-
-

Enter a Devpost URL
-
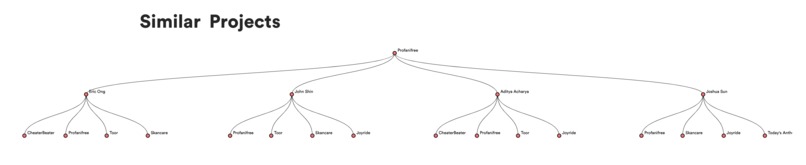
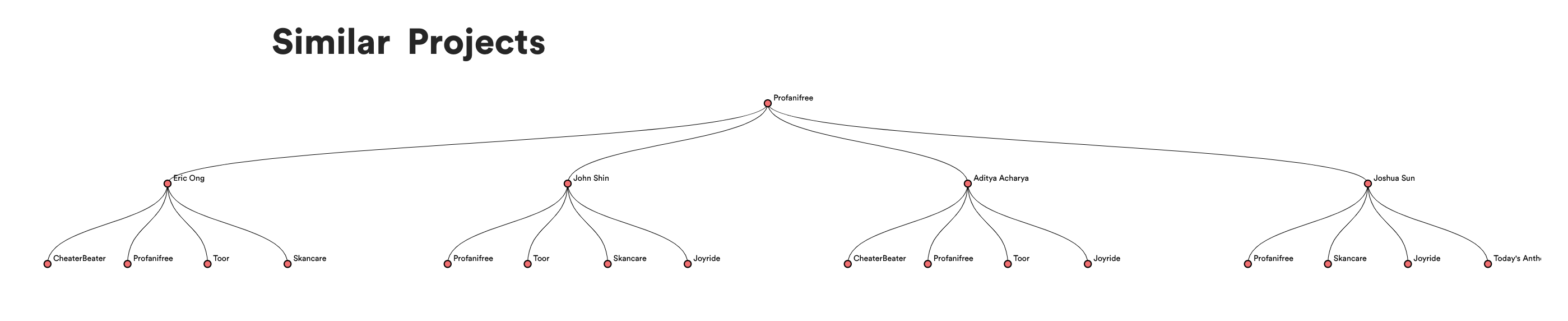
See what other projects were related
-
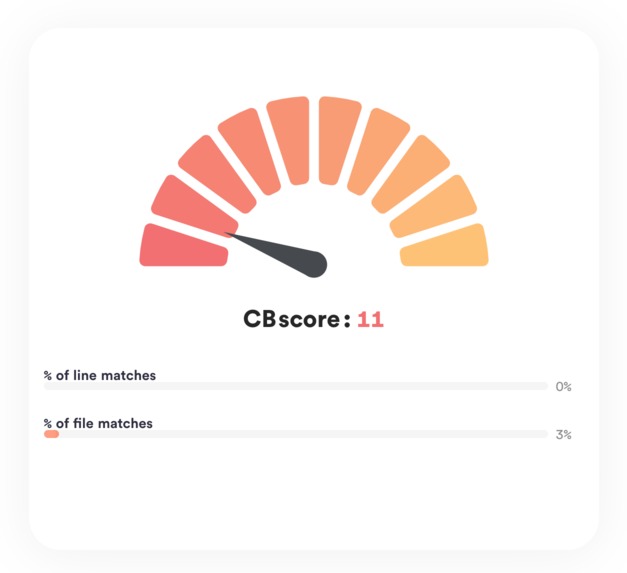
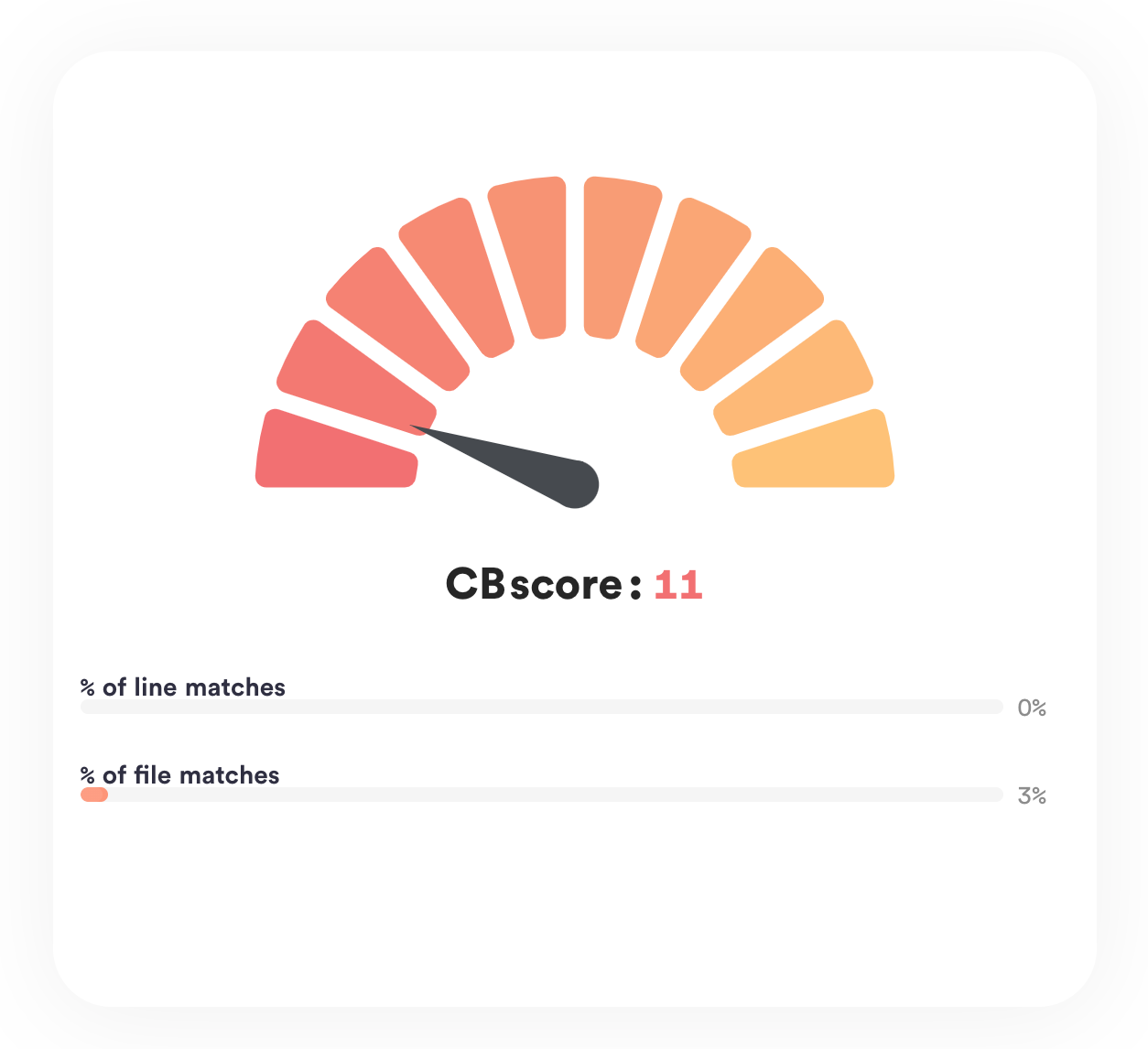
See how well the project performed
-

If the project passes, then it's good to go!
-

Identify certain areas where code may have been taken from


Cheater Beater
Cheater Beater is a full-stack web app that uses Devpost submissions and GitHub to detect hackathon submission fraud. Our goal is not to make a statement about whether or not cheating occurred, but is rather to flag hackathon submissions where a closer look is warranted.
Our inspiration
As a judge, you find a project that just blows you away, fight hard for it in the judging room and award it first prize. However, later, after it's too late, you realize that this group has submitted the same project (maybe with some minor changes) at a previous hackathon!
As veteran hackers and veteran hackathon organizers, we have run into this situation multiple times and wanted to find a solution to this issue. By outsourcing the code analysis to our application, we feel that judges will have more time to spend on deciding what the best project was rather than having to figure out if the projects are legitimate or not.
What we learned
We learned about about different file diff algorithms, as well as how to work with and clone Git repos. We also learned about the syntax of .gitignore files and how to apply them to non-Git applications. Finally, we researched about how to use simhashes with approximate nearest-neighbor search to find related files efficiently. Although we started an implementation of this step, we were not able to fully integrate it in the final revision.
How we built it
The frontend is written using React, and the backend uses Express.js. The application is hosted on Google Cloud Platform and uses 3 main services:
- Google Cloud Buckets for hosting the frontend
- Google Compute Engine for hosting the backend
- Google Memorystore to cache requests
We get the Devpost information by scraping submissions using Cheerio.js.
Challenges we faced
From scraping to hashing, the breadth and scope of our project introduced many challenges. It was especially challenging to to efficiently compare the code of the repository while ensuring transparency and fairness in the evaluation of a project. We also found it difficult to scrape Devpost and determine what information was required and where inside the webpage it was located.











Log in or sign up for Devpost to join the conversation.