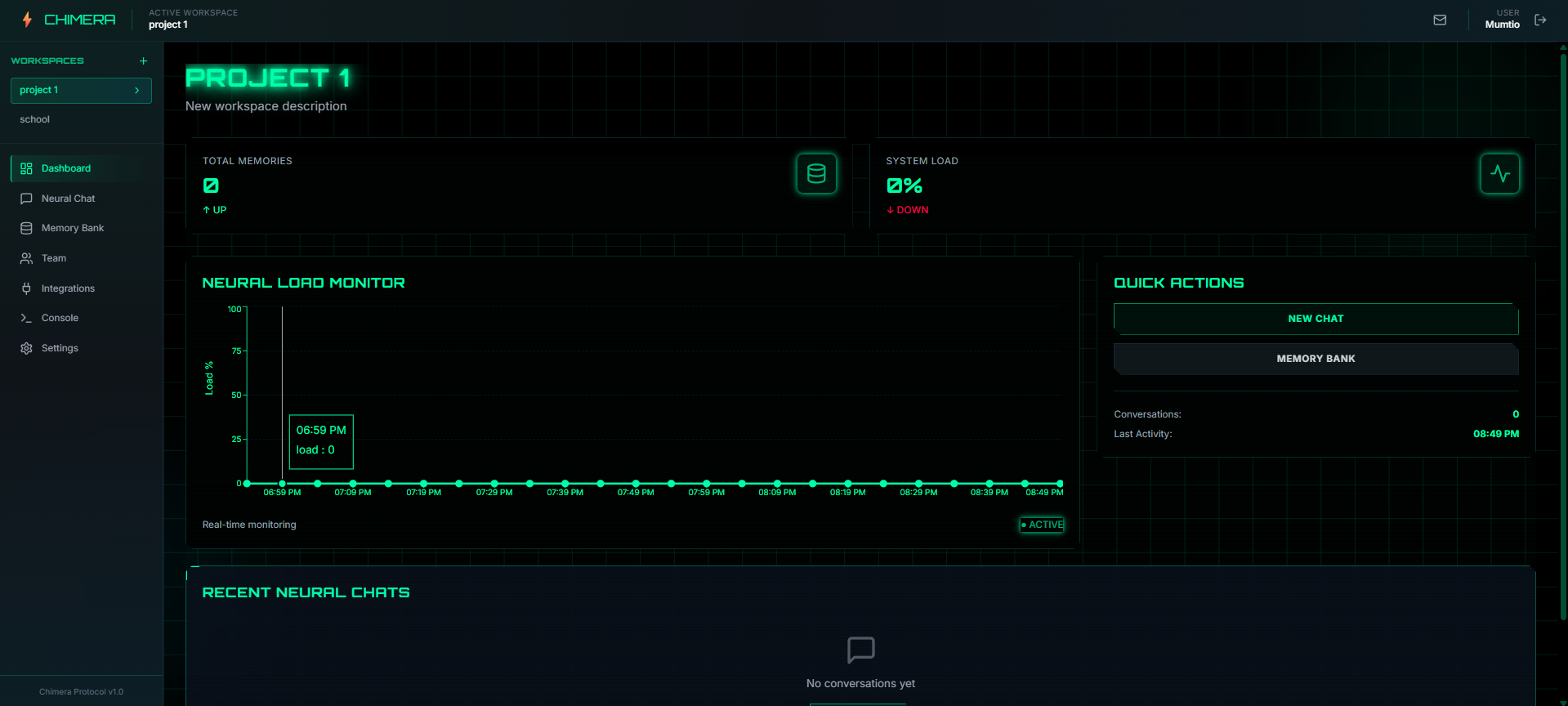
Workspace Dashboard
-
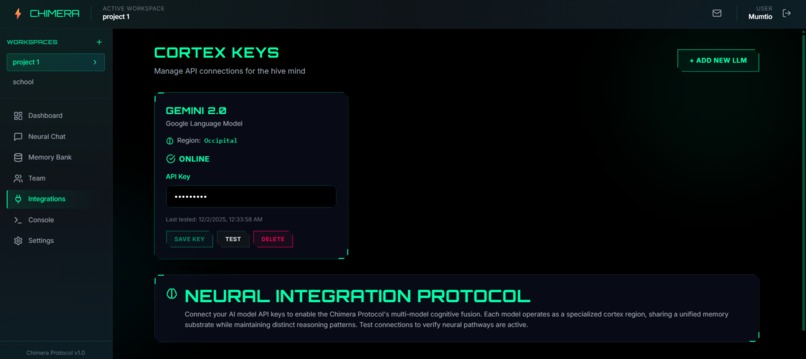
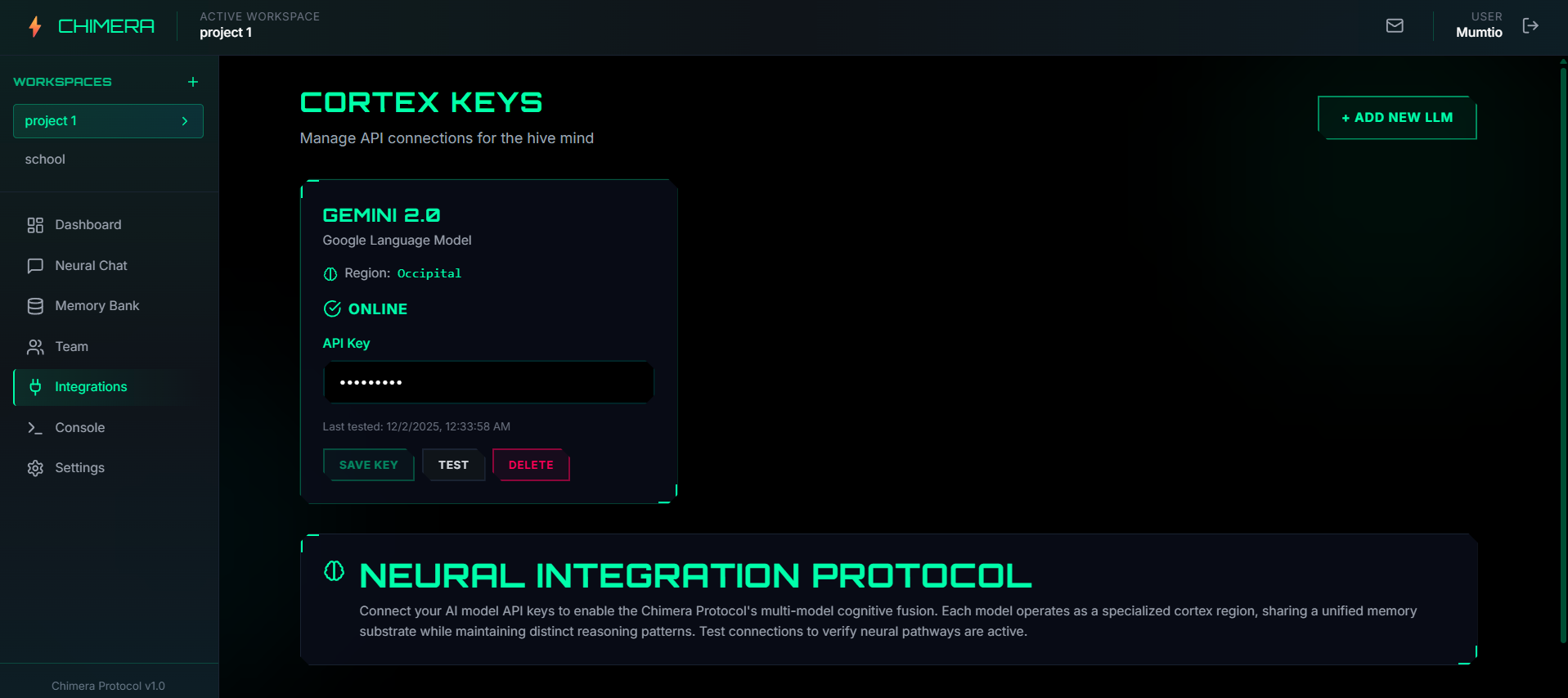
Integrate any LLM model using API keys
-

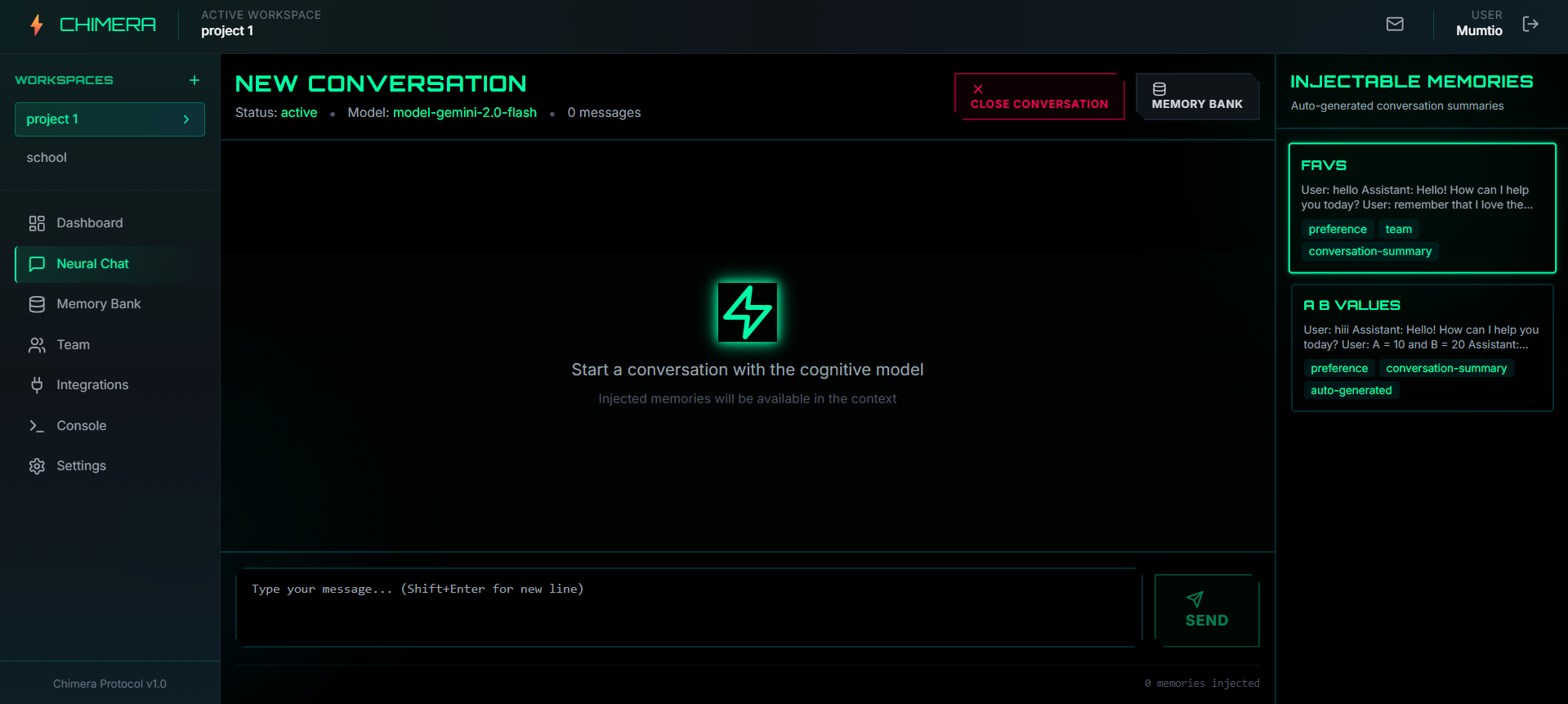
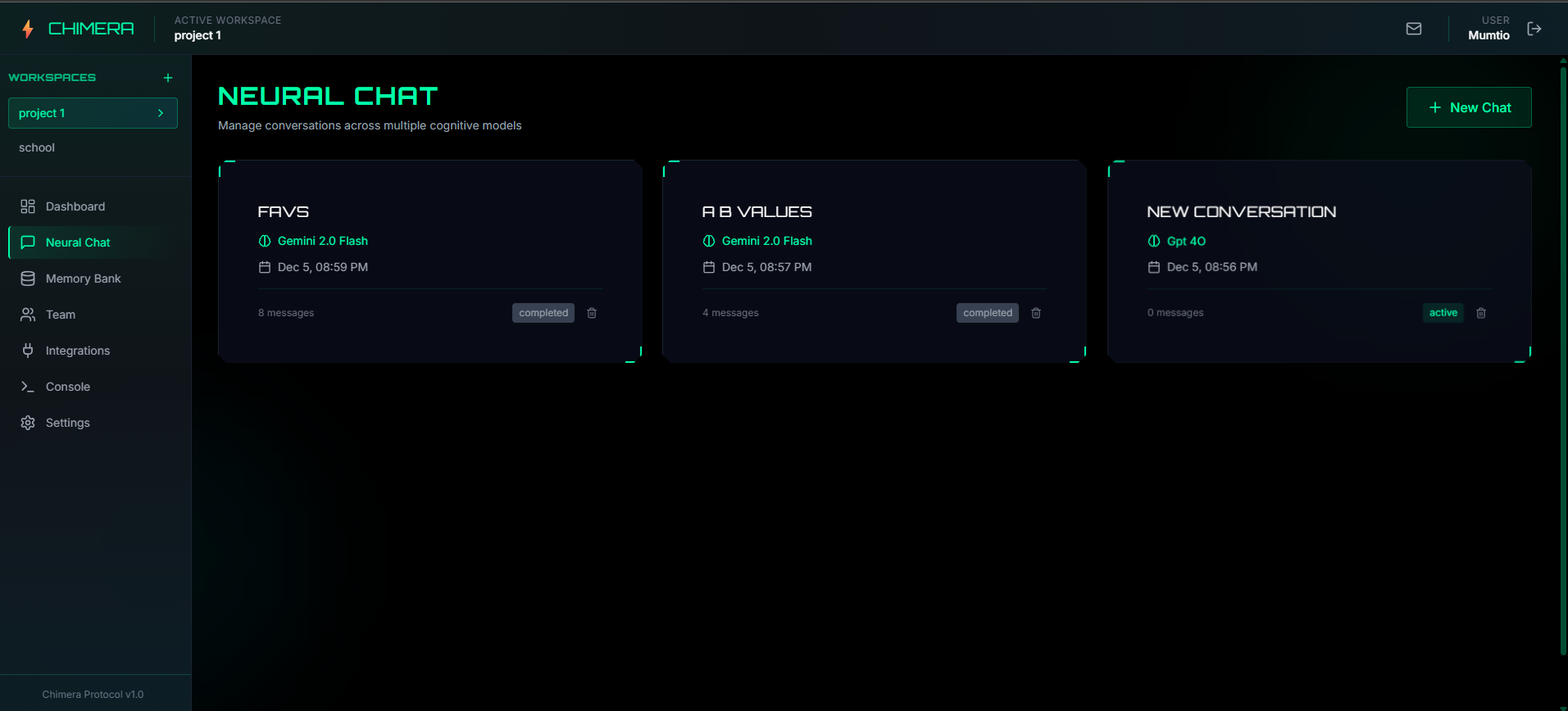
Selecting LLM model to start chatting
-
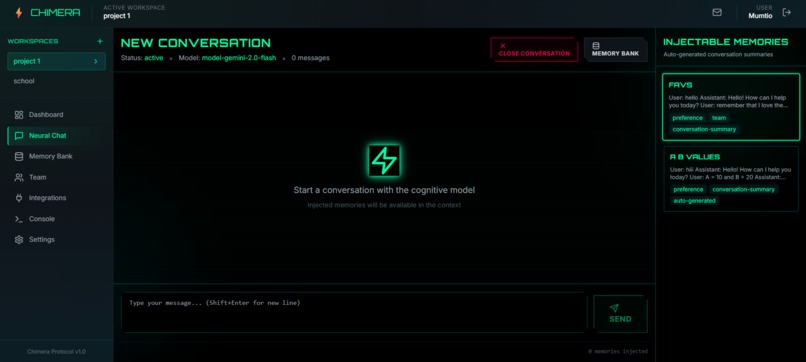
Chat interface for memory injection
-
Chat history to pickup chat with LLMs where you've left off
-
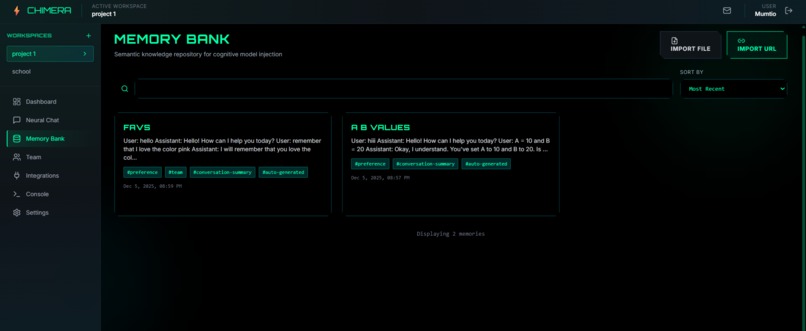
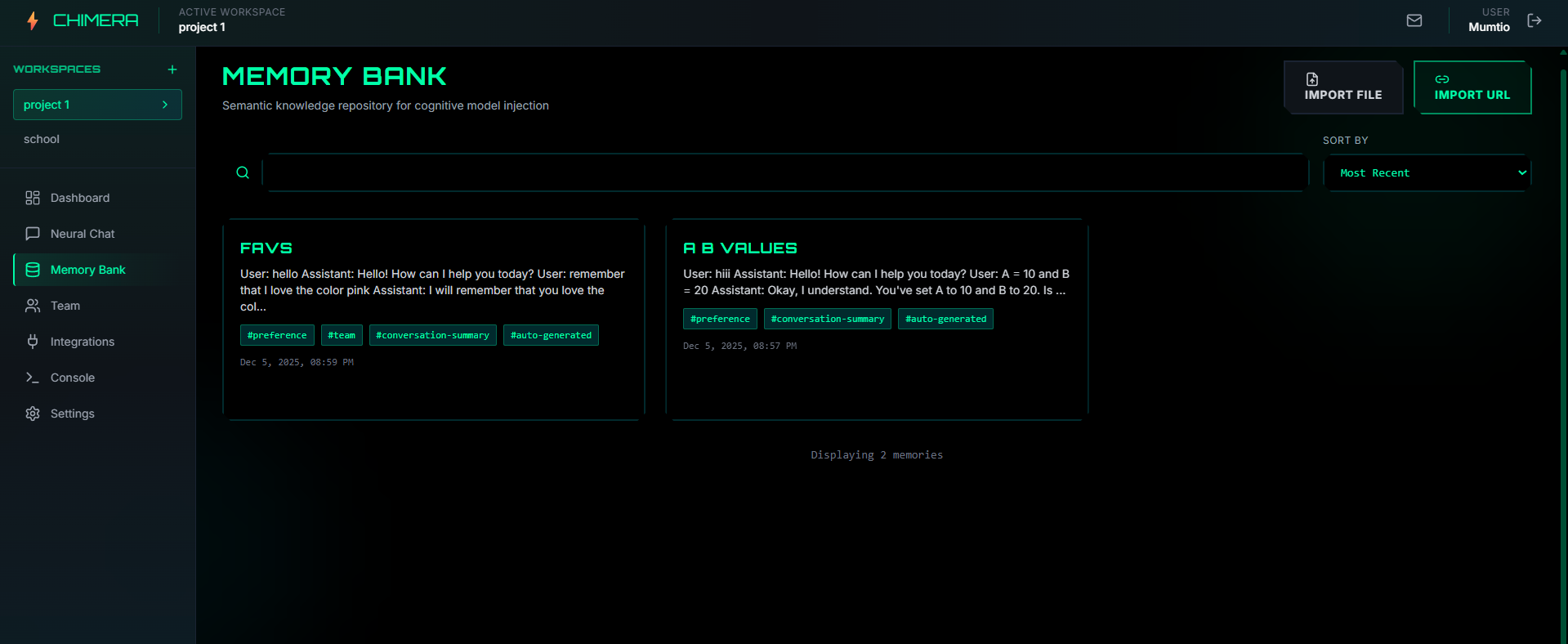
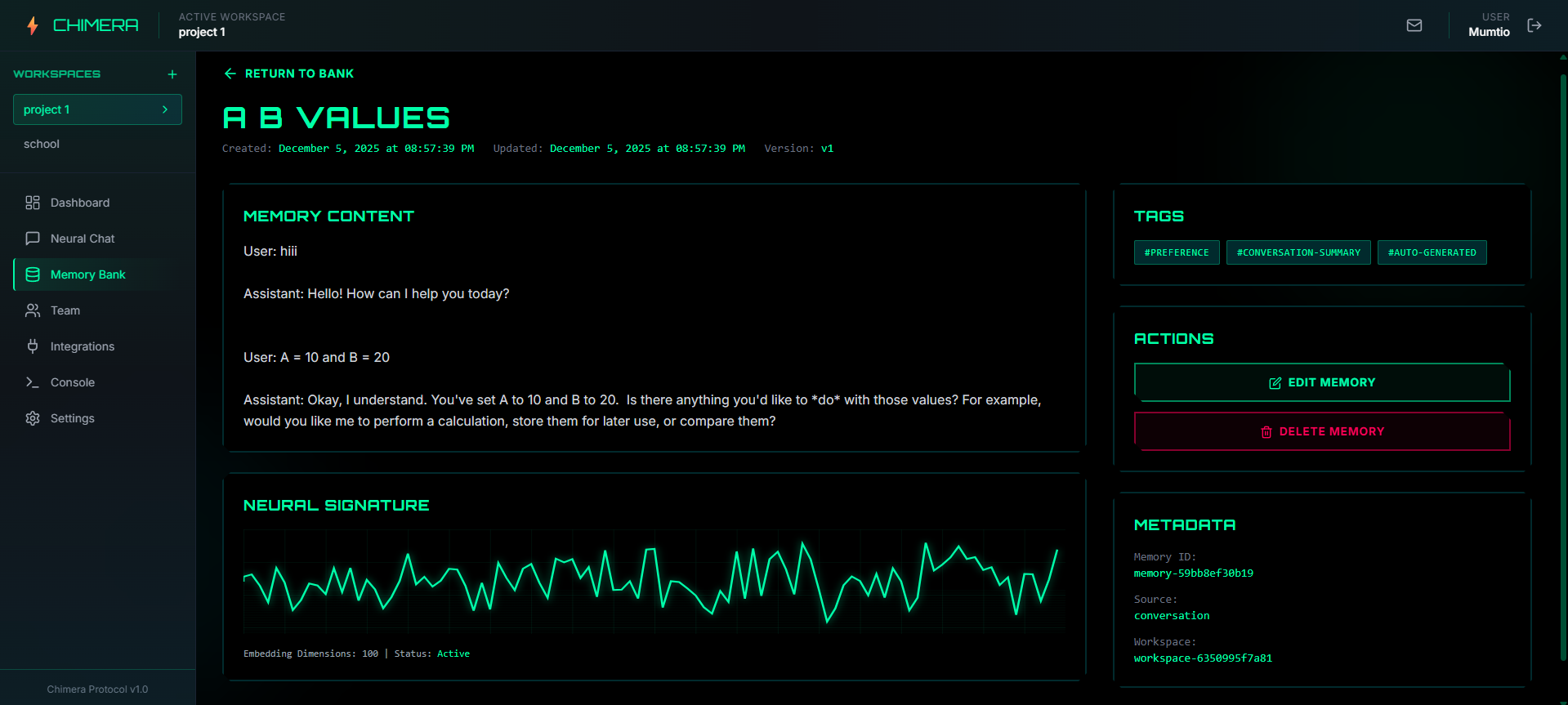
Memory bank shows all the saved memory that can be edited, viewed or deleted
-
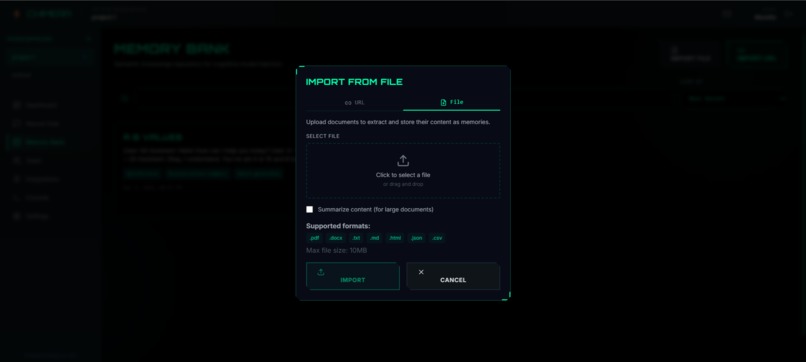
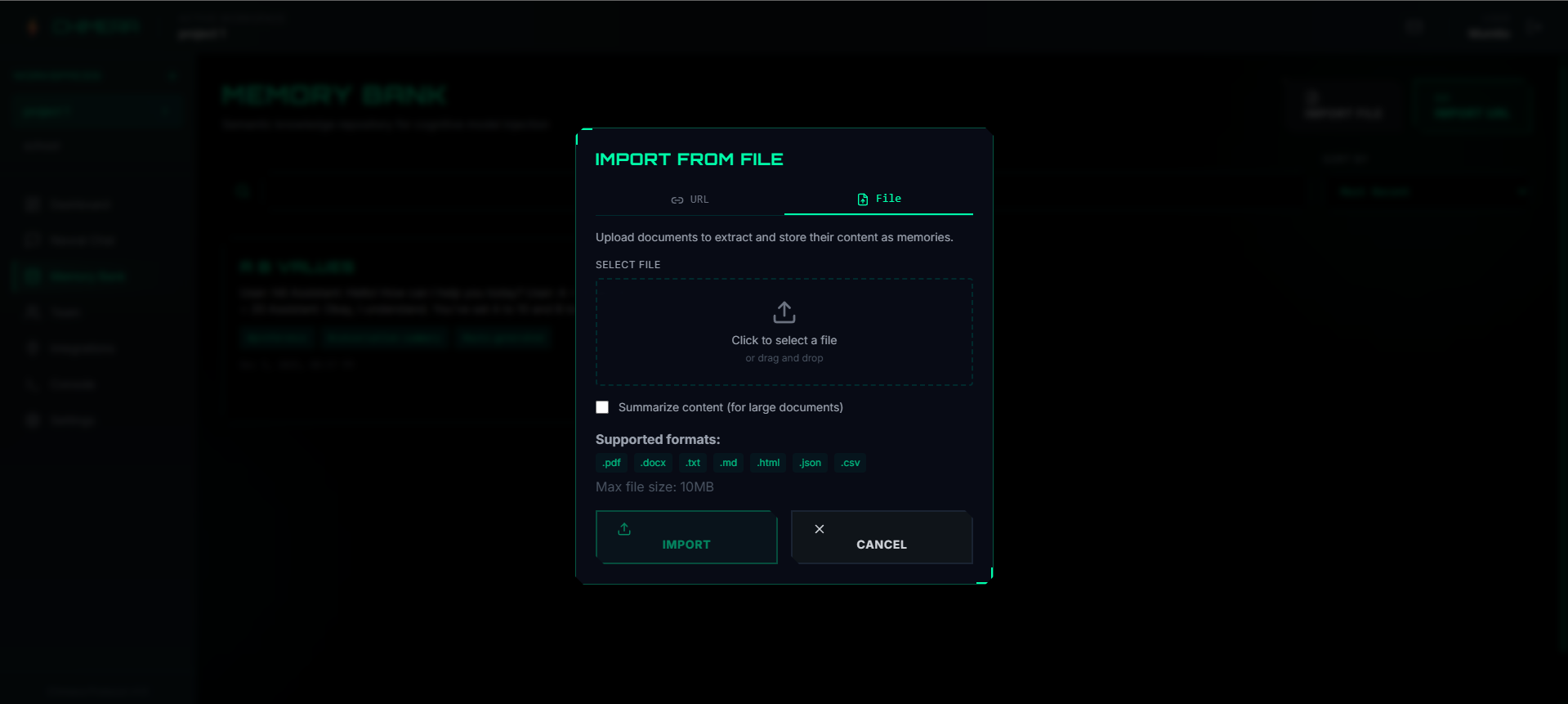
Creating memory from any file
-
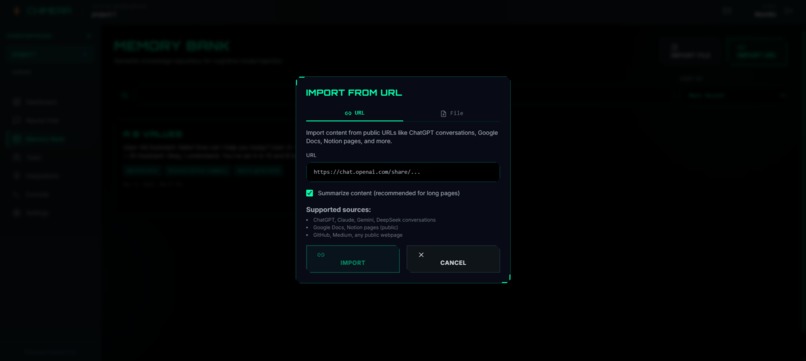
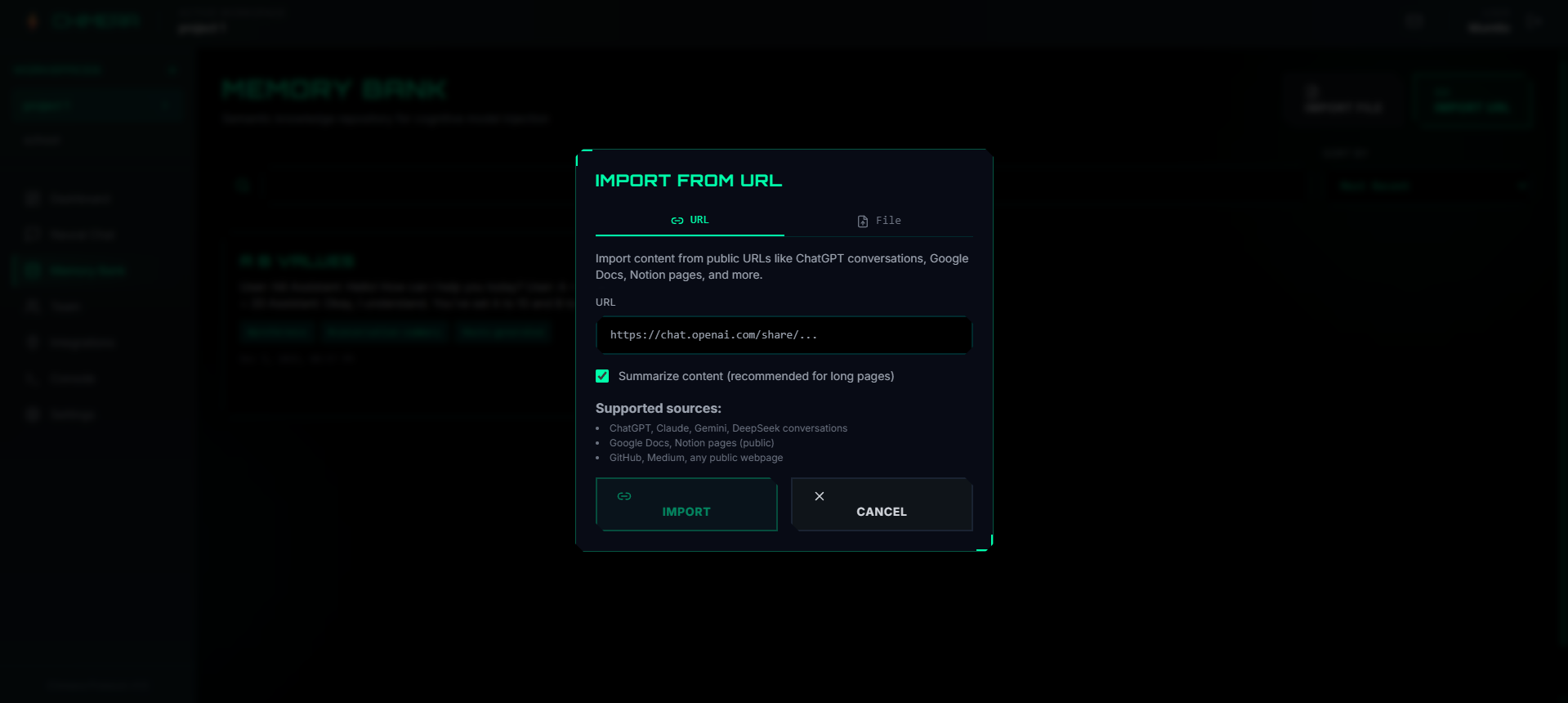
Creating memory from any external link
-
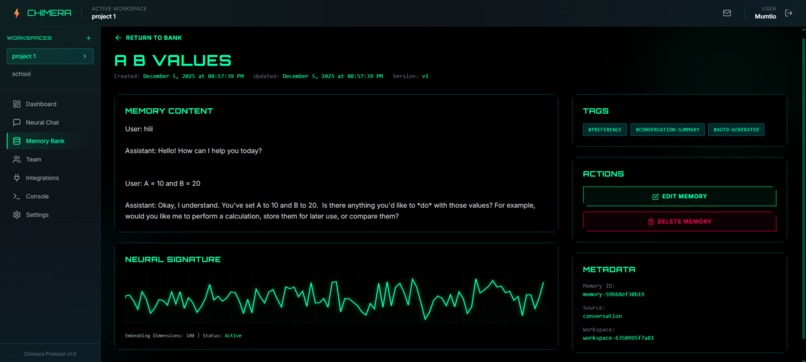
Viewing a memory
-
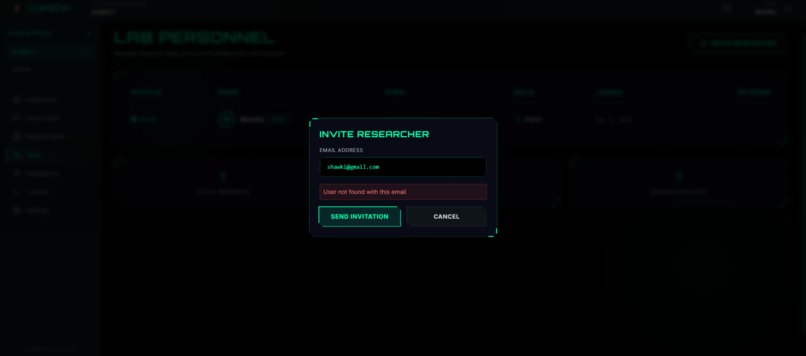
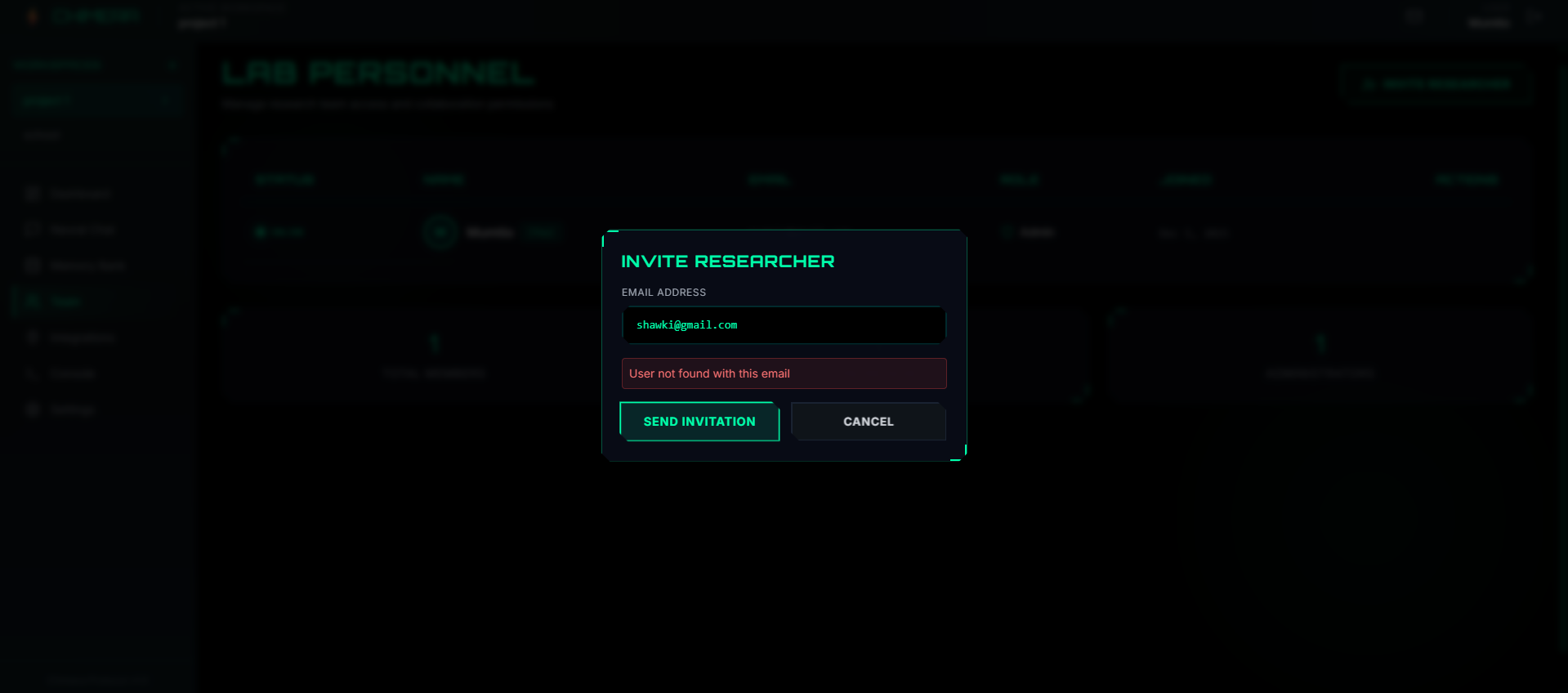
Sending other users invitation to join workspace
-
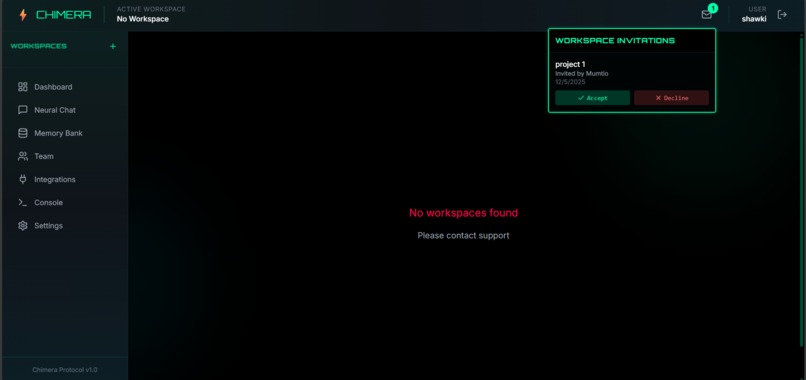
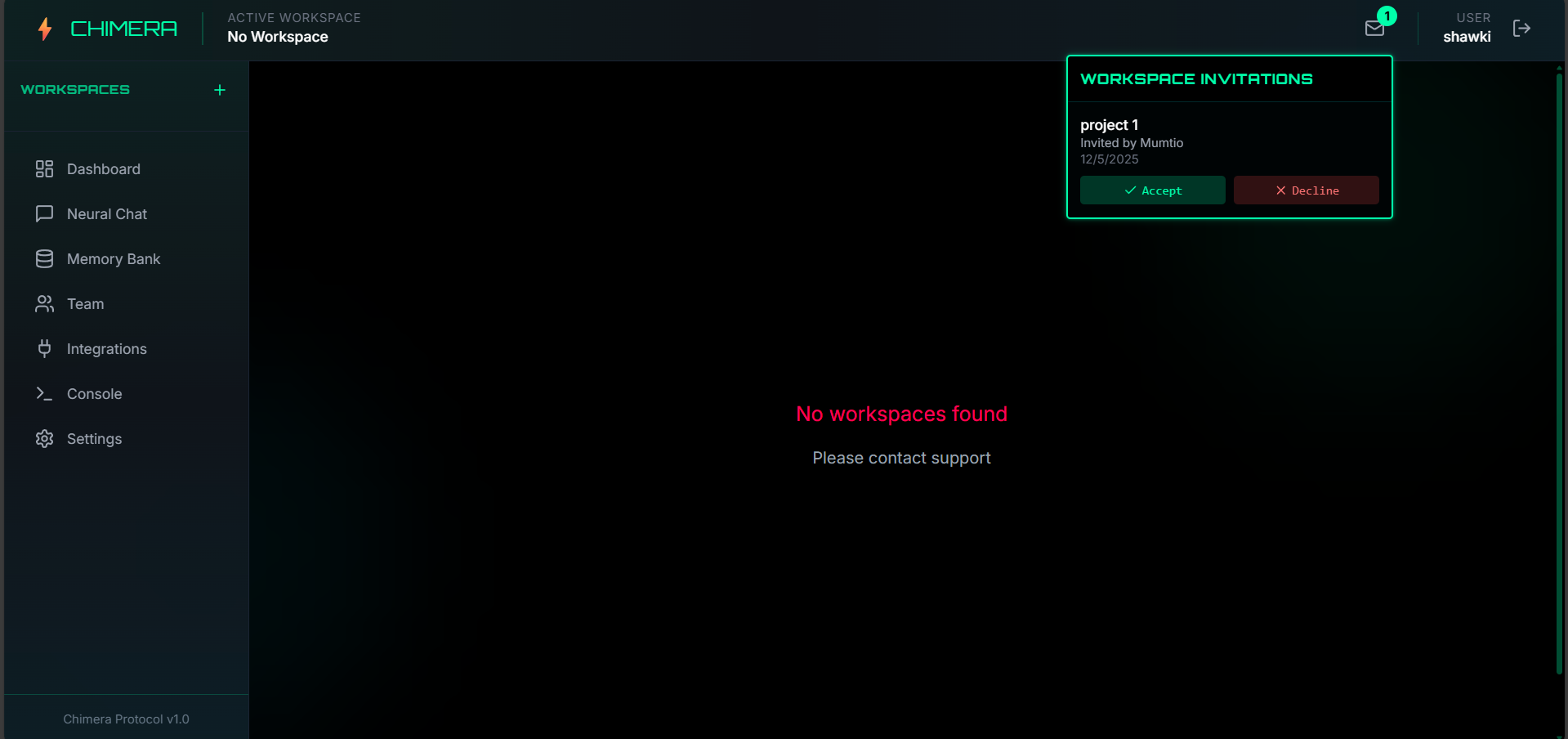
Receiving invitations to join workspace
-
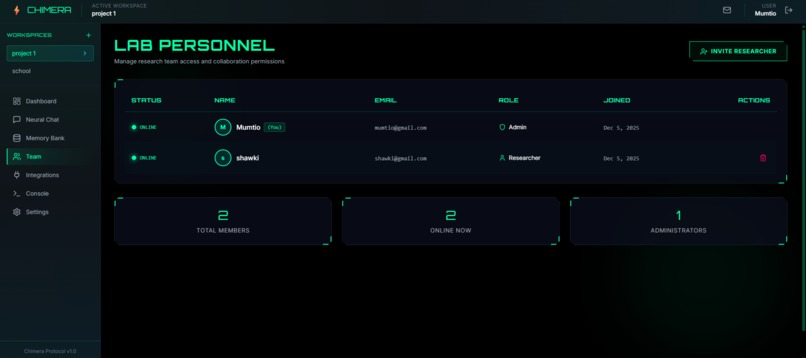
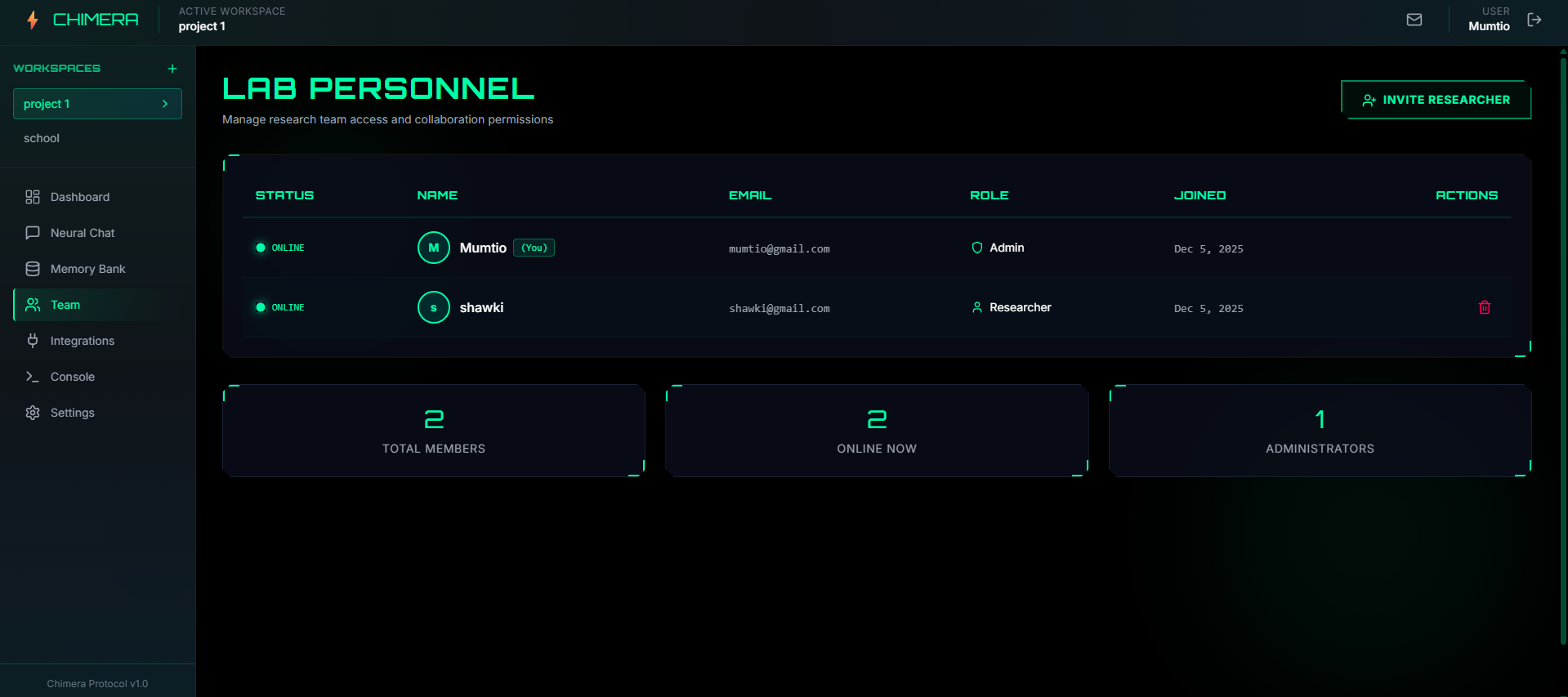
Team Manager
-
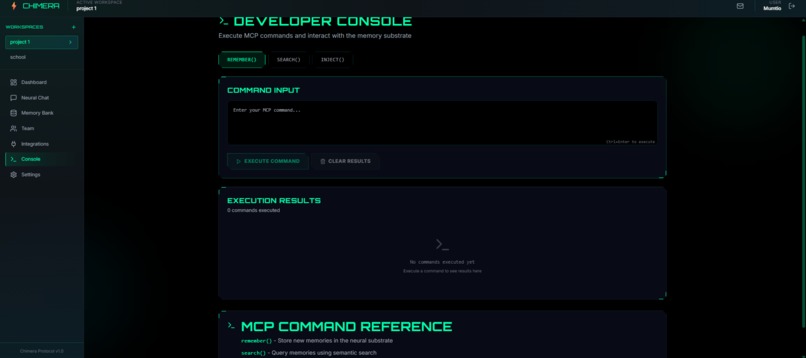
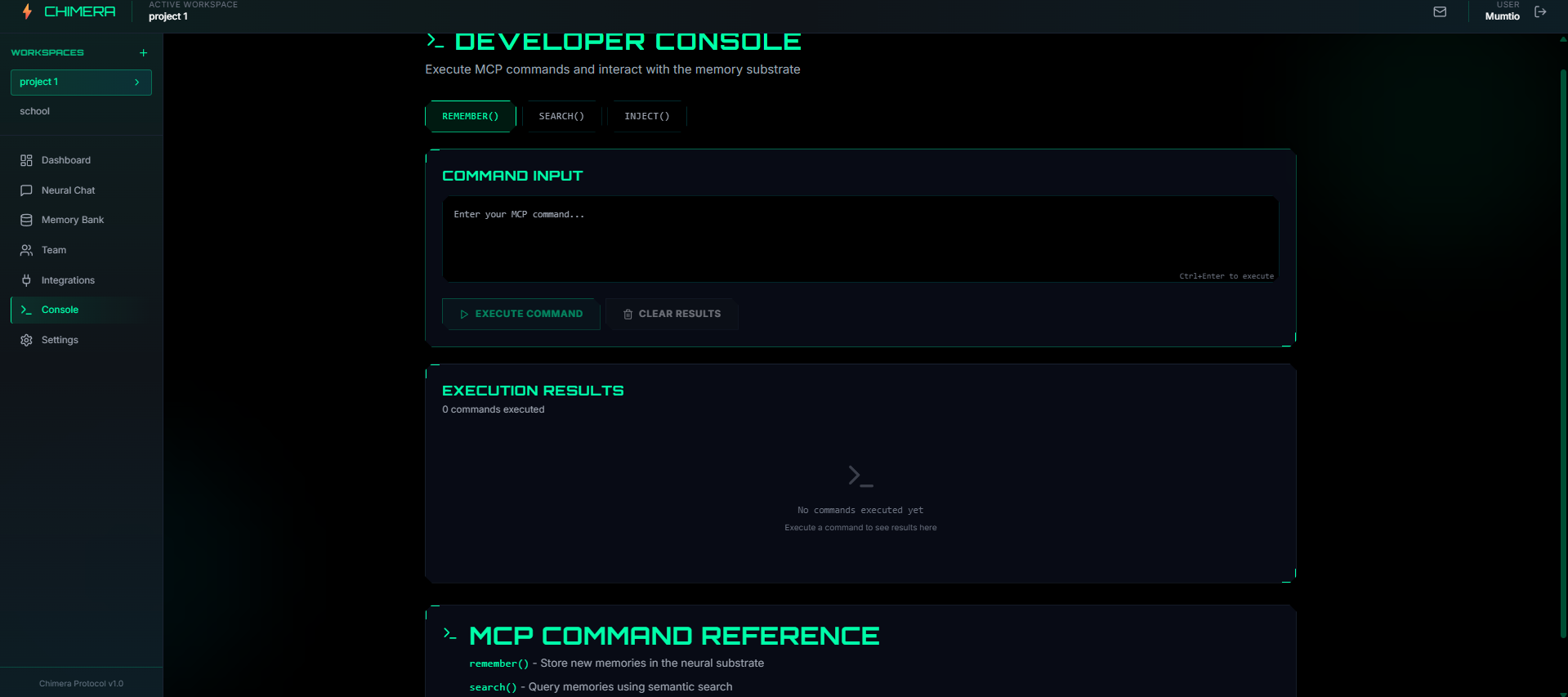
Developer Console
-
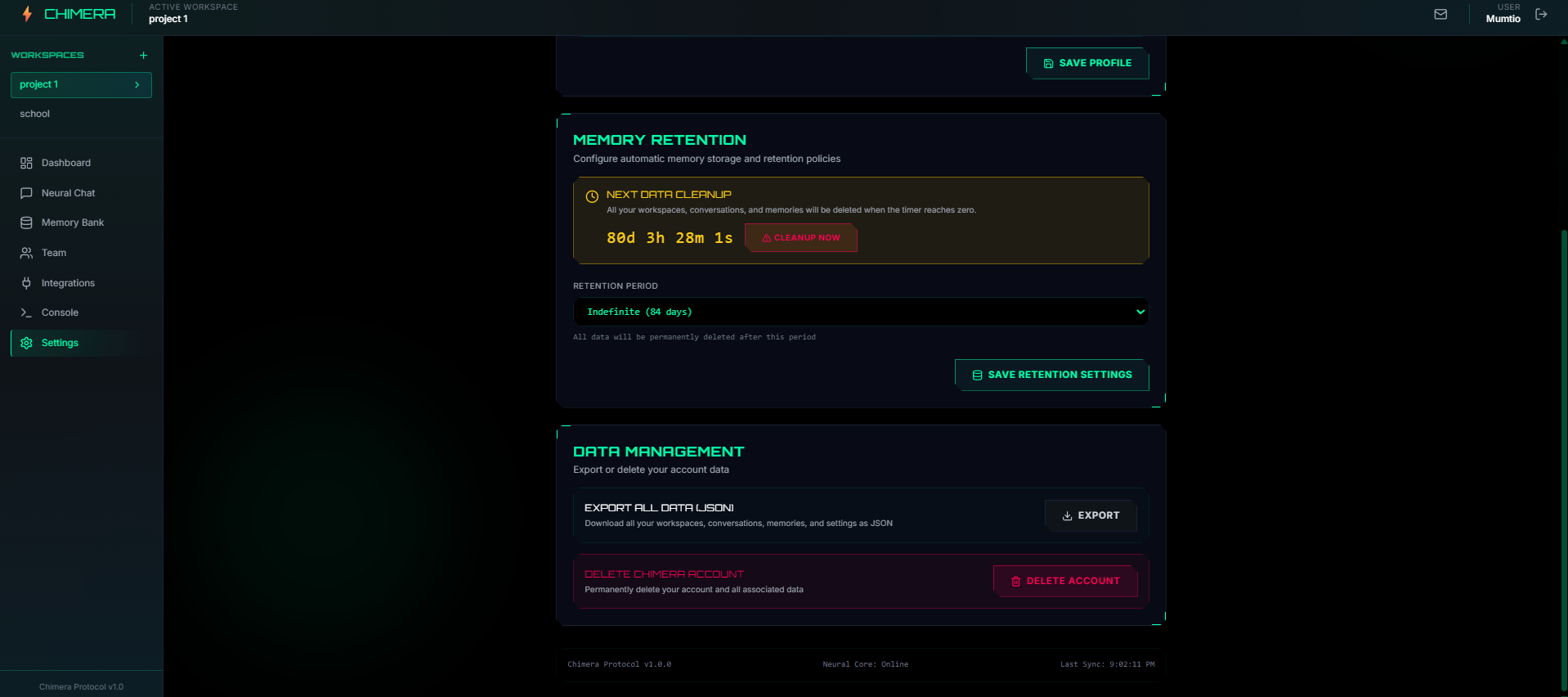
Settings

Chimera Protocol
🔐 Demo Access
Test Credentials:
- Email:
mumtio@gmail.com - Password:
mumtiomumtio
Note: First login may take a moment while the server wakes up.
💡 Inspiration
Every time we switched LLMs, GPT to Claude to Gemini, we hit the same wall: total amnesia.
New model. New brain. Back to square one.
In team projects, it was chaos. Every teammate's AI had its own memory, its own confusion, its own version of reality. Context scattered like disconnected limbs on a mad scientist's lab table.
We didn't need another chatbot. We needed a monster.
So we built Chimera Protocol, a Frankenstein creation that stitches fragmented AI memories into one shared, persistent intelligence that any model can access.
One memory. Multiple minds.

🧠 What It Does
Chimera Protocol is a universal memory layer for AI conversations.
Core Capabilities:
- Multi-LLM Router: Connect OpenAI, Anthropic, Google, DeepSeek, and more through a single interface
.png)
.png)
- Persistent Memory: Every message is vectorized and stored. Context never dies.
.png)
.png)
- Memory Injection: Inject stored knowledge into any model, any conversation, anytime
.png)
- Universal Import: Create memories from PDFs, documents, webpages, or raw text
.png)
- Team Workspaces: Collaborative spaces with role-based access control
- Real-Time Collaboration: Multiple users can work in the same workspace simultaneously with live updates
- Developer Console: MCP server for inspecting memory retrievals, prompt construction, and routing logic
- Full Data Export: Download everything as JSON: memories, chats, embeddings, settings
The result? Claude remembers what you told GPT-4 last week. Your team's AI shares one brain instead of five confused ones.
🛠️ How We Built It
Chimera was built using spec-driven development with Kiro.
We started with comprehensive requirements in .kiro/specs/, then iteratively implemented across the full stack:
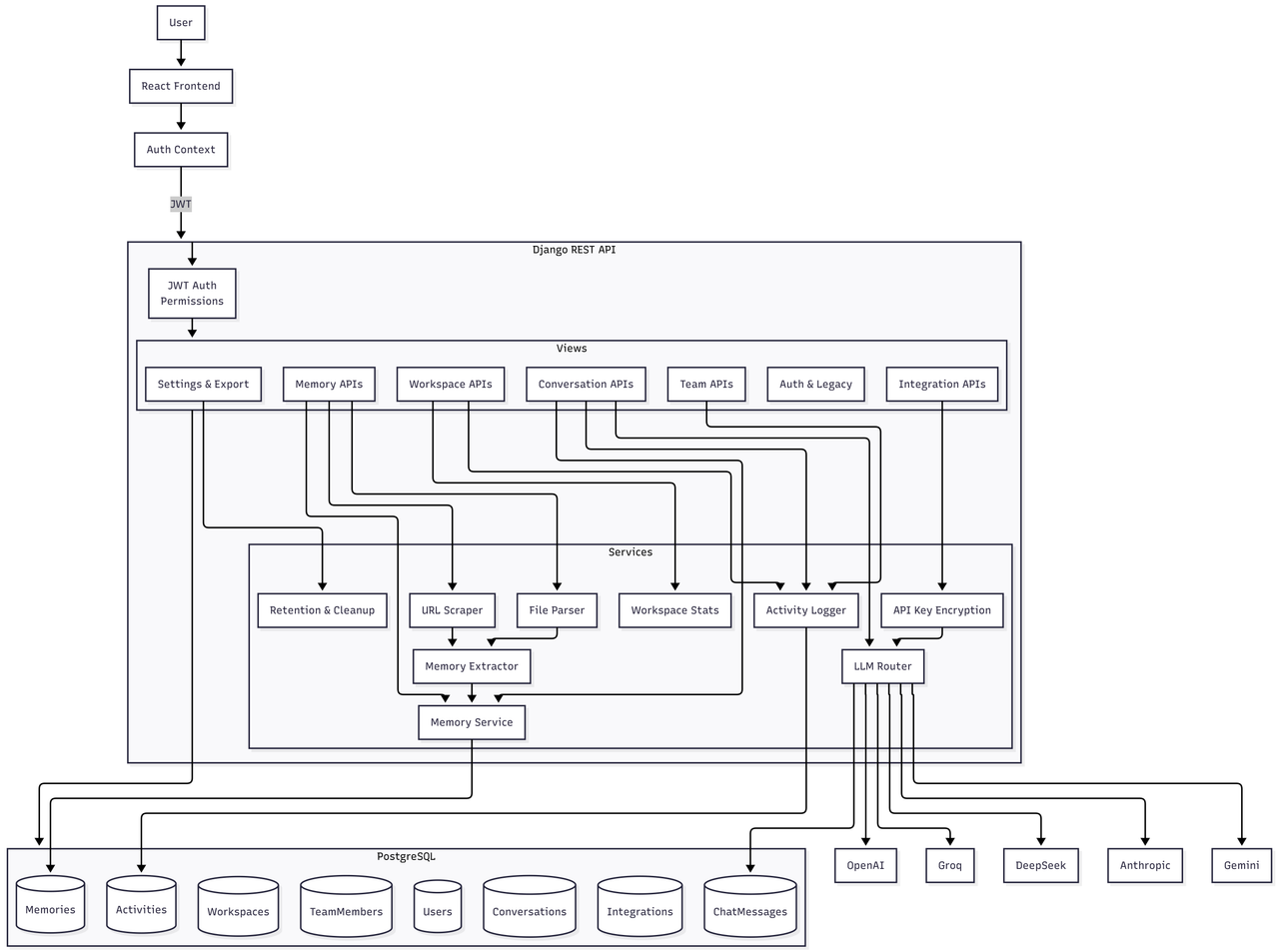
Frontend: React/TypeScript SPA with a cyberpunk neural aesthetic, neon greens, angular frames, and a 3D brain visualization built with Three.js where AI models appear as glowing nodes.
Backend: Django REST Framework handling JWT authentication, workspace management, encrypted API key storage (Fernet), and multi-LLM routing.
The Innovation: Our memory injection system stores knowledge fragments and prepends them as context to any AI conversation. Simple concept, powerful result: true cross-model memory sharing.
Kiro's Role:
- Steering rules maintained code consistency across 50+ files
- Agent hooks automated repetitive workflows
- Spec-driven approach prevented architectural rewrites
- Vibe coding debugged full-stack issues in real-time
System Design :
🚧 Challenges We Ran Into
Multi-LLM API Chaos: OpenAI, Anthropic, Google, and DeepSeek all speak different languages. Different auth patterns, request formats, error responses. Building a unified router that handles all gracefully took serious iteration.
3D Performance vs. React State: Three.js and React don't naturally play nice. Getting smooth renders while maintaining state sync required careful optimization with useMemo and proper resource disposal.
The Scrollbar From Hell: Chat interfaces sound simple until messages jump, scroll positions reset, and the scrollbar refuses to reach the bottom. Multiple iterations to nail the flex layout.
Security Without Friction: Storing API keys securely (Fernet encryption) while still being able to decrypt them for live API calls. The balance between security and usability.
🏆 Accomplishments We're Proud Of
True Chimera Behavior: Inject the same memory into GPT-4, Claude, or Gemini. They all remember. They all share context. One monster, many heads.
The 3D Brain Interface: Model selection that feels like you're actually interfacing with a neural network. Not a dropdown, an experience.
Real-Time Team Sync: Multiple users collaborating in the same workspace with live updates. No refresh needed.
Full-Stack Coherence: Kiro helped build frontend and backend simultaneously, keeping them perfectly in sync. No integration nightmares.
Zero Dummy Data: Everything works. Real API calls, real persistence, real authentication. This isn't a mockup.
Mad Scientist Aesthetic: The UI genuinely looks like a laboratory for stitching AI minds together. Form matches function.
📚 What We Learned
Specs Save Time: Writing requirements upfront feels slow. It prevents massive rewrites later. Worth it.
Hooks Beat Willpower: Automated reminders enforce consistency better than good intentions ever could.
Simple Solutions Scale: Prepending memories to system prompts? Obvious in hindsight. Works surprisingly well.
AI Assistants Excel at Full-Stack: Kiro's ability to trace issues across frontend/backend boundaries was invaluable. One context, both layers.
🔮 What's Next
RAG Integration: Semantic search to auto-suggest relevant memories based on conversation context
Memory Graphs: Visualize connections between memories as an interactive knowledge graph
Voice Interface: ElevenLabs integration for voice conversations with injected memory
Mobile App: React Native version for on-the-go memory management
Fine-Tuning Pipeline: Use conversation history to fine-tune personal models
Chimera Protocol, because your AI shouldn't have amnesia every time you switch models.
Built with 🧠 and ⚡ for Kiroween Hackathon 2025
Built With
- django
- fernet
- framermotion
- lucidereact
- postgresql
- python
- react18
- reactrouterv6
- recharts
- render
- tailwindcss
- three.js
- vercel
- vite
- zustand
Log in or sign up for Devpost to join the conversation.