-
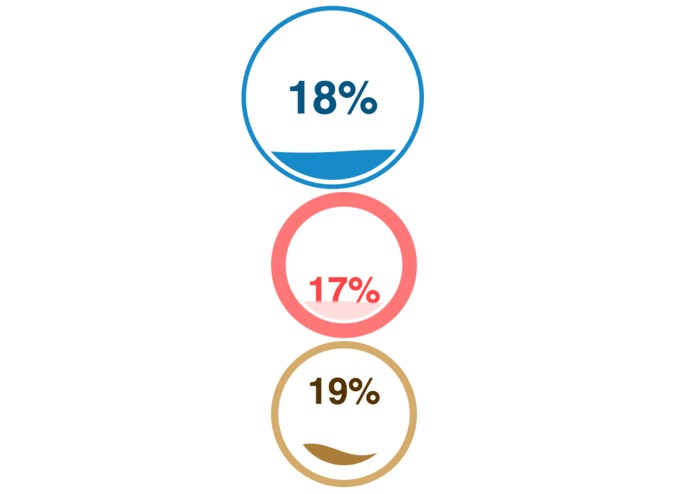
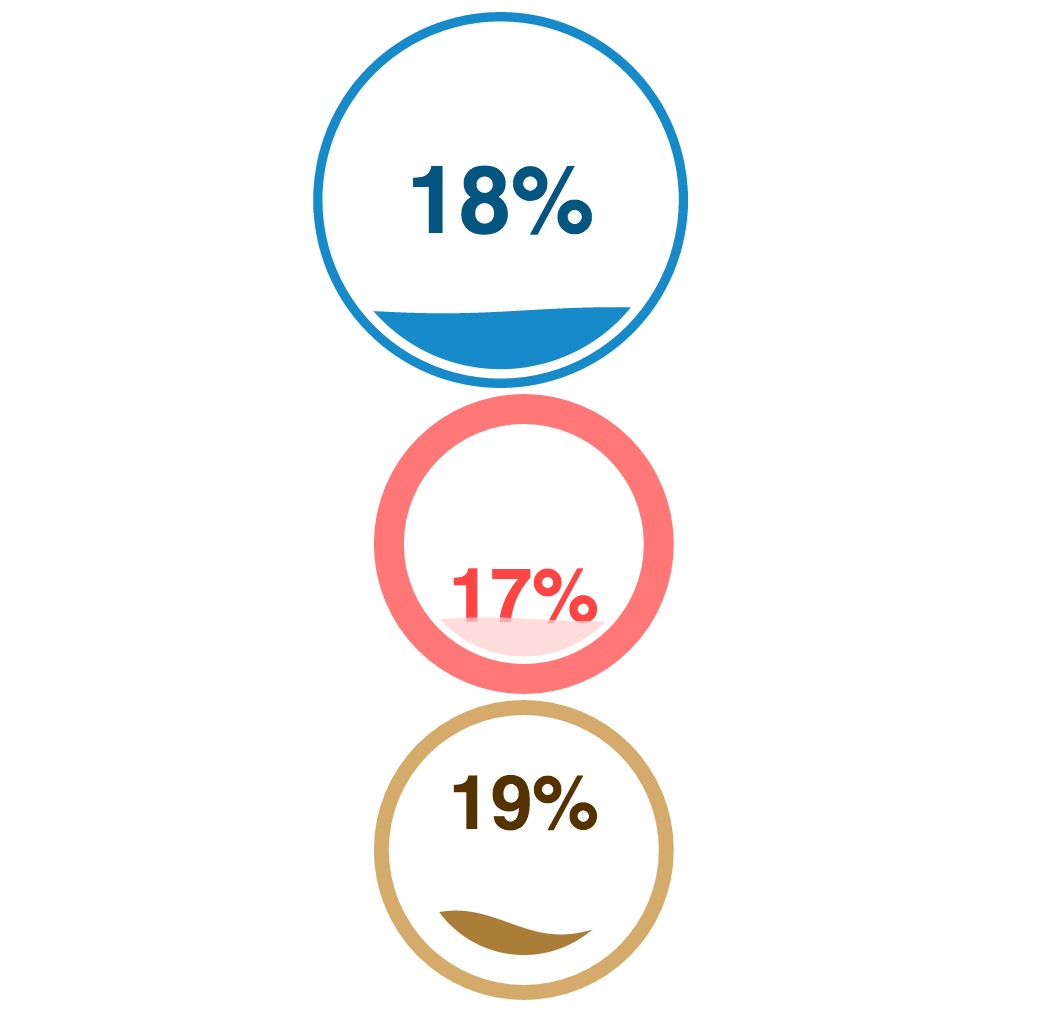
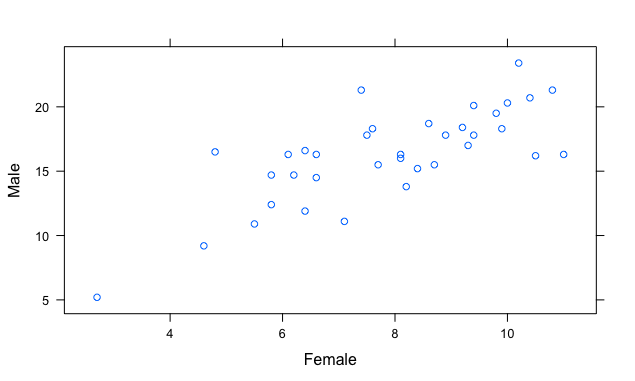
Average alcohol consumption across children aged 13-18 (Top to bottom: total average, female average, male average)
-
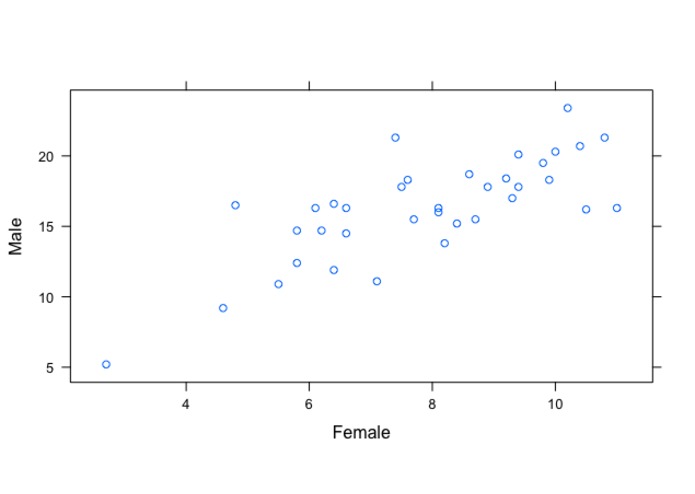
Percentage of teenagers who are currently smoking
-
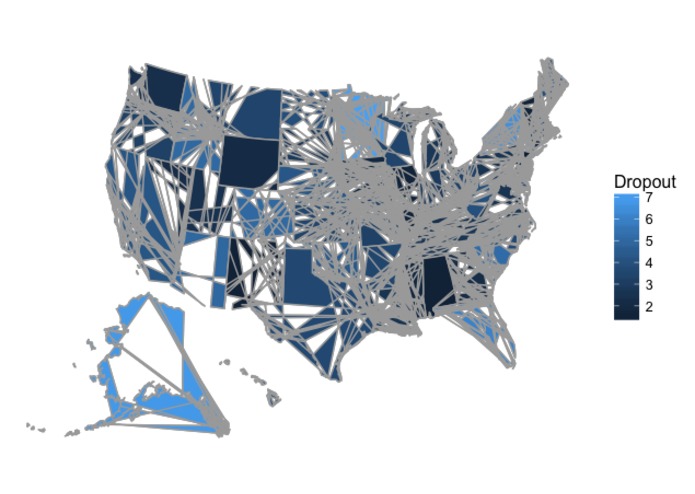
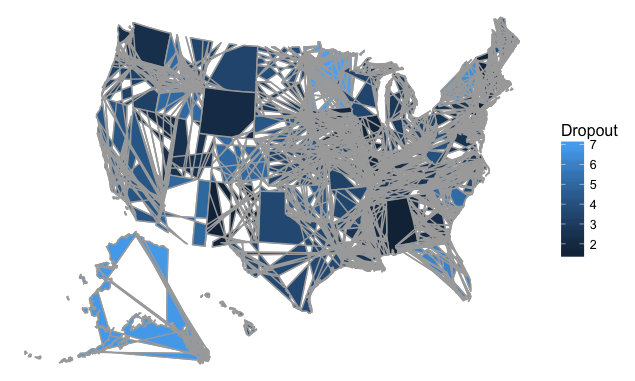
Dropout rates of teenagers
Inspiration
Two months ago, Charlene's cousin was diagnosed with bone cancer. Despite being diagnosed with bone cancer at such a young age, she remained to stay hopeful and strong. Because many children around the world are often overlooked for the kinds of illnesses and diseases they have, this project sought to visualize data and capture any children who are overlooked in the healthcare sector.
What it does
To qualify children for healthcare assistance in the United States, it is often required that they fill out health forms and physical exam forms that inquire their physical state, such as vaccination history, allergy, and medical evaluation. Those factors are conventionally believed to accurately determine whether or not the child qualifies for healthcare assistance. However, children’s health can be more than meets the eye. Focusing just on the physical state may overlook other important factors that may also imply that the child needs healthcare assistance, leaving deserving patients to be uninsured and left out of records in the healthcare system. In addition to examining patient’s physical state, it is therefore important to look at other data outside of healthcare, such as children’s living habits and education that give insight into other factors that may manifest children’s well-being. Our data visualization looks at other non-medical factors that may suggest a child needs medical assistance by exploring three different data: school dropout rates, drinking and smoking habits, and online addiction.
How we built it
We started from collecting the dataset. By parsing public data with Python and JSON, we generated 5 datasets to provide the factors that are critical to solving healthcare issue. We used d3.js and three.js to build interactive data visualization on the Beaker Notebook. Then, we integrated R studio to do statistical analysis.
Challenges we ran into
Originally we wanted to use WebGL's 3D globe to visualize high school drop-out rates across the U.S. throughout different years. However, because the API had lots of dependencies on other sources, it was very difficult to link the data to the Beaker Lab. In addition, when we were visualizing the US Map for dropout rates, we found it hard to create an interactive map with drop-down menu in d3.js. Therefore, we chose to go with R visualization.
Accomplishments
We look into the factors that are very important but often overlooked. We used various data visualization tools, such as the liquid gauge visualizing tool that symbolizes alcohol consumption and using reddit API to learn more about online addiction, and what topic is a concern for teenagers.
What we learned
Different APIs that are available for use, intersection of front-end design and statistics, various javascript tools (e.g. D3), and adapting templates to fit our data.

Log in or sign up for Devpost to join the conversation.