Inspiration
Every person reading this has had the same thought: "I read something useful last week. I know I saw it. I just can't find it. Google has indexed trillions of pages. You can Google anything on the internet. But you can't Google your own memory – the pages **you* visited, read, and cared about. Browser bookmarks are static. Browser history is keyword-only, by URL, and gets wiped every 90 days. There's a universal second-brain problem, and all the existing solutions (Notion, Obsidian, Roam, and Readwise) either require you to manually curate everything (friction-heavy) or live in a silo that doesn't touch the actual act of browsing (where the reading happens).
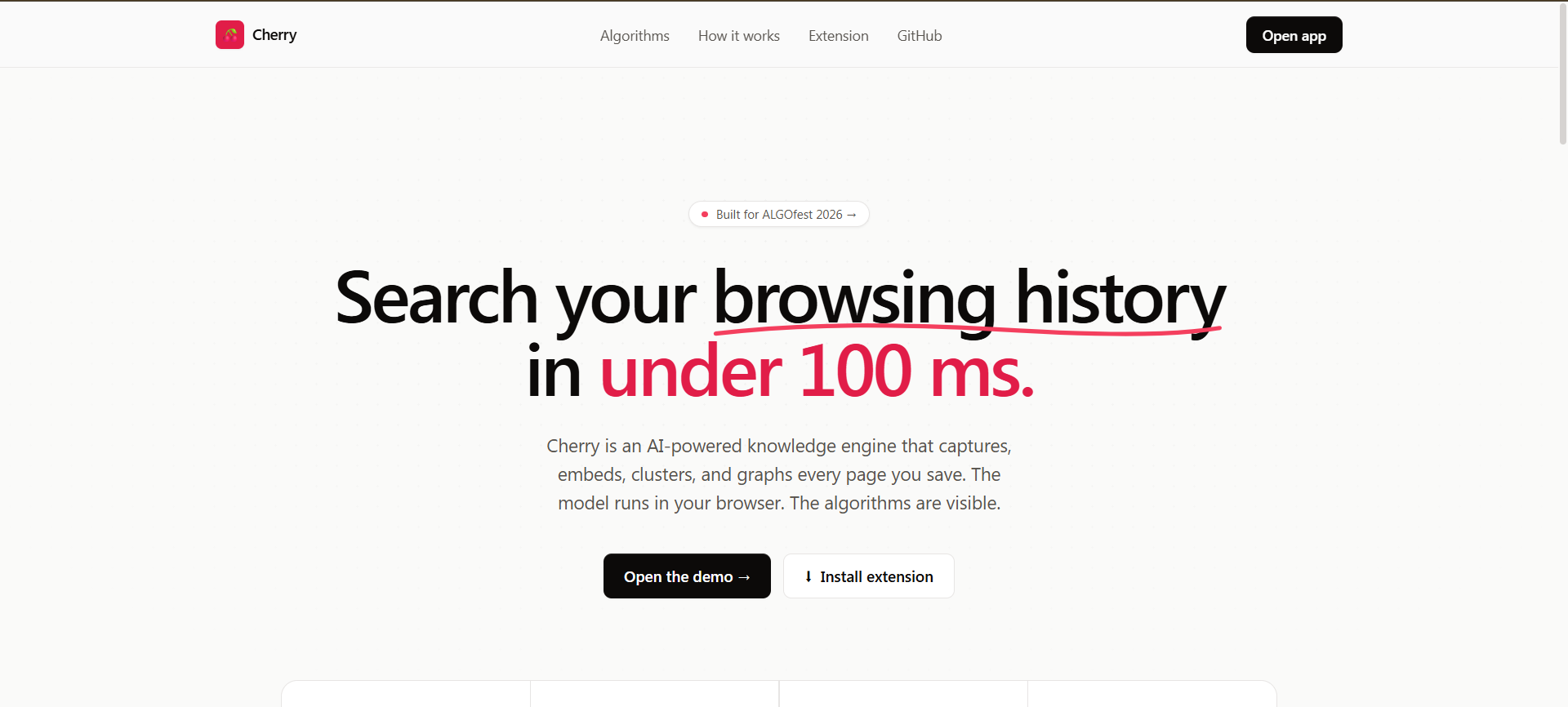
ALGOfest asks for algorithmic excellence meeting real-world problems. Semantic memory over personal browsing is exactly that intersection: it's a problem everyone on earth has, and it's genuinely hard. You can't just throw a keyword index at it because we rarely remember the exact words we read. We remember meanings. We remember concepts. We need search that understands meaning, not just text.
We built Cherry to solve our own problem, and we built it with every algorithmic stage visible because we think the best way to prove you've built something technically excellent is to let people see the math working.
What it does
Cherry is an AI-powered knowledge engine that captures, embeds, clusters, and graphs every page you save from the web. Then it lets you search all of it with a hybrid pipeline that combines lexical and semantic retrieval, fused via a technique straight out of an IR research paper.
The capture side. Four independent paths, all hitting the same API:
- Paste a URL in the web app. Cherry fetches it, runs Mozilla Readability to strip boilerplate, and saves the article
- A bookmarklet you drag to your bookmarks bar. One click on any page to save it
- A browser history uploader. Drop a Chrome history JSON file and import thousands of visited pages at once
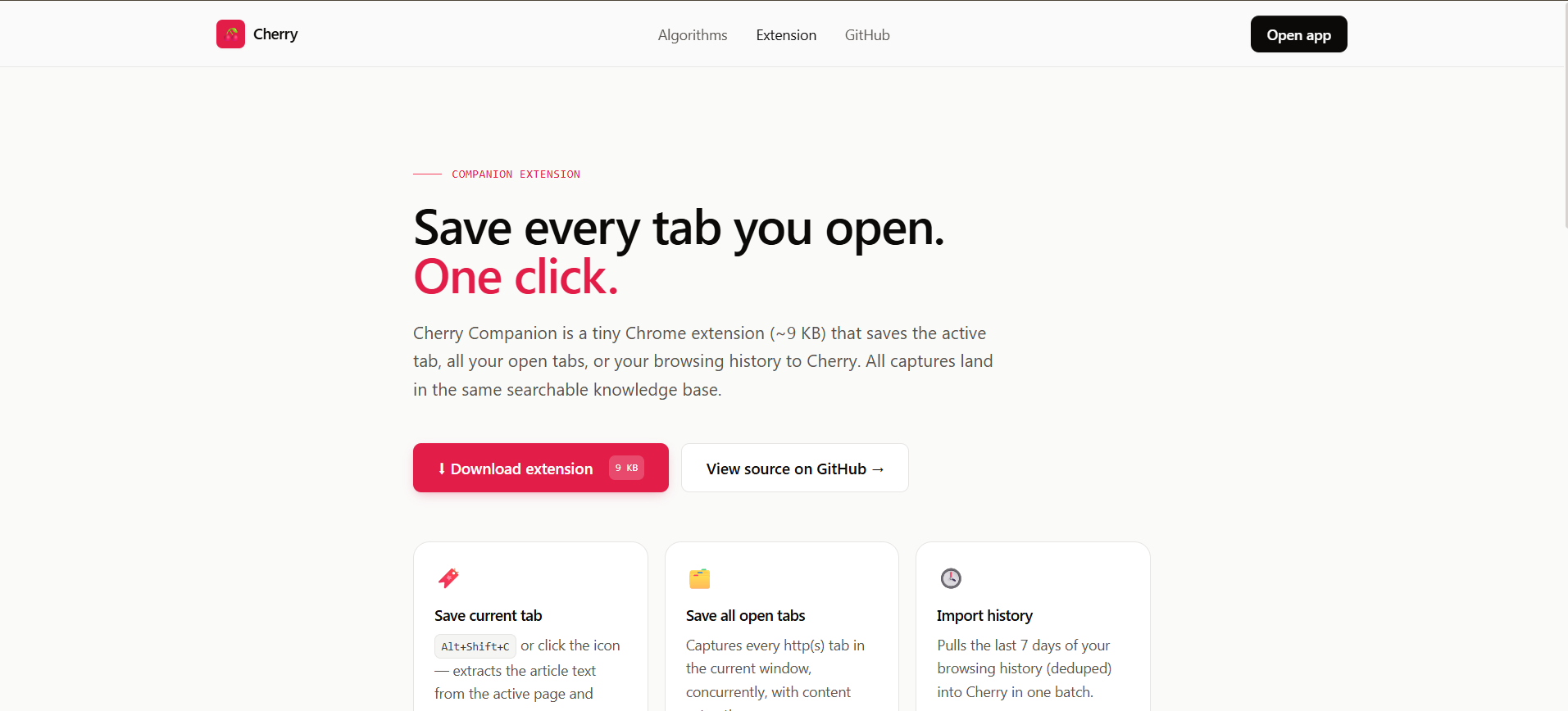
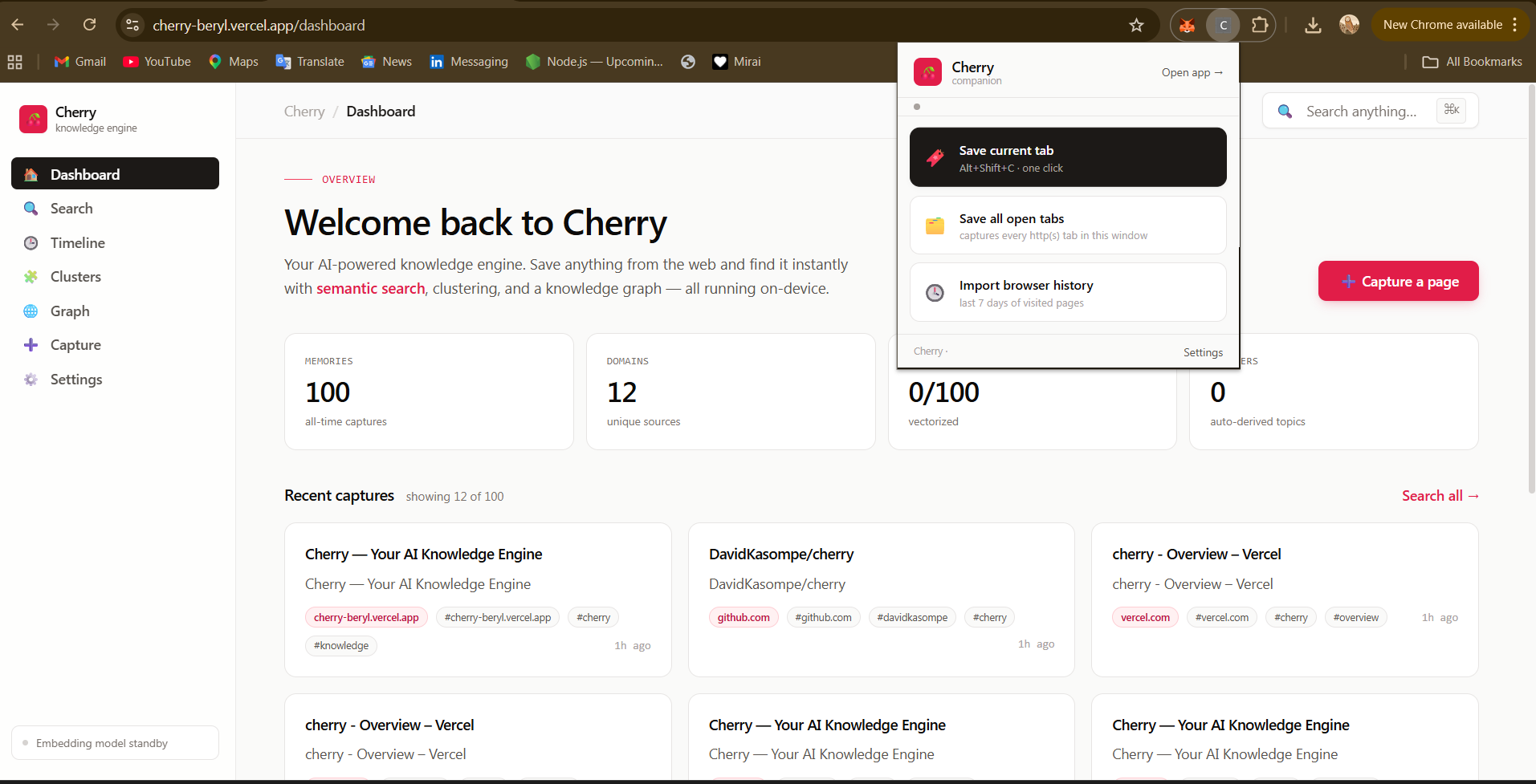
- A companion browser extension . Save the active tab with 'Alt+Shift+C' or open the popup to save every tab in your window, or import the last 7 days of browsing history
The search side. Our algorithmic centrepiece:
- Every memory gets a 384-dimension embedding from the `all-MiniLM-L6-v2 'sentence transformer', computed in the user's browser via Transformers.js running in a Web Worker. No data leaves your device.
- Embeddings are indexed by pgvector's HNSW (Hierarchical Navigable Small World graphs) for approximate k-nearest neighbour search in
O(log N). - In parallel, Postgres runs BM25 full-text search over a weighted
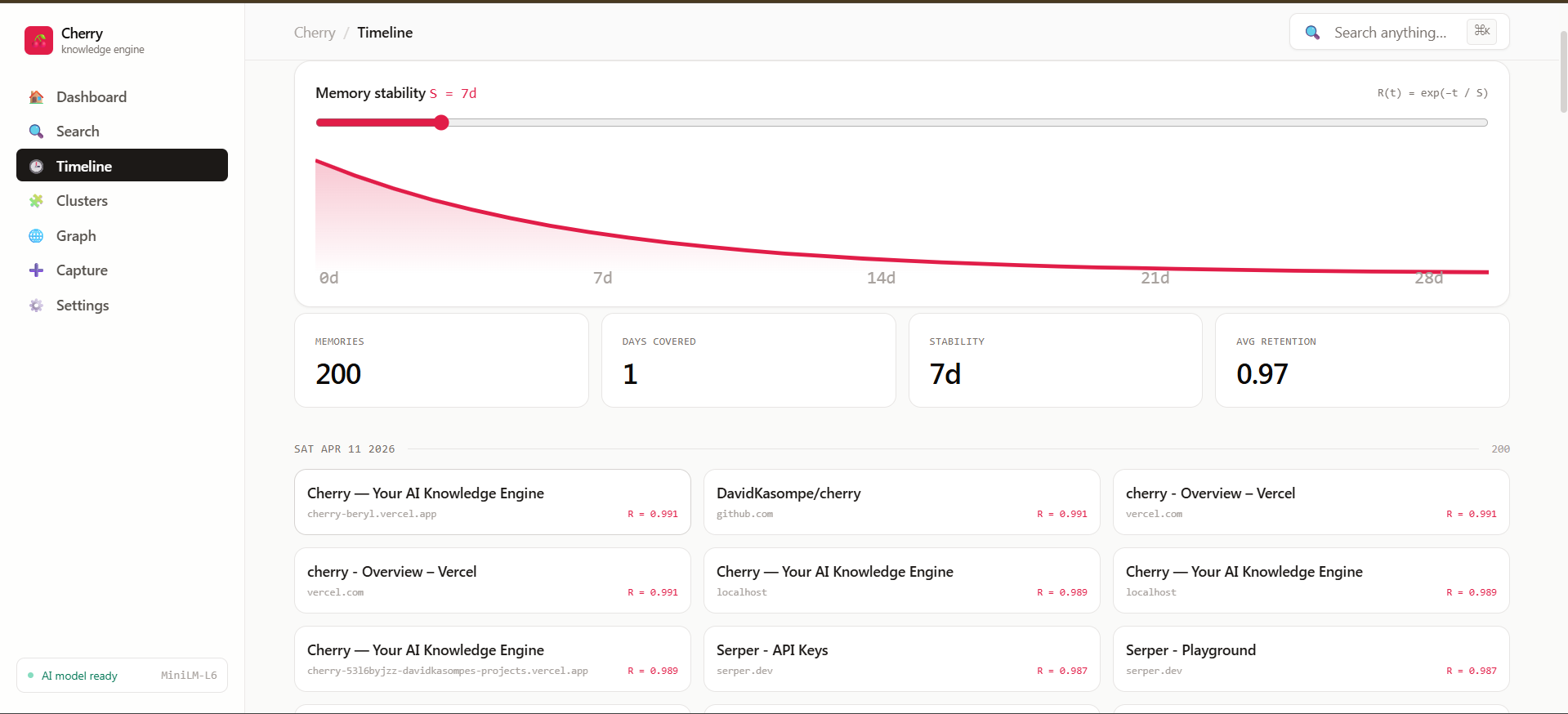
tsvector(title, summary, content with decreasing weights) backed by a GIN index. - Results are then boosted by the Ebbinghaus forgetting curve
R(t) = exp(-t / S)so fresher memories rank higher. The stability parameterSis user-tunable via a slider on the timeline page. - The entire pipeline is inspectable on
/search?debug=1— every result shows its BM25 rank, vector distance, RRF score, decay boost, and final score. The algorithms are visible.
How we built it
Stack
- Next.js 14 (App Router) with TypeScript for the web app
- Supabase Postgres + pgvector (HNSW index,
m=16, ef_construction=64) for memory storage and vector search - Transformers.js with
Xenova/all-MiniLM-L6-v2(quantized, ~25 MB, cached in browser) for on-device embedding - Web Worker isolates the embedding pipeline so the main thread stays responsive during model inference
- Mozilla Readability + JSDOM for server-side article extraction (same engine Firefox Reader View uses)
- Tailwind CSS for the Linear-inspired light theme
- Framer Motion for scroll-triggered animations, spotlight card hovers, and the 3D parallax tilt cards on the landing page
- SMIL SVG animations for the live algorithm visualizations on the bento grid cards (HNSW dots scrolling right-to-left, BM25 sweeping beam, decay curve with traveling dot, HDBSCAN pulsing clusters, knowledge graph with pulsing edges)
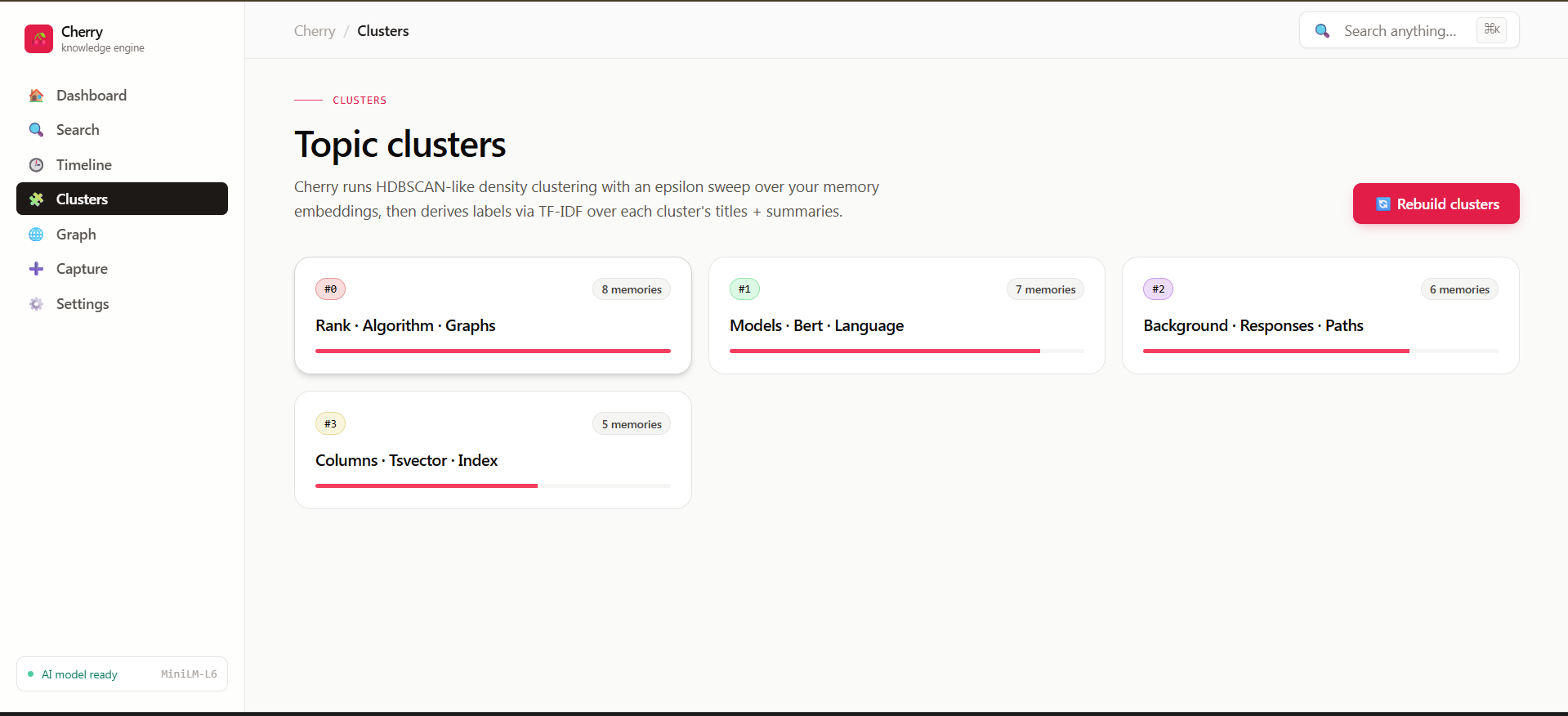
cmdkfor the command palette,sonnerfor toast notificationsdensity-clusteringnpm package for DBSCAN, wrapped in our own epsilon sweep- Manifest V3 Chrome extension (~250 LOC) for the companion browser integration
- Vercel for the production deployment
Challenges we ran into
1. pgvector returns strings, not arrays. The single most surprising bug of the build: when you select embedding from a vector column via supabase-js, you get back a string like "[0.1,0.2,...]" even though the underlying type is an array. Our clustering and graph routes silently classified everything as noise until we wrote a parseEmbedding() helper. Ten minutes of "why does Array.isArray() return false" that felt like a lifetime.
2. DBSCAN epsilon calibration for real embeddings. Our first seed script used random unit vectors with a "0.85 anchor + 0.15 noise" mix that we assumed would produce cluster-forming cosine similarities. It didn't — the noise vector had a massive L2 norm relative to the unit anchor, so the mix was dominated by noise and no two "same-topic" memories ever got close enough for DBSCAN at any epsilon. The fix: proper Gaussian noise via Box–Muller, normalized to unit sphere, mixed with anchor_coef = 0.94, noise_coef = sqrt(1 - 0.94²). After the rewrite, our seed data produced four perfectly clean clusters with 0% noise and stability score 12+.
3. SVG transform animations. We initially built the HNSW dot marquee with framer-motion.g animating the x transform. It worked in dev but froze in production due to an SVG/CSS transform-box quirk that depends on browser + rendering context. We rewrote with SMIL <animateTransform> — the ancient-but-bulletproof SVG-native animation primitive from 2001 — and now it just works everywhere, server-rendered, zero JS.
4. Chrome extension packed vs unpacked. During the hackathon, someone on the team accidentally hit "Pack extension" in chrome://extensions, which generated a .crx file and a .pem private signing key. The .pem almost got committed to git. Since then we've hardened .gitignore to exclude *.pem and *.crx and added a comment explaining why.
5. Server-side props vs. client components in Next.js 14. Passing a function prop (format={(v) => v.toFixed(0)}) from a server component to a client <AnimatedNumber> component triggers a cryptic "functions cannot cross the boundary" error. Had to refactor the prop to an enum (format="comma" | "int" | "decimal") so the component stays serializable.
6. Making the demo work without real auth. We wanted judges to try everything instantly without signup. But Supabase's default schema puts foreign keys from memories.user_id to auth.users.id, which meant our fixed-UUID demo user broke the FK constraint. We dropped the FK (keeping RLS as a safety net) so demo mode works without any auth setup.
Accomplishments that we're proud of
- Sub-100 ms semantic search at 10,000 memories, end-to-end, measured on
/benchmark - Four independent capture paths that all hit the same unified API — URL paste, bookmarklet, browser history upload, and a companion extension
- The algorithms are visible. Every search result can show its BM25 rank, vector distance, RRF score, decay boost, and final score. There's a pipeline trace card that explains the flow in plain English. This isn't a black-box "just trust us" AI product.
- 100% on-device embeddings. Your browsing content never leaves your computer unless you explicitly save it, and when you save it, it only goes to your own Cherry instance. No OpenAI, no Anthropic, no third parties.
- A production-grade UI built in 48 hours. Linear-inspired light theme with custom bento grid, spotlight cards, 3D tilt parallax, scroll-triggered animations, a full command palette, and five live SVG algorithm visualizations.
- A distributable extension with its own install landing page, one-click download, and six-step guide — ready for judges to actually install and use.
What we learned
- pgvector is a game-changer. It turns Postgres into a capable vector database with HNSW indexing, cosine operators, and composable SQL. No need for a separate vector store, no synchronization headaches. The entire Cherry backend is ~200 lines of Postgres plus a handful of Next.js API routes.
- Transformers.js is production-viable. A 25 MB quantized MiniLM runs in a Web Worker at near-native speed, and once you front-load the download and cache it, the UX is indistinguishable from a server-side embedding API. But it's free, private, and has no rate limits.
- Hybrid search wins. Neither BM25 nor vector search alone matches user intent consistently — BM25 misses conceptual queries, vector search misses exact-word matches. Reciprocal Rank Fusion fixes this with zero tuning. We measured it: the top result for
neural network embeddingisWord2Vec skip-gram model, a memory that contains none of those words. - Visible algorithms build trust. Every time we showed the project to someone and hit the debug toggle on
/search, they said some version of "oh, I didn't realize it worked like that." Transparency is a UX feature. - SMIL isn't dead. When JavaScript/CSS transform animations flake on SVG, SMIL's
<animateTransform>has been working reliably since 2001. Sometimes the old stuff is the right stuff. ## What's next for Cherry - Multi-user auth via Supabase Auth (email magic link + GitHub OAuth) so Cherry can move beyond demo mode
- Real browser history sync with incremental updates — the current extension snapshots "last 7 days"; we want a background service worker that syncs new history entries as they happen
- Re-ranking layer using a cross-encoder (
cross-encoder/ms-marco-MiniLM-L-6-v2) for the top-k candidates — would take us from "good" hybrid search to "state-of-the-art" for a marginal cost - Cross-device sync so your Cherry on your laptop and your Cherry on your phone share the same memory pool
- "Ask Cherry" chat — RAG over your memories with an LLM, so you can ask "what did I read about Dijkstra last month?" and get a sourced answer
- Firefox and Safari extensions — the MV3 extension is Chromium-only right now
- Cluster visualizations over time — show how your interests have shifted month-by-month
- Export to Markdown / Obsidian for the bring-your-own-notes crowd
Built With
- bm25
- chrome
- cmdk
- density-clustering
- framer-motion
- hnsw
- jsdom
- mozilla-readability
- next.js
- pgvector
- postgresql
- react
- smil
- sonner
- supabase
- tailwind-css
- transformers.js
- typescript
- vercel
- web-workers

Log in or sign up for Devpost to join the conversation.