-
-
Landing Page
-
-
Inspiration
We are inspired by Cursor and want to build that for video. Anyone who's used the existing AI video tools knows they do not meet expectations. They work on pixels without any real understanding of what's in the frame. Chiasm fixes that with an ontology layer: a typed, time-scoped graph of the entities and relationships inside every shot. That structured understanding is what makes intelligent editing possible, the same way Cursor's grasp of code is what separates it from plain autocomplete.
What it does
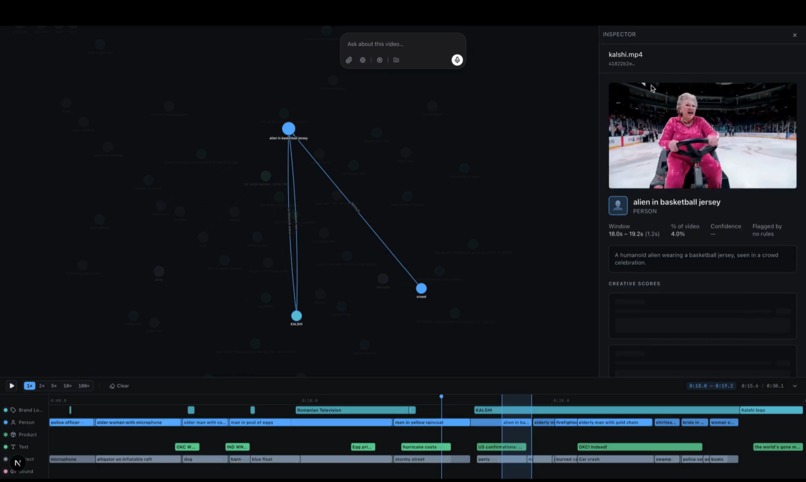
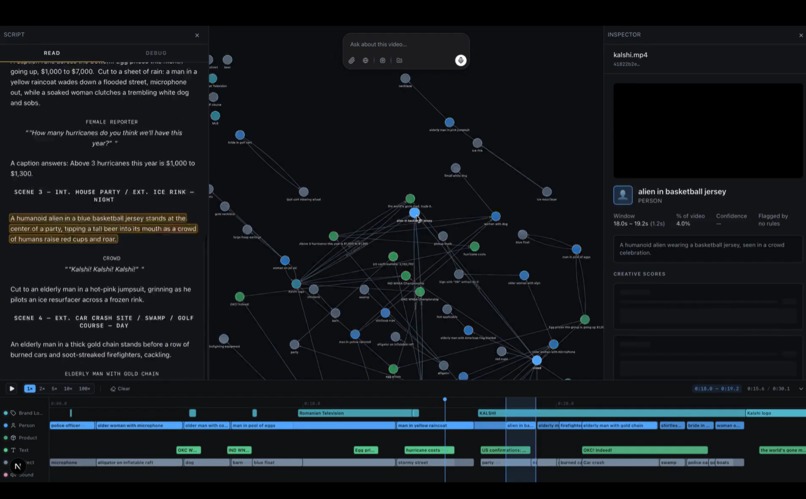
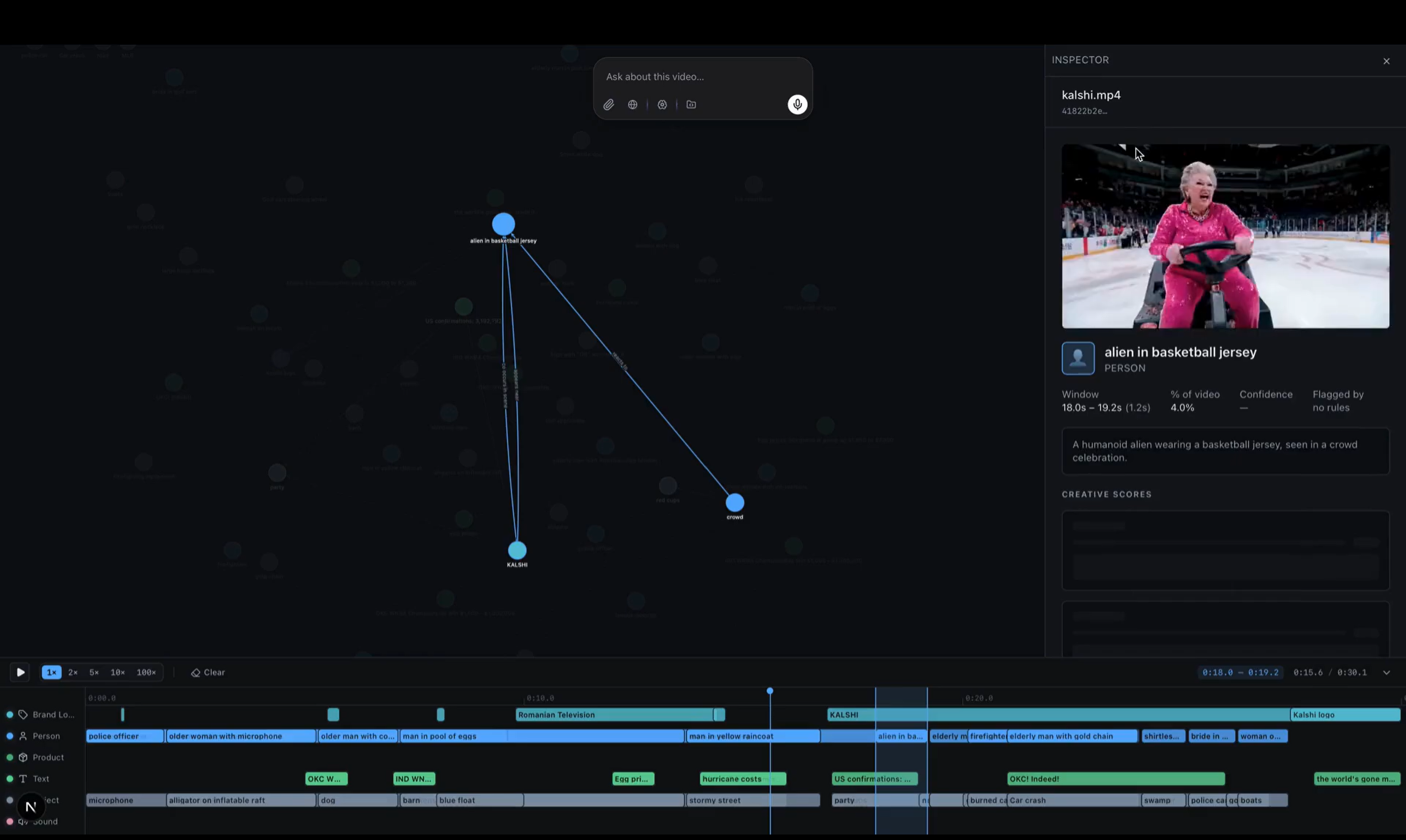
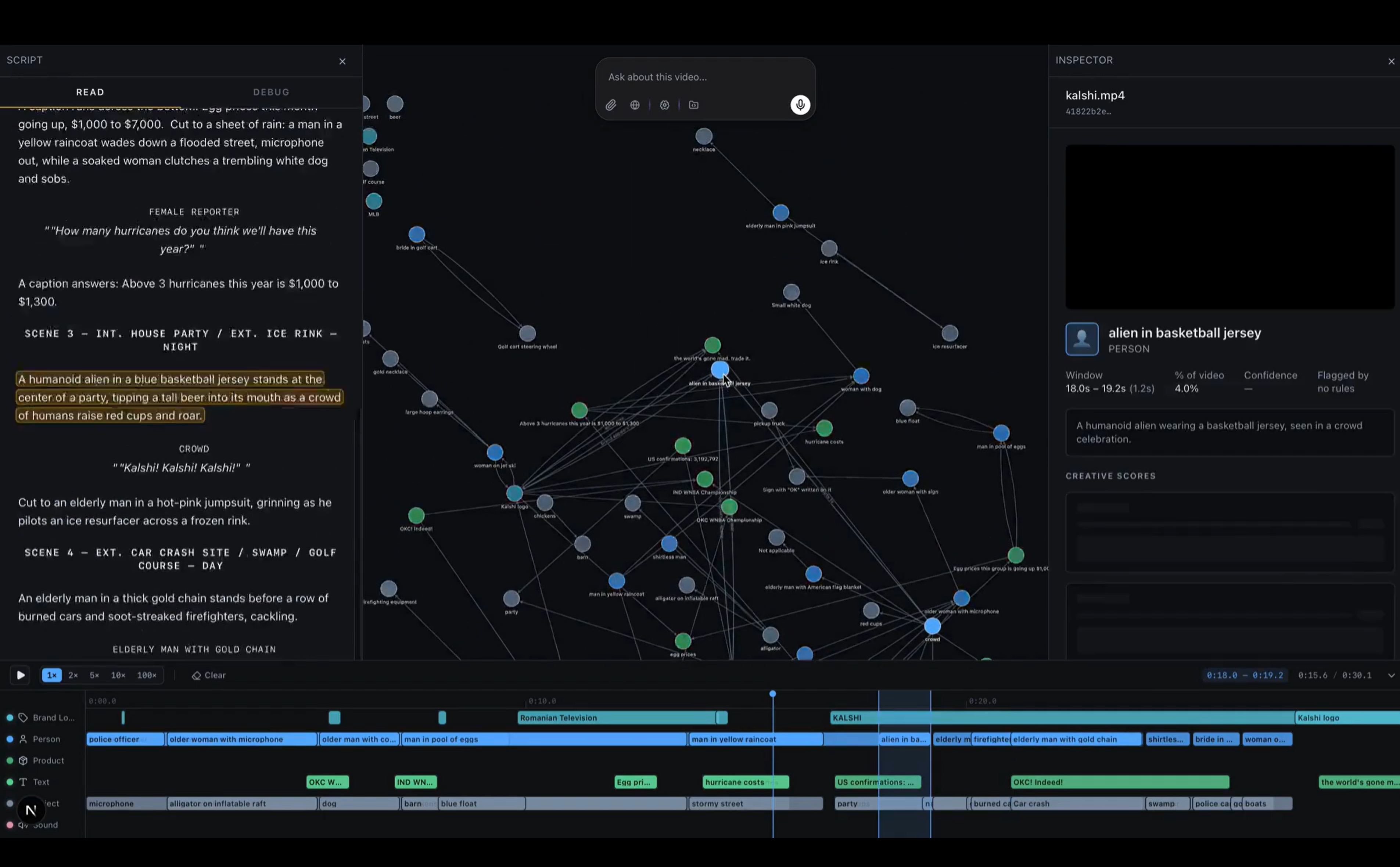
Chiasm is a video ontology editor. You upload a video and it gets indexed into a rich semantic graph of canonical entities with stable IDs, per-shot appearances, relationships, dialogue, and scene composition, All queryable, all browsable as a graph.
The graph is the memory and understanding of the video. Every edit you make feeds back into it. The next edit doesn't start from scratch, it starts from a richer graph than the one before it. The ontology accumulates a knowledge base about the video at hand. On top of that graph, a natural-language editing agent runs a loop that does intelligent iteration and orchestration.
How we built it
our stack starts with a Backend Flask monolith, Supabase for persistence, and Next.js for frontend.
for our agent we use the best of a few worlds, we use Claude for structural reasoning, Gemini for anything that touches pixels and runway aleph gen 4 for in frame edits. Claude Agent SDK runs the planner's tool loop.
our agent has a The three-tier architecture: Perception Gemini VLM breakdown
- Perception: Gemini VLM breakdown
- Decision: A single-shot Claude Opus call with a forced emit_plan tool call.
- Execution: Runway Aleph for replacement, local OpenCV backends for removal, ffmpeg for final assembly with source.
Challenges we ran into
We ran into a few hard problems. The agent was initially pretty problematic. Aleph output fought us on framerate. Runway returns variable-framerate output that looks fine in isolation but judders when concatenated with passthrough shots. We ended up solving this by normalizing everything to 30fps .
Accomplishments that we're proud of
Three big things come to mind beyond a working prototype:
-An LLM that genuinely never touches pixels and a pipeline that still produces frame-accurate edits. The ontology is the interface, end to end.
- The sibling ontology editor. The same agent pattern works for editing the graph as for editing the video. One mental model, two surfaces.
- A visually appealing Cytoscape graph you can read and inspect.
What we learned
What we learned is that specialization matters. Claude handled structural reasoning better, while Gemini was stronger at native video understanding, and combining them produced better results than forcing either model to do both jobs. We also learned that perception is the expensive part, so it should be amortized. Pegasus only needs to run once per video, and later iterations can reuse that cached breakdown, which keeps the editing loop efficient. More broadly, we found that using an ontology is much less intimidating in practice than it sounds.
What's next for Chiasm
Next for Chiasm, the two biggest priorities are adding more edit verbs and giving the planner live tool use. Expanding the verb set with actions like changing attributes, relighting, restyling, and adding objects would make the system far more broadly useful, while live tool use would let the planner request extra perception mid-run instead of failing when context is incomplete. Together, those two upgrades would make the editor both more capable and more flexible.
Built With
- anthropic-sdk
- nextjs
- python
- supabase


Log in or sign up for Devpost to join the conversation.