-
-
UI
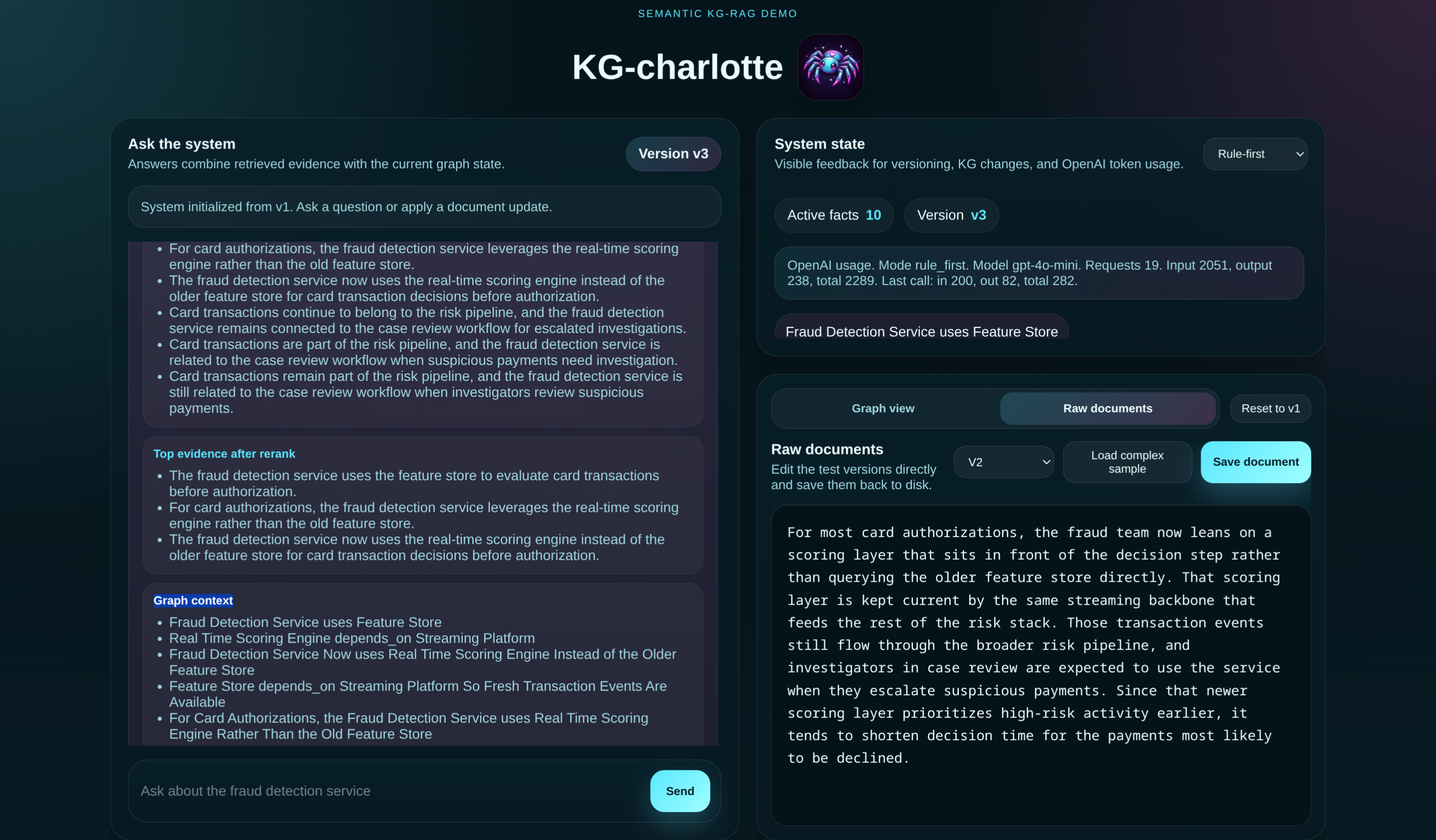
What it does
This prototype builds a self-updating KG-RAG system that:
extracts structured facts (triples) from documents stores them in an in-memory Knowledge Graph detects semantic changes when documents are updated updates only the affected parts of the graph (incremental repair) resolves conflicts between old and new knowledge combines vector search + graph traversal for better retrieval visualizes the evolving graph interactively
How we built it
The system is built using a modular pipeline:
Haystack for RAG orchestration ChromaDB for vector storage and similarity search NetworkX for the in-memory Knowledge Graph PyVis for graph visualization LLM-based extraction to convert text into structured facts
Core workflow:
Documents are chunked and embedded LLM extracts (subject, relation, object) facts Facts are stored in a graph with provenance and versioning When a document updates: changed chunks are detected via hashing facts are re-extracted semantic diff identifies changes graph is patched (not rebuilt) Retrieval combines: vector similarity graph neighbor expansion
Challenges we ran into
Reliable fact extraction: LLM outputs can be inconsistent, requiring normalization and schema constraints Entity ambiguity: Different names for the same concept caused duplicate nodes Semantic diff complexity: Determining whether two facts are “different” is non-trivial Conflict handling: Designing a simple but meaningful policy (active/inactive facts) Balancing simplicity vs realism: Keeping the system lightweight while still demonstrating real innovation Graph + RAG integration: Making the graph actually influence retrieval, not just exist separately
Accomplishments that we're proud of
Built a fully working end-to-end KG-RAG prototype Implemented semantic-level updates, not just text diffs Achieved incremental graph repair instead of full rebuilds Designed a clean conflict resolution mechanism with history preservation Successfully integrated graph reasoning into retrieval pipeline Created interactive visualization of evolving knowledge
What we learned
Knowledge Graphs become powerful when combined with provenance and versioning Most RAG systems ignore knowledge evolution, which is a major limitation Incremental updates are feasible with simple design choices (chunk-level + fact-level diff) Even lightweight systems can demonstrate research-level ideas Graph + vector hybrid retrieval significantly improves interpretability Designing constraints (fixed schema, 1-hop traversal) is critical to keep complexity manageable
What's next for Charlotte
Charlotte (the system) can be extended in several directions:
Better entity resolution merge duplicate entities handle synonyms automatically Confidence-aware reasoning weigh facts by confidence and frequency Multi-hop graph reasoning enable deeper inference beyond 1-hop Advanced conflict resolution support multiple sources and truth ranking Real-time updates move from batch updates to streaming User interface interactive UI for querying and visualizing graph evolution Domain specialization adapt schema and extraction for specific domains (research, finance, engineering, etc.)
Built With
- chromadb
- haystack
- python

Log in or sign up for Devpost to join the conversation.