-
-

Poster
Title: Sentiment Analysis Who: Adrian Chang : achang57 Virak Pond-Tor : vpondtor Amari Charles : acharle5
Introduction: What problem are you trying to solve and why? Sometimes when we read something we don't know how to feel about it. Therefore we've decided to build a model to tell us how we feel about it. More specifically we are building a neural network that performs sentiment analysis on a body of text that outputs a score determining how positive the sentiment of the text is.
If you are implementing an existing paper, describe the paper’s objectives and why you chose this paper.
https://www.itm-conferences.org/articles/itmconf/pdf/2021/05/itmconf_icacc2021_03032.pdf The paper's objectives were to accurately classify amazon product reviews using user text alongside product details. We chose this paper because it includes additional functionality beyond just the use of RNNs. Specifically, they employ a GNN to aid in the classification task.
If you are doing something new, detail how you arrived at this topic and what motivated you.
N/A
What kind of problem is this? Classification? Regression? Structured prediction? Reinforcement Learning? Unsupervised Learning? etc.
This is a classification problem. If we have time we will try to construct a generative model to create tweets of the inputted sentiment.
Related Work: Are you aware of any, or is there any prior work that you drew on to do your project?
We have heard of sentiment analysis being used to predict stock fluctuations, albeit unsuccessfully and were inspired to create a model that performs sentiment analysis ourselves.
Please read and briefly summarize (no more than one paragraph) at least one paper/article/blog relevant to your topic beyond the paper you are re-implementing/novel idea you are researching. In this section, also include URLs to any public implementations you find of the paper you’re trying to implement. Please keep this as a “living list”--if you stumble across a new implementation later down the line, add it to this list.
https://www.tensorflow.org/text/tutorials/text_classification_rnn#setup This tensorflow tutorial walks through how to train an LSTM to classify text data. It covers creation of the text encoder, training the model with a validation set, and stacking LSTM layers. It also covers the use of bidirectional LSTMs and how it affects training.
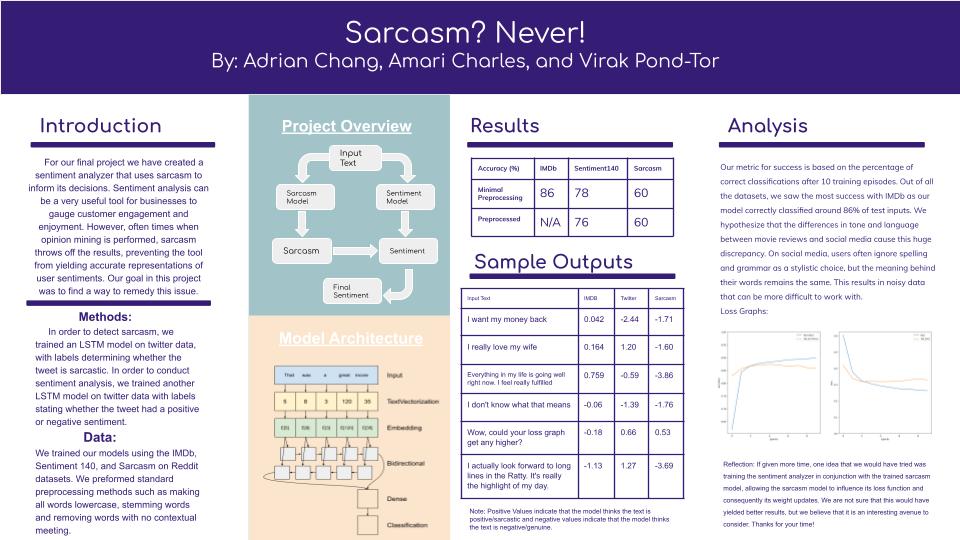
Data: What data are you using (if any)? If you’re using a standard dataset (e.g. MNIST), you can just mention that briefly. Otherwise, say something more about where your data come from (especially if there’s anything interesting about how you will gather it).
We are using Sentiment140, a dataset of 1.6 million tweets that comes with labels ranging from 1-4 describing the sentiment of the text.
How big is it? Will you need to do significant preprocessing? 1.6 million tweets. We will not need to do significant preprocessing.
Methodology: What is the architecture of your model?
We are planning to use an LSTM to classify our data.
How are you training the model?
We are training the model in tensorflow using backpropagation and SGD.
If you are implementing an existing paper, detail what you think will be the hardest part about implementing the model here.
We believe that trying to solve the same classification problem using a GNN will be the hardest part of implementing the model.
If you are doing something new, justify your design. Also note some backup ideas you may have to experiment with if you run into issues.
N/A
Metrics: What constitutes “success?”
Success is determined by the rate of correct classifications and a qualitative (subjective) test as to whether or not our generated texts match our notions of what happy or sad texts are.
What experiments do you plan to run?
We plan on testing the data with the testing set and also giving text to our model.
For most of our assignments, we have looked at the accuracy of the model. Does the notion of “accuracy” apply for your project, or is some other metric more appropriate?
The notion of accuracy does apply to our project. If our prediction is the correct label we can consider it a correct response allowing us to easily get an estimate of our model's accuracy.
If you are implementing an existing project, detail what the authors of that paper were hoping to find and how they quantified the results of their model.
N/A
If you are doing something new, explain how you will assess your model’s performance.
Accuracy
What are your base, target, and stretch goals?
Base: Model that classifies text accurately (> 65% accuracy) with visualization methods Target: Twitter bot that works in conjunction and also uses other types of models other than RNNs Stretch: Generative model that takes sentiment into account.
Ethics: Choose 2 of the following bullet points to discuss; not all questions will be relevant to all projects so try to pick questions where there’s interesting engagement with your project. (Remember that there’s not necessarily an ethical/unethical binary; rather, we want to encourage you to think critically about your problem setup.)
What broader societal issues are relevant to your chosen problem space?
This model might be used to evaluate popular consensus over a specific issue or current event. This can go on to affect decision making of those who choose to believe in the model's accuracy. It also perpetuates the beliefs of the subset of the population who tweets.
Why is Deep Learning a good approach to this problem?
Sentiment analysis of an arbitrary text is a difficult problem to solve with linear models and human designed programs because of the complexity associated with natural language. Deep learning can abstract many of the issues related to under-fitting this classification problem.
What is your dataset? Are there any concerns about how it was collected, or labeled? Is it representative? What kind of underlying historical or societal biases might it contain? Who are the major “stakeholders” in this problem, and what are the consequences of mistakes made by your algorithm?
How are you planning to quantify or measure error or success? What implications does your quantification have?
We plan on measuring error and success by loss and accuracy alongside qualitative assessment. The implication is that language is quantifiable on a scale, when many statements are not necessarily good or bad.
Add your own: if there is an issue about your algorithm you would like to discuss or explain further, feel free to do so. Division of labor: Briefly outline who will be responsible for which part(s) of the project. Adrian - Model design Amari - Visualization methods Virak - Hyperparameter tuning

Log in or sign up for Devpost to join the conversation.