-
-
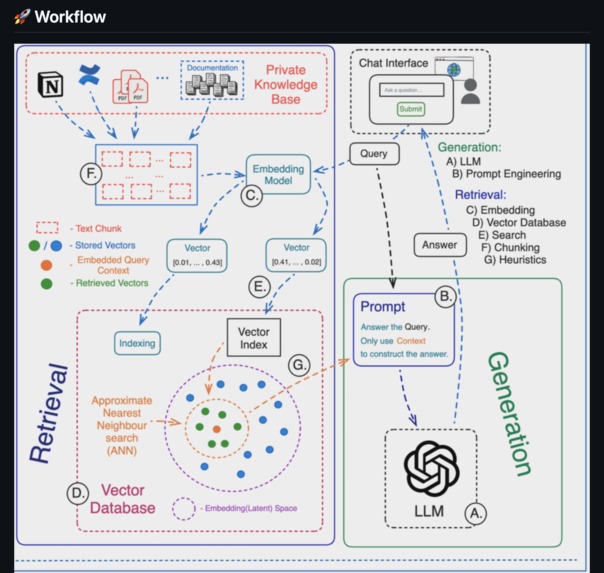
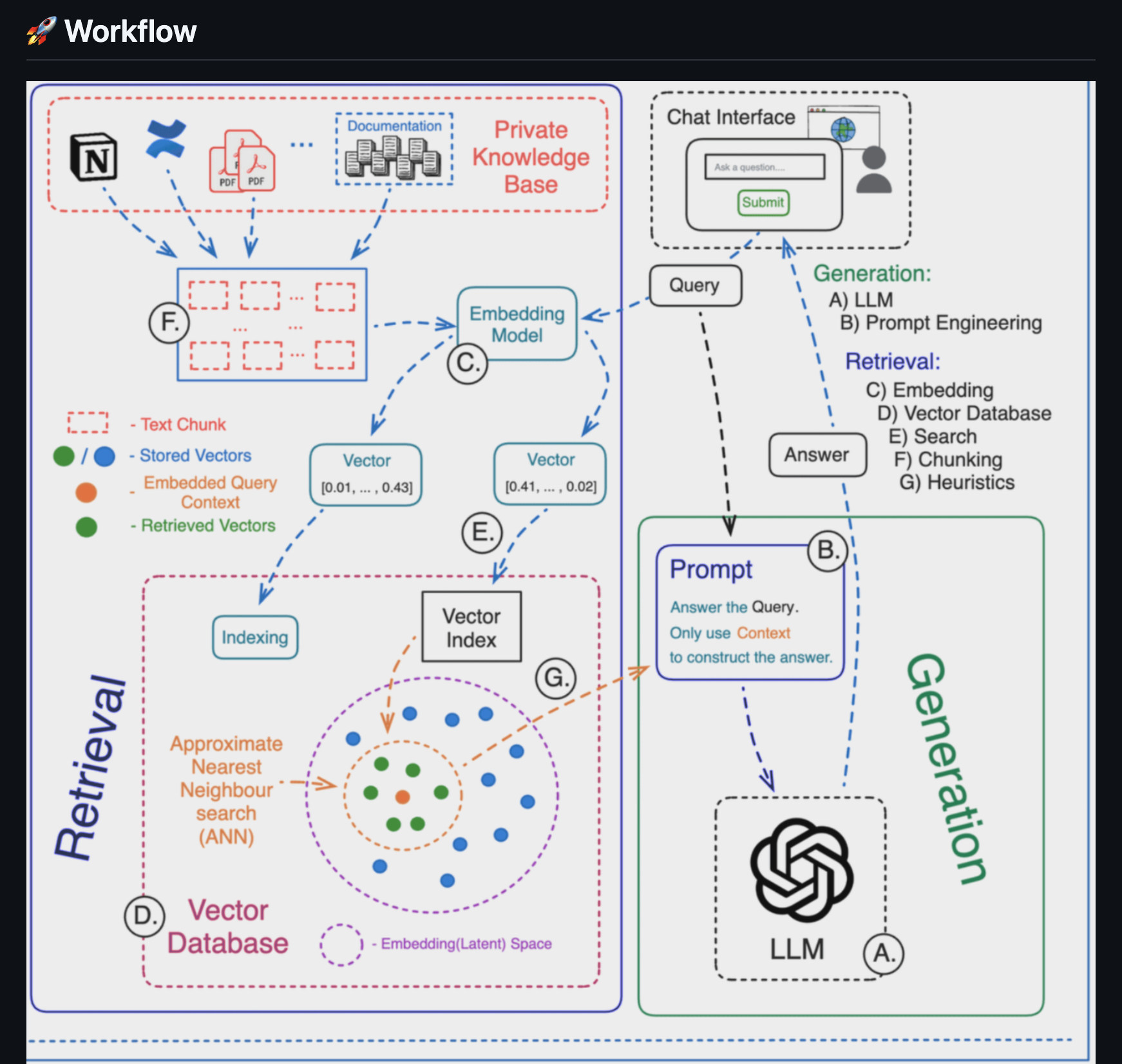
Workflow
About the Project
Inspiration
The inspiration came from a common problem: searching through large documents is time-consuming and frustrating. I wanted to build something that could instantly understand and retrieve the right information, instead of making people manually scan through pages. That’s where Retrieval-Augmented Generation (RAG) felt like the perfect solution.
What I Learned
- How RAG pipelines combine vector databases and LLMs to deliver context-aware answers.
- The importance of prompt engineering for better accuracy.
- Handling unstructured data and converting it into embeddings for fast retrieval.
- Deployment strategies to make the system scalable and user-friendly.
How I Built It
- Preprocessed documents into chunks and generated embeddings.
- Stored embeddings in a vector database for quick retrieval.
- Integrated an LLM with the retrieval pipeline to provide context-based answers.
- Built a simple UI where users can upload documents and ask natural language questions.
Challenges
- Ensuring accurate answers without hallucinations.
- Optimizing embedding size and retrieval speed.
- Balancing between cost and performance while using APIs.
- Creating a user-friendly interface that feels intuitive.

Log in or sign up for Devpost to join the conversation.