-
-
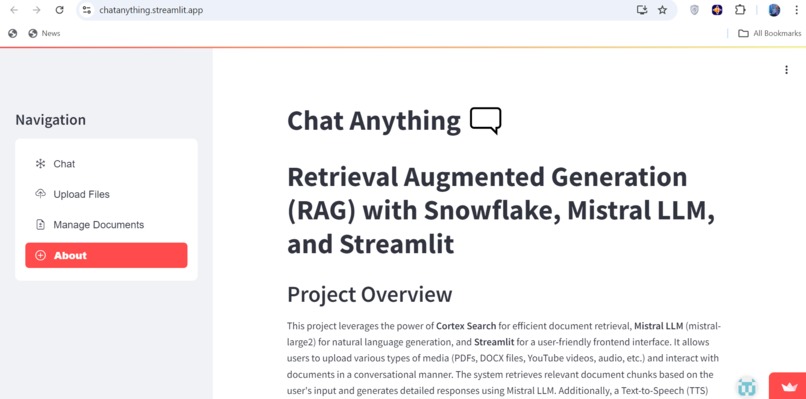
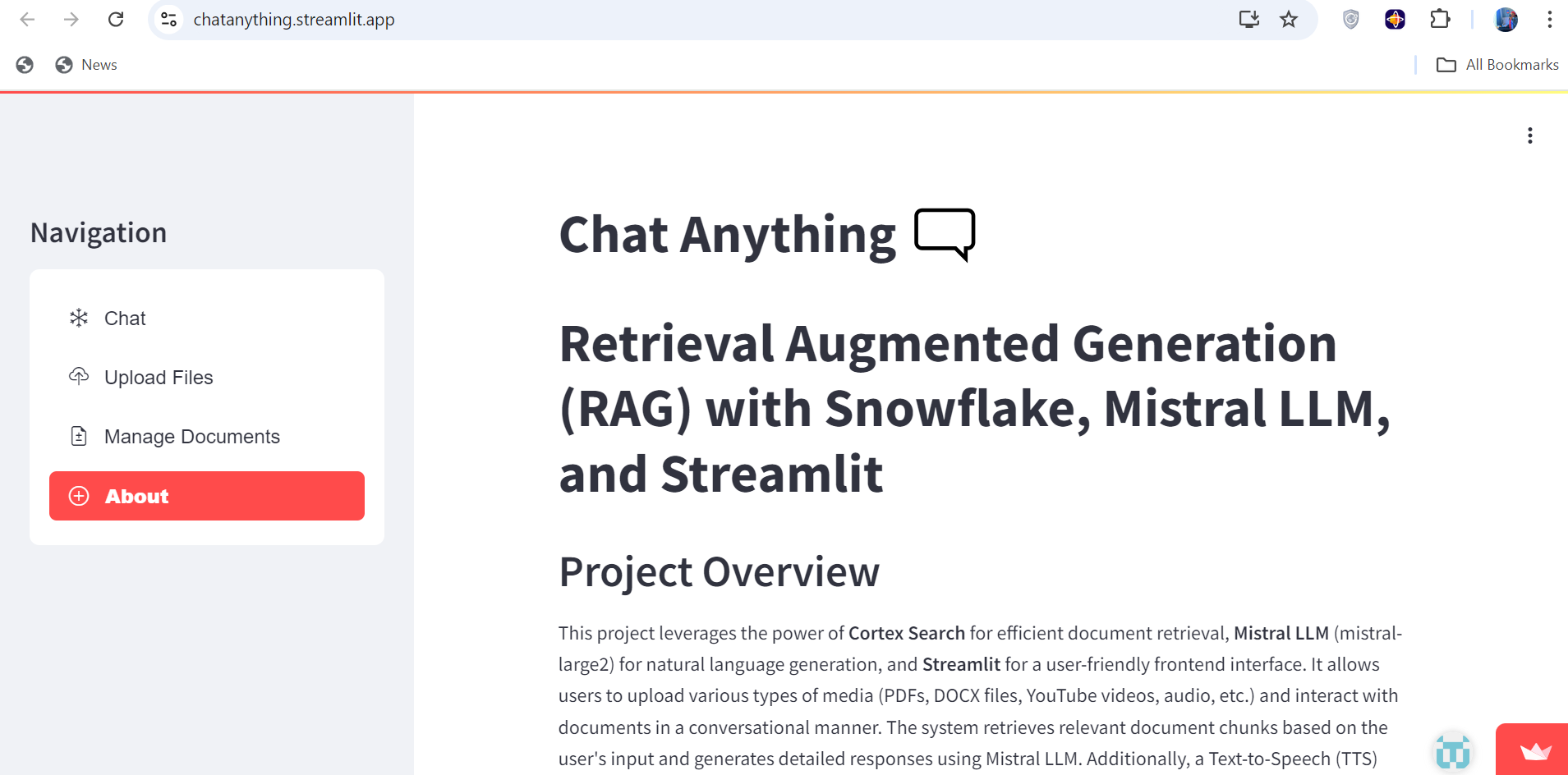
About the project
-
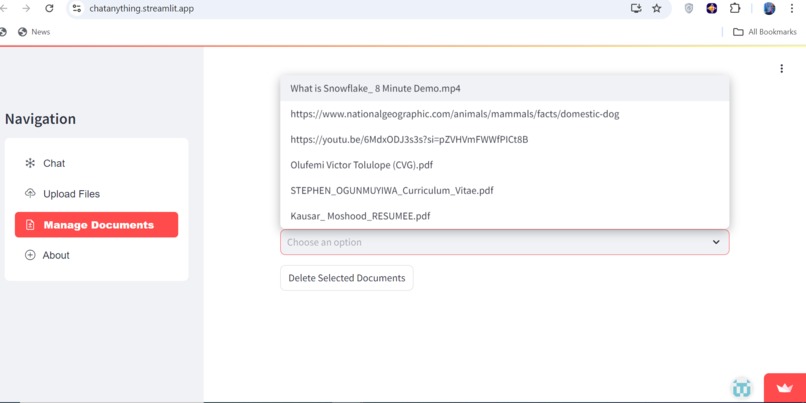
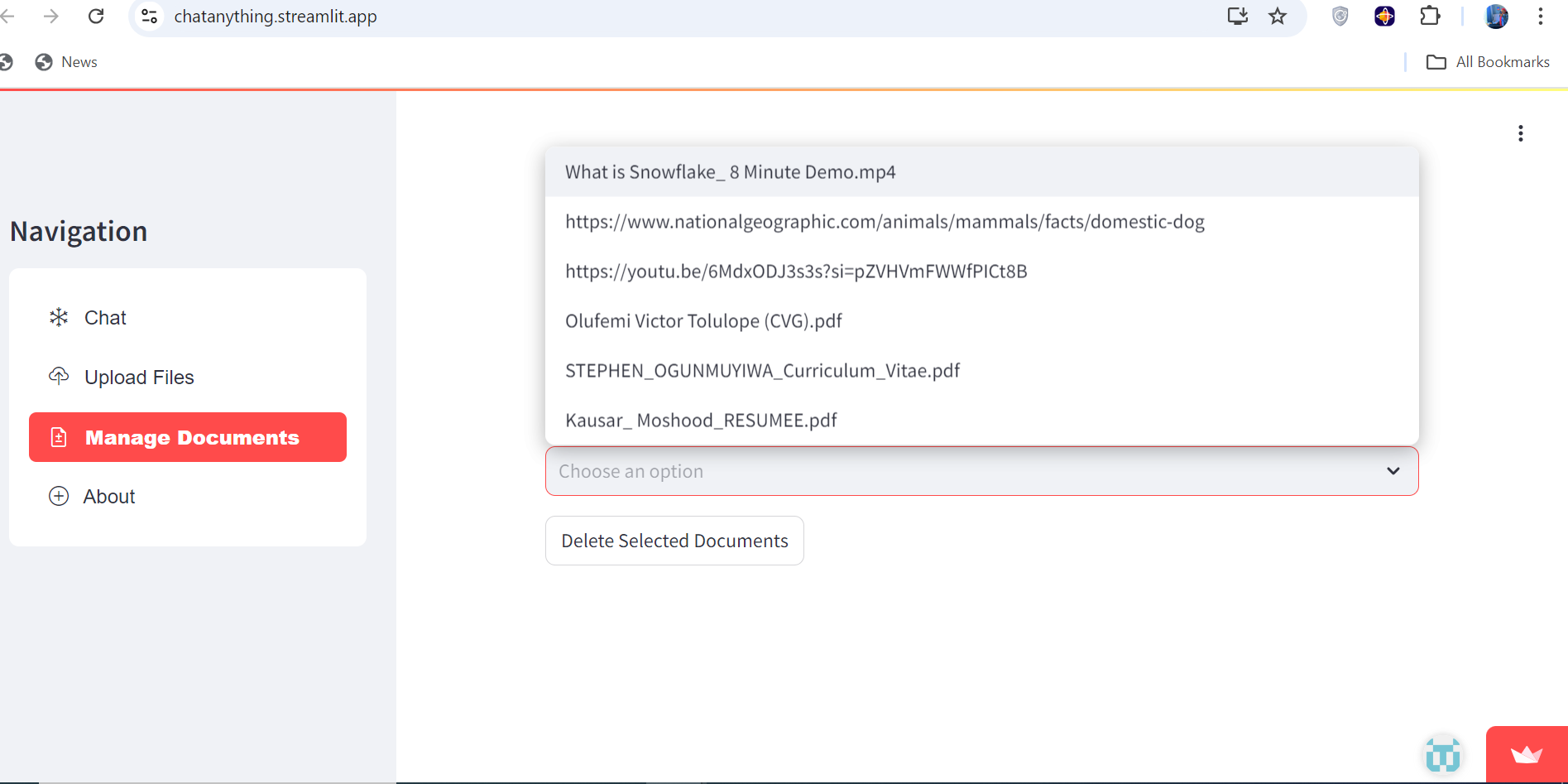
You can manage the documents uploaded
-
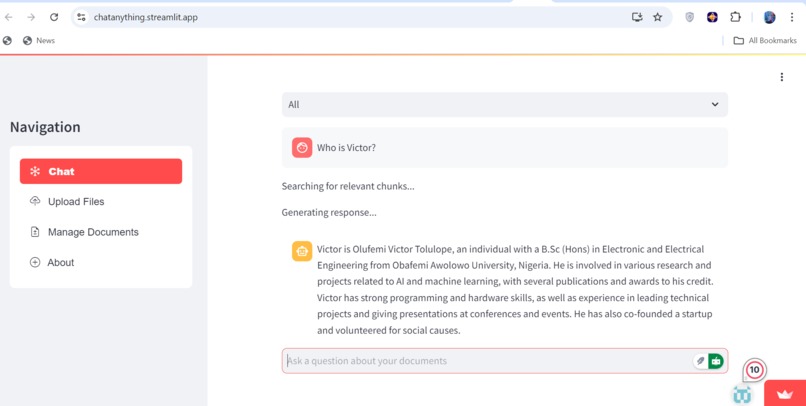
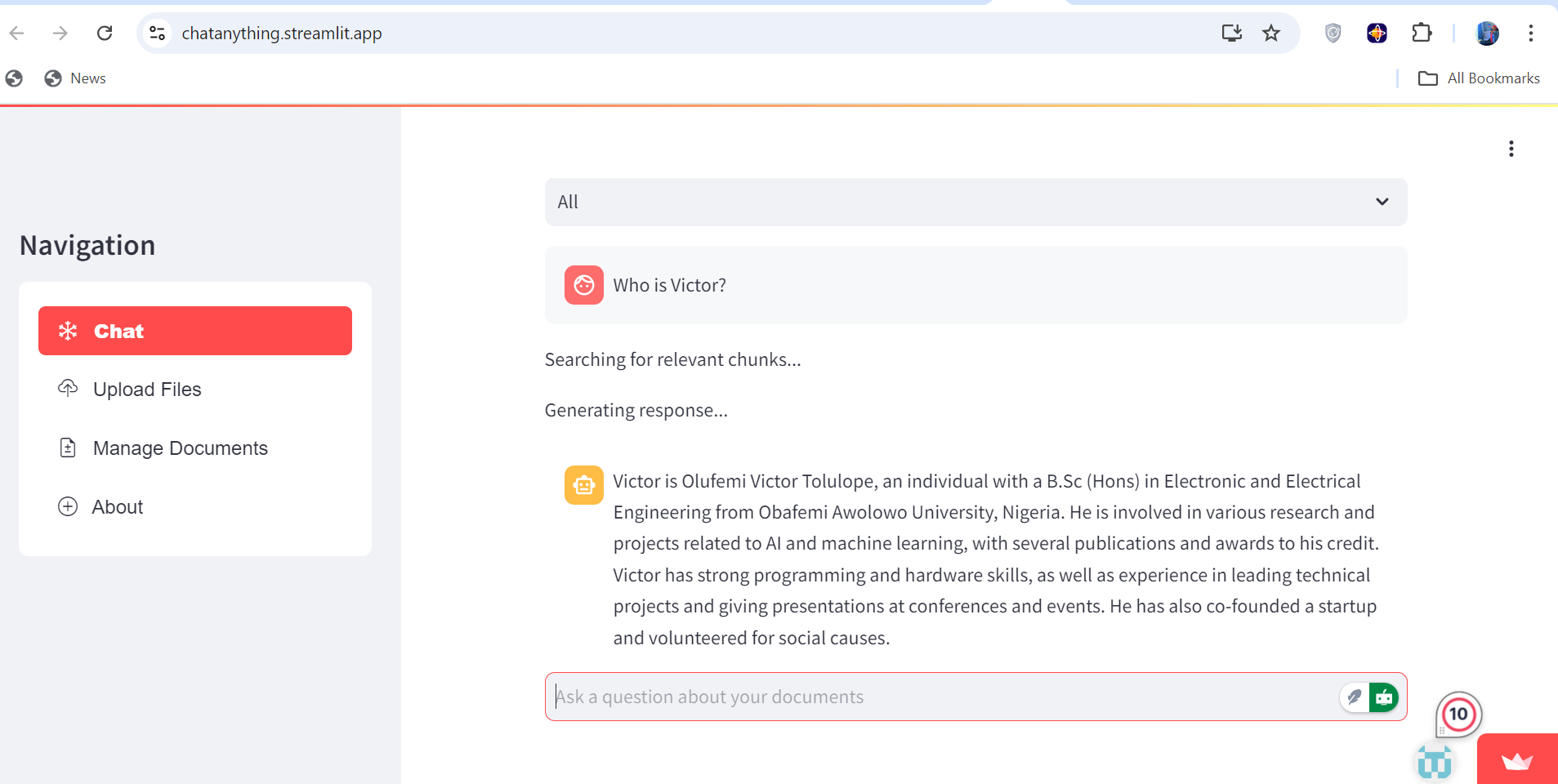
Get to chat about any of your uploaded file
-
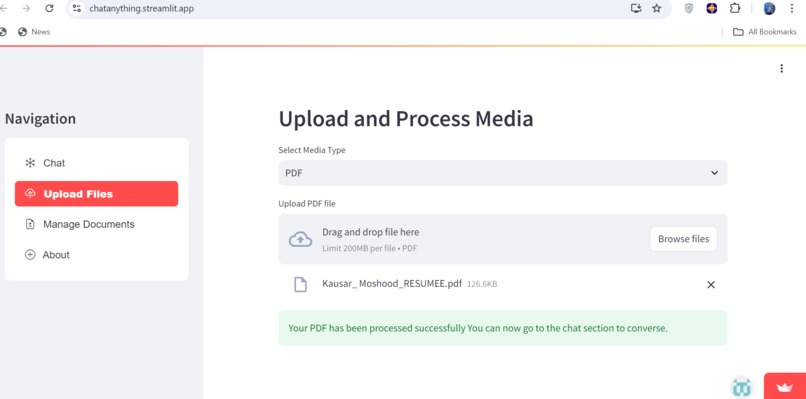
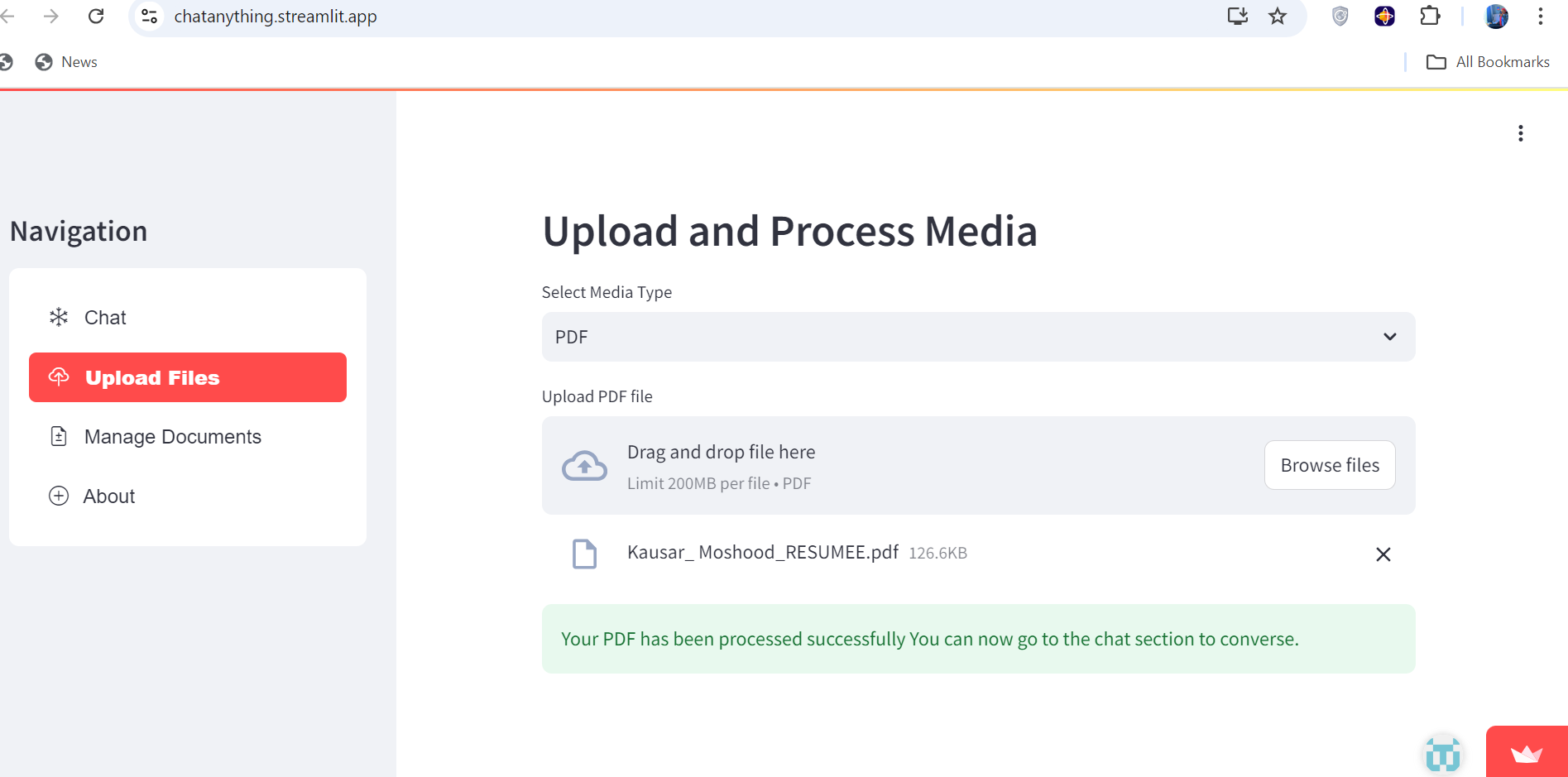
You can upload PDF, DOCX, TXT ,YouTube,Web URL, Audio Video files
Inspiration
The inspiration for this project came from the growing need for more intuitive and accessible ways to interact with complex data and media. Retrieval Augmented Generation (RAG) combines the best of AI-powered retrieval and natural language generation, making it possible to seamlessly query and understand various forms of information. We wanted to create an application that empowers users to easily engage with their documents, videos, and other media in a conversational and accessible manner.
What it does
Our project enables users to:
- Upload and process various media types (PDFs, DOCX files, TXT files, YouTube videos, audio, video, and web URLs).
- Retrieve relevant document chunks using Snowflake Cortex Search.
- Generate natural language responses with Mistral LLM (mistral-large2).
- Listen to AI-generated responses through an integrated Text-to-Speech (TTS) feature.
- Manage uploaded documents with options to delete multiple files at once.
- Engage in seamless, conversational interactions without the need for technical expertise.

How we built it
The project was built using:
- Snowflake Cortex Search: For efficient and scalable retrieval of relevant document chunks.
- Mistral LLM: For generating natural language responses based on retrieved context.
- Streamlit: To create an intuitive and user-friendly interface for the application.
- Utility Libraries: To process various types of media:
- PyPDF2, docx for document processing.
- MoviePy and YouTube Transcript API for video and audio transcription.
- BeautifulSoup for extracting text from web URLs.
- A custom Text-to-Speech (TTS) function for generating audio responses.
Challenges we ran into
- Media Processing Complexity: Supporting a wide range of media types required integrating various libraries and ensuring robust error handling.
- Efficient Retrieval: Configuring and optimizing Snowflake Cortex Search to ensure accurate and fast document chunk retrieval.
- TTS Integration: Implementing the Text-to-Speech functionality while ensuring audio playback seamlessly integrated with the Streamlit interface.
- Managing Conversations: Maintaining a smooth conversational flow while differentiating between casual messages and context-dependent queries.
Accomplishments that we're proud of
- Successfully integrating Snowflake Cortex Search, Mistral LLM, and Streamlit into a cohesive and user-friendly application.
- Building a versatile media processing pipeline that handles a variety of file formats and links.
- Adding a TTS feature to improve accessibility and engagement.
- Creating a robust document management system that allows users to delete multiple files at once.
- Delivering a fully functional and scalable application within the hackathon timeline.
What we learned
- RAG Fundamentals: Deepened our understanding of Retrieval Augmented Generation and its potential to enhance AI applications.
- Snowflake Cortex Search: Gained insights into configuring and optimizing Snowflake Cortex Search for efficient document retrieval.
- Streamlit Best Practices: Learned how to build dynamic, responsive, and feature-rich frontends with Streamlit.
- Media Processing Techniques: Improved our ability to process and extract information from diverse media types.
- Error Handling and Scalability: Understood the importance of robust error handling and scalability in building user-centric applications.
What's next for Chat Anything
- Enhanced AI Model Integration: Explore additional LLMs and fine-tune the retrieval process for even more accurate results.
- Multi-Language Support: Add multi-language support for both text generation and TTS.
- Real-Time Collaboration: Enable real-time multi-user collaboration within the app.
- Advanced Analytics: Provide users with insights on frequently asked questions, popular documents, and retrieval performance.
- Mobile Application: Extend the functionality to mobile platforms for on-the-go accessibility.
Built With
- llm
- mistral
- python
- snowflake
- streamlit




Log in or sign up for Devpost to join the conversation.