🛡️ ChaosAI: The Outage-Resilient Customer Support Gateway
💡 Inspiration
In modern enterprise ecosystems, customer service is increasingly delegated to Large Language Models (LLMs). However, relying on a single AI provider introduces a catastrophic single point of failure. API outages, network storms, billing disruptions, or rate-limiting ($HTTP\ 429$) can freeze support chats, leaving customers stranded.
We were inspired to build ChaosAI after witnessing major LLM provider outages that took down hundreds of dependent SaaS platforms. We asked ourselves: How can we build an AI-driven support agent that guarantees 100% uptime, even when the underlying AI models are crashing around it? Our solution is an outage-resilient gateway that orchestrates a multi-agent resilience cascade.
⚙️ How We Built It
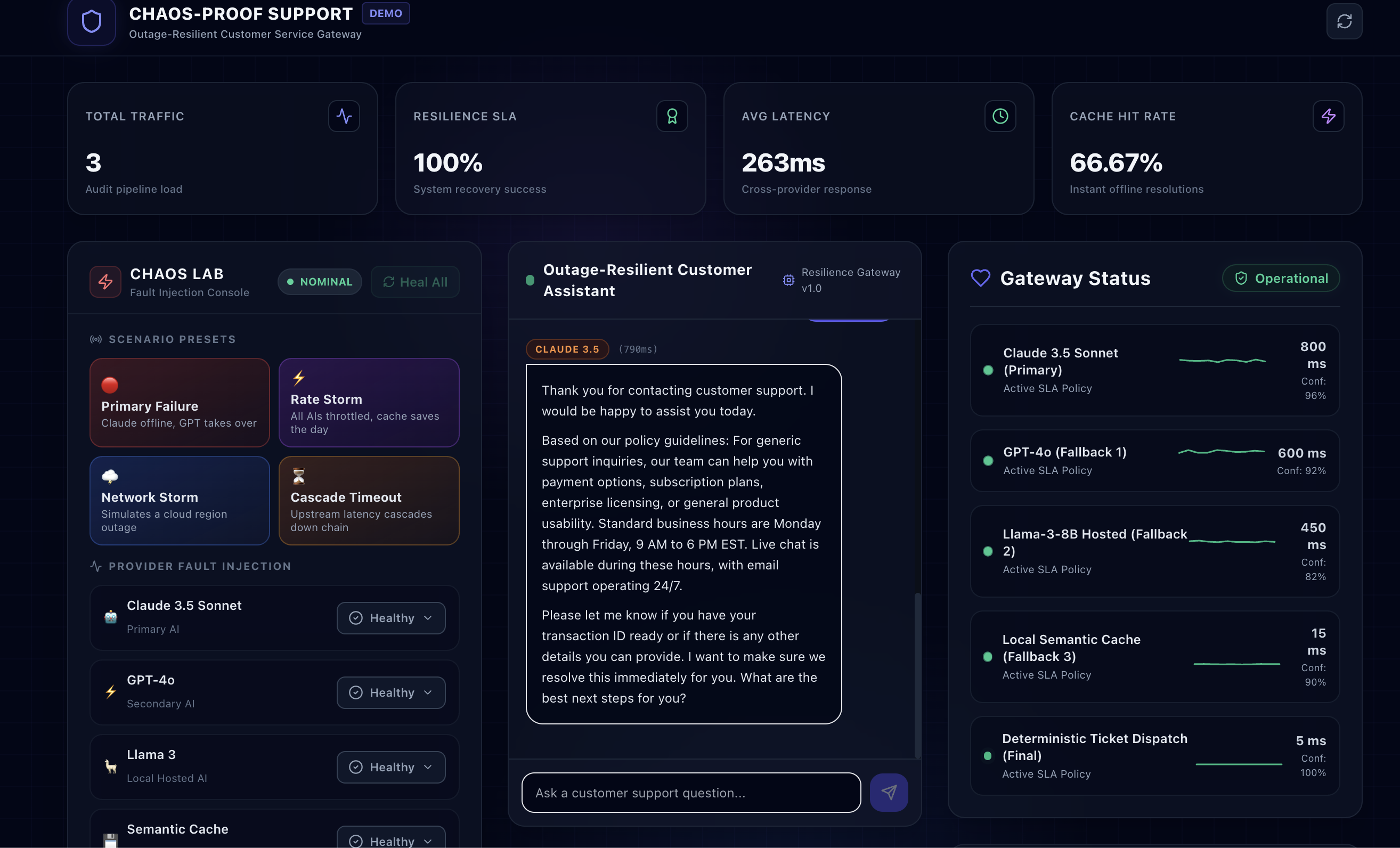
ChaosAI is engineered using a robust, decoupled architecture separating a responsive frontend dashboard from an intelligent, self-healing backend gateway.
- The Gateway Cascade & Adaptor Pattern: We wrapped multiple AI models (Claude 3.5 Sonnet, GPT-4o, Llama 3) into uniform structural adapters, allowing seamless runtime switches when a higher-priority model fails.
- Layer 0 Semantic Cache: To optimize for cost and speed, queries check a local semantic database before passing to the LLM router. If semantic similarity scores cross our threshold: $$\text{Similarity}(q, c) \ge 0.85$$ The system returns an instant match in $< 20\text{ms}$.
- Stateful Circuit Breaker: To avoid enduring long API timeout penalties over and over, we implemented a three-state circuit breaker ($\text{CLOSED}$, $\text{OPEN}$, $\text{HALF-OPEN}$). If a provider fails 3 consecutive times, the circuit opens, and subsequent requests fast-fail instantly to the next standby model.
- The Chaos Control Panel: Built using React and Vite, the frontend features a dedicated "Chaos Board" that lets users actively inject faults (503 Outages, Latency Storms, Rate Limits) to visualize the backend's self-healing fallback path in real-time.
🚧 Challenges We Faced
- The Latency Penalty Dilemma: Initially, cascading down multiple failing providers caused an accumulation of timeouts, blowing up total response time. We solved this by implementing the stateful Circuit Breaker pattern to bypass dead endpoints instantly.
- Database Concurrency Bottlenecks: Under heavy simultaneous requests, logging real-time audit trails into standard SQLite caused frequent database locks. We overcame this by refactoring our storage engine to utilize an asynchronous, non-blocking I/O pattern with
aiosqlite. - Prompt Discrepancies: Different models behave differently given the exact same instructions. We had to tailor model-specific system prompt templates so smaller fallback models like Llama 3 still generated properly structured, helpful responses.
🧠 What We Learned
Building ChaosAI taught us a massive amount about distributed systems, defensive AI engineering, and the realities of production LLM orchestration. We learned that system reliability isn't just about handling happy paths—it's about engineering elegant systems that degrade gracefully under total infrastructure failure. We also deepened our knowledge of asynchronous Python architecture, state machines, and designing intuitive UI dashboards for complex real-time event feeds.
Built With
- aiosqlite
- anthropic
- css3
- groq
- openai
- pytest
- python
- react.js
- tailwind
- typescript
- vite


Log in or sign up for Devpost to join the conversation.