Inspiration
I'm an entrepreneur at heart, constantly driven by a passion to build new things. This project was born from my desire to transitioning from Data Engineering field toward AI Egnineerging since my AWS love and recient skills learned around AI, two fields I deeply love. I’m especially obsetionated about creating SAAS platform powered bi AI with a purpose , it helps people to learn faster and more focus
What it does
ChaseClips is an accelerated learning engine powered by Amazon Nova that transforms any question into a personalized learning roadmap in under 90 seconds.
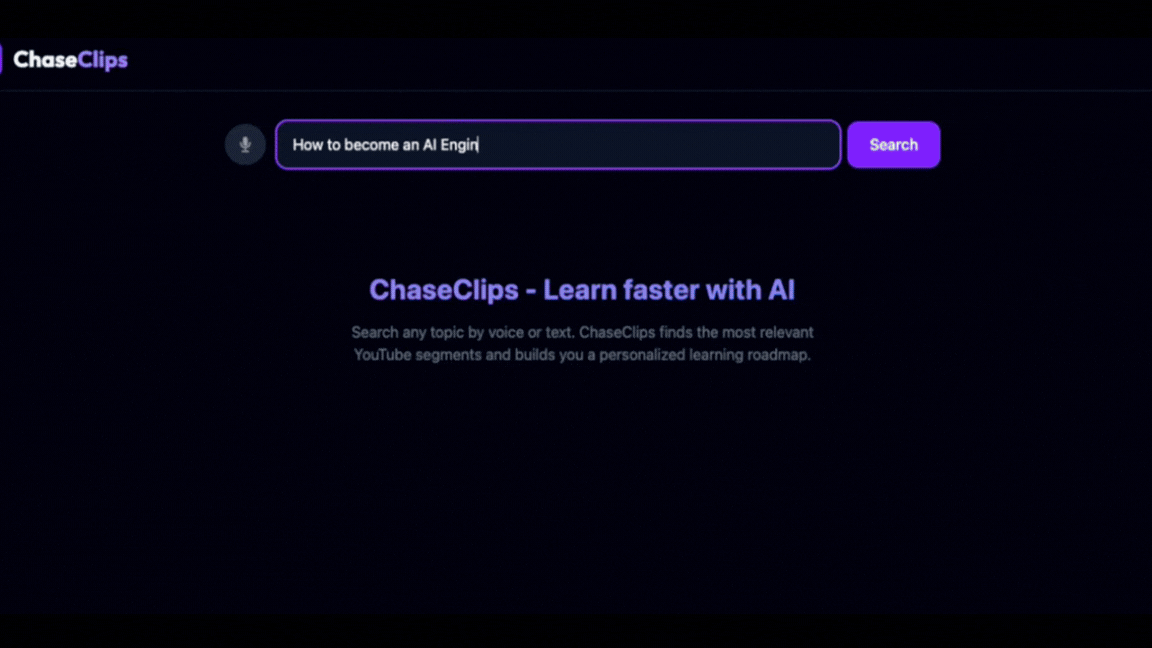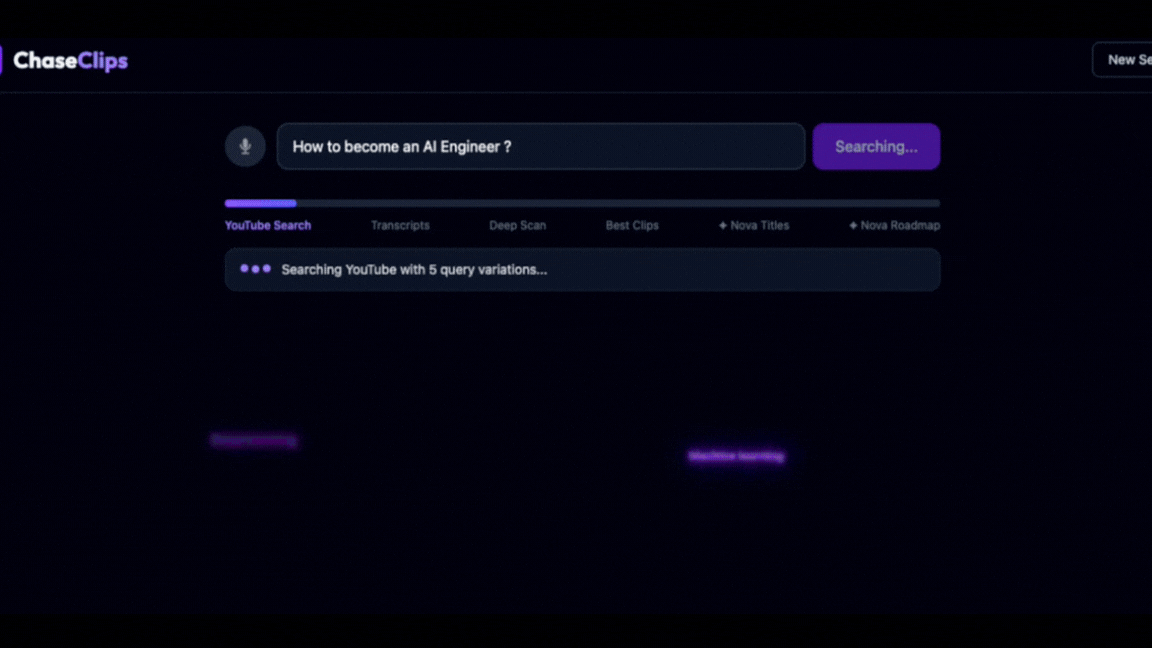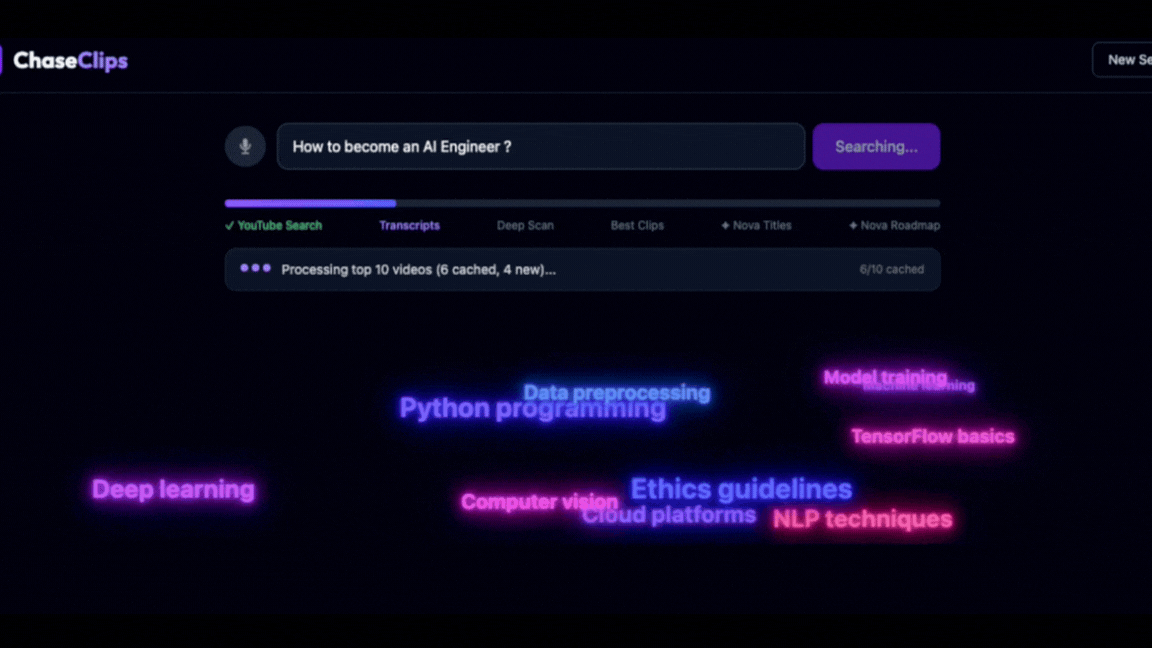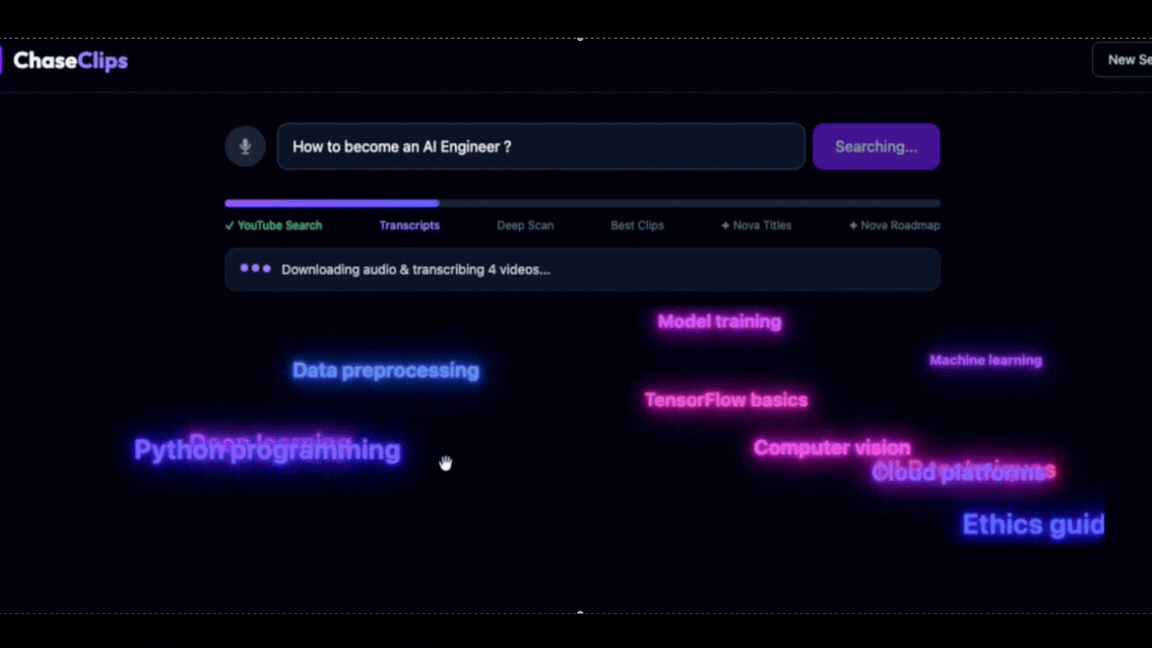
- Query expansion: You ask a question (voice or text, any language) → Amazon Nova Lite expands it into 5 optimized search queries → 200 YouTube videos evaluated and ranked
- Transcribe & embed: Top videos are transcribed via AWS Transcribe → chunked into 30–60s segments → embedded with Titan Embeddings V2 → stored and searched semantically via Qdrant
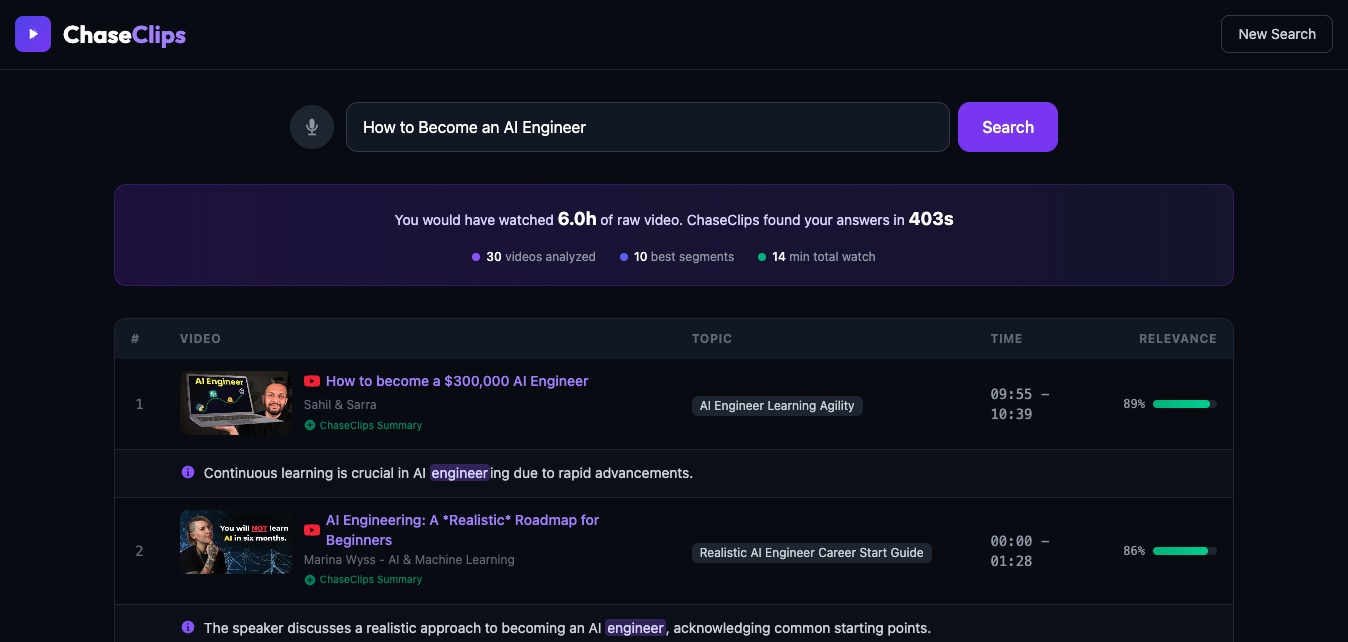
- Learn smarter: Amazon Nova Pro synthesizes a step-by-step learning roadmap from the highest-relevance segments across multiple videos — with direct links to each source
This is not a video summarizer. It's a segment-level knowledge accelerator that finds, ranks, and connects the best learning moments scattered across YouTube into one coherent path.
How we built it
Backend — Python + FastAPI (async), orchestrating a multi-stage RAG pipeline:
- Query expansion with Amazon Nova Lite via AWS Bedrock — generates 5 search variations + keywords per user query
- YouTube Data API v3 — retrieves up to 200 candidate videos, filtered and ranked by a discovery score (views, engagement, recency)
- Audio extraction with yt-dlp → uploaded to S3 → transcribed with AWS Transcribe (5 concurrent jobs)
- Chunking into 30–60 second segments → embedded with Amazon Titan Embeddings V2 (1024 dimensions)
- Semantic search via Qdrant Cloud (k=50 candidates) → relevance scoring → top segments selected
- Synthesis with Amazon Nova Pro — generates a structured learning roadmap from the best segments across multiple videos
Frontend — React 19 + TypeScript + Vite + Tailwind CSS + Zustand for state management. Real-time pipeline progress streamed via Server-Sent Events (SSE) with manual formatting for reliability. Includes voice search with automatic language detection via the Web Speech API.
Infrastructure — PostgreSQL on Amazon RDS for caching videos, segments, and search history. Amazon S3 for audio and transcript storage. Qdrant Cloud for vector persistence. All AWS services in us-east-1.
Challenges we ran into
The most important challenge here was :
- YouTube transcript access is unreliable: The youtube-transcript-api library frequently failed or returned empty results. We migrated the entire transcription pipeline to yt-dlp (audio download) + AWS Transcribe, running 5 concurrent transcription jobs to keep latency manageable.
- Cache false positives caused empty results: Our cache lookup was marking videos as "already processed" even when their segments hadn't been stored yet. A missing INNER JOIN meant the app would skip transcription for videos it thought it had but didn't. One join fixed hours of debugging.
- Balancing quality vs. YouTube rate limits: The pipeline fires 5 expanded queries × 40 results = 200 videos per search. Staying under YouTube API quotas while still retrieving enough candidates for good results required careful filtering by duration, views, and a discovery score formula before making any expensive API calls.
- Voice search only worked in English: The Web Speech API was hardcoded to en-US, breaking the multilingual promise of the app. We switched to navigator.language to auto-detect the user's browser language, enabling voice search in Spanish and any other supported language.
- SSE streaming broke at every layer: Our initial Server-Sent Events implementation using sse-starlette silently failed. We had to switch to raw StreamingResponse with manual SSE formatting, bypass the Vite proxy (which buffered the stream), and remove request.is_disconnected() checks that were prematurely killing the connection. Each fix revealed the next problem.
Accomplishments that we're proud of
- I absolutely love AWS Nova models and being able to integrate several AWS models in my project — Titan for embeddings, Nova Lite for query expansion and titling, and last but not least, Nova Pro for synthesizing information in order to create an effective learning roadmap.
- I'm truly proud of solve the problem that I suffer every day , I hate to spend time searching the right video in Youtube , with my app I have the opportunity to go cut to the chase for my learning needed instead to hear is "like, subscribe, and hit that bell icon" 🔔 — you just want the knowledge, now.
- Successfully supporting to the conten creators who are the the most relevant part of this learning ecosystem. Inside ChaseClips, there’s a special hub that spotlights creators who crush it on the topics you care about.
What we learned
After two weeks of intense work, I learned that the barrier between idea and reality has never been lower. As a data engineer, I'm not familiar with frontend technologies, but I wanted to challenge myself to build a full-stack application from scratch end to end, all in one, ready to go. This hackathon pushed me well outside my comfort zone, and that's exactly where the growth happened. Thanks to the AWS Nova AI Hackathon for this opportunity to push past our limits.
What's next for ChaseClips
- Scheduled video ingestion by category: Build an automated pipeline that continuously indexes YouTube videos by topic, keeping the knowledge base fresh with the latest content and metrics. A larger, up-to-date database means better and faster recommendations for every search.
- AI-powered SaaS platform: Transform ChaseClips into a subscription-based service with a freemium tier and a premium monthly plan. This includes implementing a robust authentication system and user management to support the monetization model.
- Personalized learning with Nova Sonic: Integrate Amazon Nova Sonic as a premium feature to deeply understand each user's learning goals through voice interaction, delivering tailored recommendations (daily, weekly, or monthly) based on their evolving interests.
Built With
- amazon-rds-relational-database-service
- amazon-titan
- amazon-web-services
- aws-transcribe
- bedrock
- fastapi
- nova-lite
- nova-pro
- python
- qdrant
- rag
- vector-search


Log in or sign up for Devpost to join the conversation.