-
-

Schema of ideas for the project, which were finalized and implemented.
-

Extension Home Page
-
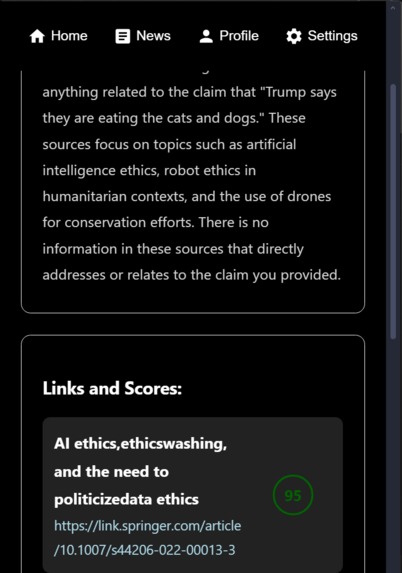
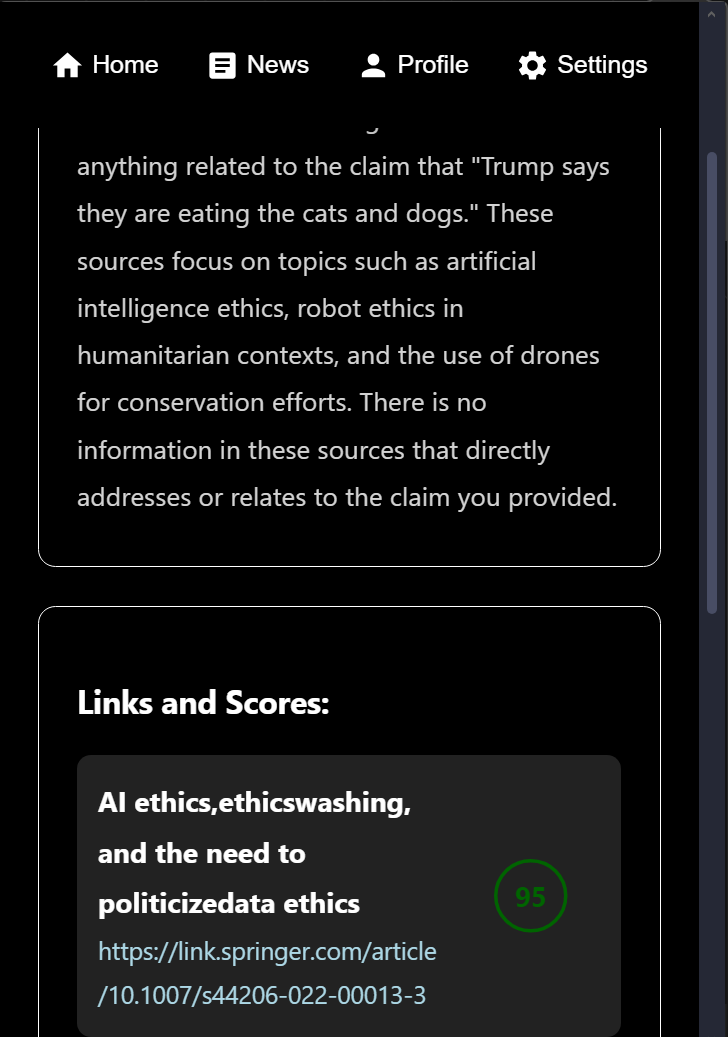
Result Page
-
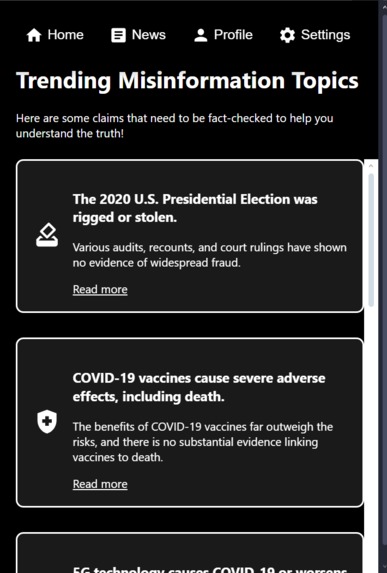
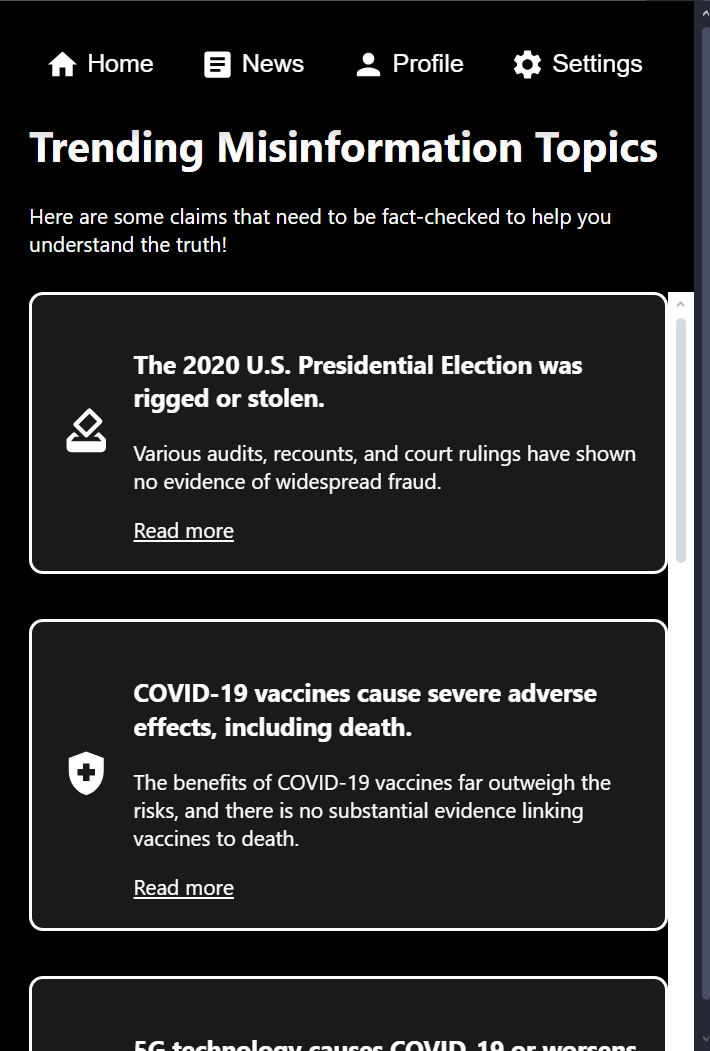
Trending News Page


Inspiration
Today, dis/misinformation has become a rampant issue plaguing online communities. Be it a bad actor spreading malicious lies or an influencer innocently misunderstanding the topic they discuss, it's never been easier to spread false information over such a large network. This error in digital communication translates into real-world issues that affect our lives, communities, and our democracy. Recent polls have shown growing belief in conspiracy theories, rising polarization, and a growing divide between Americans. How can a democracy function if its citizens can’t even agree on the basic details of reality? That’s why our team has invented an software that can help fight this growing issue both domestically and abroad.
What it does
After the user types a claim to check in our Google Chrome Checkr extension and presses the run button, our program returns a paragraph overview of available sources and several relevant articles related to the topic to the user, each with a confidence score from 0-100 that indicates how confident Checkr is in the legitimacy of each source. Internally, after the user entered a claim, it would filter through a quarry prompt, through which our BERT model finds the top 3 most compatible sources which then passes these sources along to our locally run DeepSeek server to repackage the information to the user in the extension, providing source reliability scores.
How we built it
For the frontend, we used React.js styled with scss to display our project, which was on a Chrome extension. On the frontend included the prompt that the user would enter, as well as the response from our program. For backend, we first used Beautiful Soup to create a web scraper to fill our database with links to research and news publishings. The url, title, and entire face text of the sources were then stored in an SQLite database, which also stored the prompts from the user interface. We used BERT to compare sources with the original prompt, and give a compatibility score from 0-100. Deepseek was then used to summarize these sources, address the prompt, and provide the sources as clickable links.
Challenges we ran into
We ran into challenges with getting the Google Chrome extension format to appear as we wanted to. Additionally, we ran into problems with our web scraper and extracting pdfs, as we were unable to save pdfs of articles into a file that could be stored in a database, and instead opted to save website urls, as well as their entire text contents into a database. We additionally faced issues with integration of backend and frontend, and went through countless rounds of debugging to fix. We ran into lots of formatting issues with json and links for accessing our back end sending information to our front end. We also had to change our polling method for listening for the response from our back end on on front end.
Accomplishments that we're proud of
We took pride in creating a working program, built by a cohesive team that cooperated and communicated well with each other. Our team consistently checked in with each other, updating each other on our progress and discussing solutions to roadblocks. After hours of teamwork and determination, we were able to produce a polished interface that is connected with our backend. Additionally, we’re proud of being able to grow in our understanding of tools such as web scrapers, and be able to create databases, and vector conversions to swiftly compare large quantities of strings. We are proud that we were able to not only build several applications within Django but link them all together neatly that properly communicates with our front end.
What we learned
We became familiar with working with web scrapers, which was a new topic for many of us. We learned how to manage BERT, one of the newest vector programs used in Natural language processing, as well as integrating backend and frontend together. The difficult lesson of how to “kill our darlings” was fully realized during this project, as we had to scrap hours of work, realizing that it didn’t fit the value of our project. Additionally, we learned the importance of proper communication to ensure cooperation. Talking out our individual roles revealed initial miscommunication of intentions, and led to programs being changed or completely replaced. For many of us was our first time working with Django, Ollama, and DeepSeek, all tools we are now comfortable with.
What's next for Checkr
In the future, we want to increase the variety of sources and topics included in our database. We also hope to implement Checkr with popular social media platforms like Instagram, X, and facebook for ease of use. Ideally, this project would expand to function with videos and images, and be able to flag falsehoods and educate the user on the context of certain circumstances. As this is a project mainly based in the US, we will work to combat bias towards a certain country or population by expanding globally.









Log in or sign up for Devpost to join the conversation.