-
-
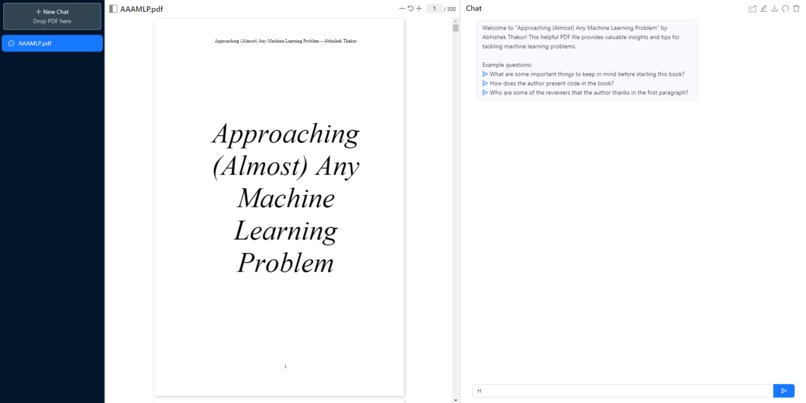
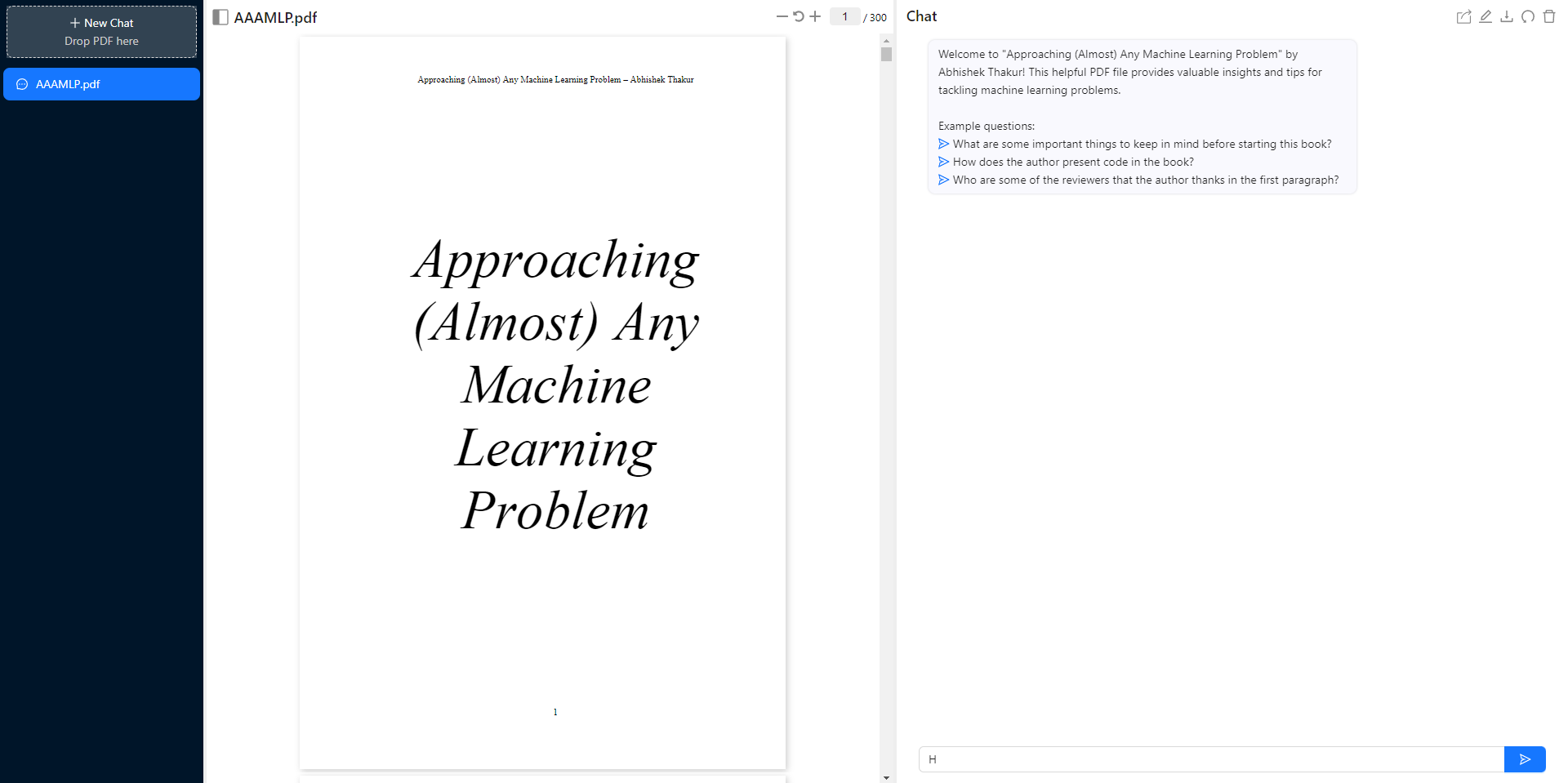
Chat Page
-
Homepage
-
Uploading PDF
-
Landing page
Inspiration
My project was inspired by the need for a decentralized and efficient way to store and retrieve information, particularly PDF documents, in a chat application. I learned about the power of combining emerging technologies like IPFS for decentralized file storage, ChromaDB for vector storage, and Hugging Face models for text embeddings.
To build this project, I first integrated IPFS to store PDFs, ensuring data immutability and accessibility. I used ChromaDB to create embeddings from the PDFs, allowing for efficient similarity searches. Hugging Face's models were employed to generate embeddings for user queries and to match them against stored vectors.
Challenges arose in optimizing the performance of vector storage and retrieval, ensuring fast response times in a chat environment. Scaling the system for large volumes of documents and user queries also proved challenging.
Ultimately, this project demonstrates the potential of decentralized technology to enhance chat applications, offering a secure and efficient way to store and retrieve PDFs while enabling meaningful interactions based on content similarity.
What it does
PDF Storage with IPFS (InterPlanetary File System): IPFS is used to store PDF documents in a decentralized and distributed manner. It ensures data immutability and availability by splitting files into smaller chunks and distributing them across a network of nodes. Users can upload and access PDFs through the chat application.
Vector Storage with ChromaDB: ChromaDB is used to create and manage vector representations of the PDF documents. Vectors are numerical representations of the content, which can be used for efficient similarity searches and comparisons.
Hugging Face Models for Text Embeddings: Hugging Face models are employed to generate embeddings for both the PDF documents and user queries. Embeddings are dense numerical representations of text that capture semantic meaning. These embeddings are used to compare user queries with the stored vectors of PDF documents.
Query Response: When a user submits a query, the system generates an embedding for the query text and matches it against the embeddings of stored PDFs. It retrieves and presents PDF documents with similar content or relevant information as query responses.
How we built it
I have developed a cutting-edge project using a powerful stack of technologies. This project leverages Next.js for the frontend, Drizzle as the database, IPFS for decentralized PDF data storage, Hugging Face models to generate text embeddings, and ChromaDB to efficiently store these vector embeddings.
Next.js provides a dynamic and highly responsive frontend, offering an engaging user interface for seamless interactions.
Drizzle serves as our robust database solution, ensuring data integrity and accessibility for all users of the application.
IPFS revolutionizes document storage by distributing PDF data across a decentralized network, enhancing data security and availability.
Hugging Face models play a pivotal role in understanding and processing textual content. They generate embeddings, enabling content-based similarity searches.
ChromaDB efficiently stores these embeddings, facilitating swift and accurate retrieval of related documents.
What we learned
During this project, I've embarked on a fascinating journey of learning and discovery, delving into the world of Hugging Face models and AI technology. Here's what I've learned:
Natural Language Processing (NLP): I've gained a deep understanding of NLP, a branch of AI focused on the interaction between computers and human language. Hugging Face models are at the forefront of NLP, enabling various language-related tasks like text generation, sentiment analysis, and text embeddings.
Embeddings: I've grasped the concept of embeddings, which are numerical representations of words or text. Hugging Face models, such as transformer models, use embeddings to encode the semantic meaning of words or sentences into dense vectors. These vectors capture relationships between words and allow for meaningful comparisons.
Transfer Learning: I've learned about the power of transfer learning, where pre-trained models like BERT, GPT, and others are fine-tuned for specific tasks. This approach significantly speeds up model development and enhances performance.
Semantic Similarity: I've explored how embeddings can be used to measure semantic similarity between text elements. This knowledge has been crucial in building a system that can understand the content of PDF documents and match it to user queries.
Built With
- ai
- chroma
- drizzle
- huggingface
- ipfs
- nextjs
- vercel-sdk

Log in or sign up for Devpost to join the conversation.