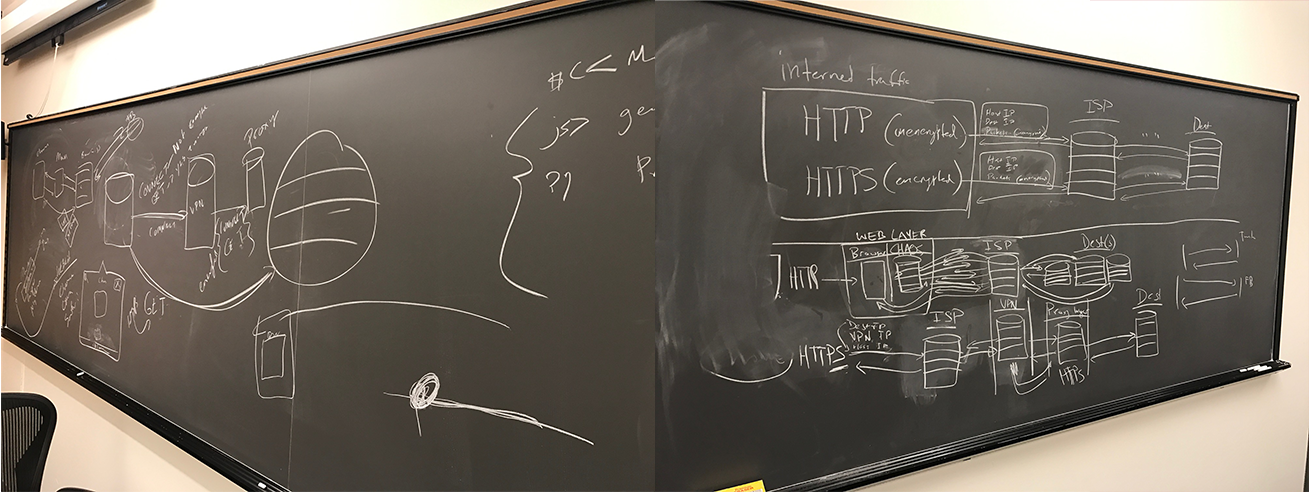
Inspiration
Ricky and I are big fans of the software culture. It's very open and free, much like the ideals of our great nation. As U.S. military veterans, we are drawn to software that liberates the oppressed and gives a voice to those unheard.
Senate Joint Resolution 34 is awaiting ratification from the President, and if this happens, internet traffic will become a commodity. This means that Internet Service Providers (ISPs) will have the capability of using their users' browsing data for financial gain. This is a clear infringement on user privacy and is diametrically opposed to the idea of an open-internet. As such, we decided to build chaos, which gives a voice... many voices to the user. We feel that it's hard to listen in on a conversation in a noisy room.
What it does
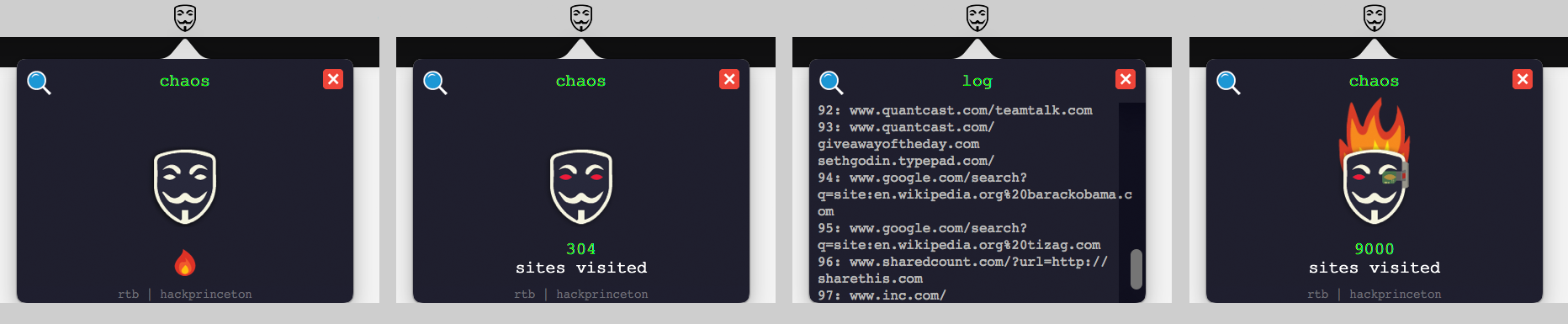
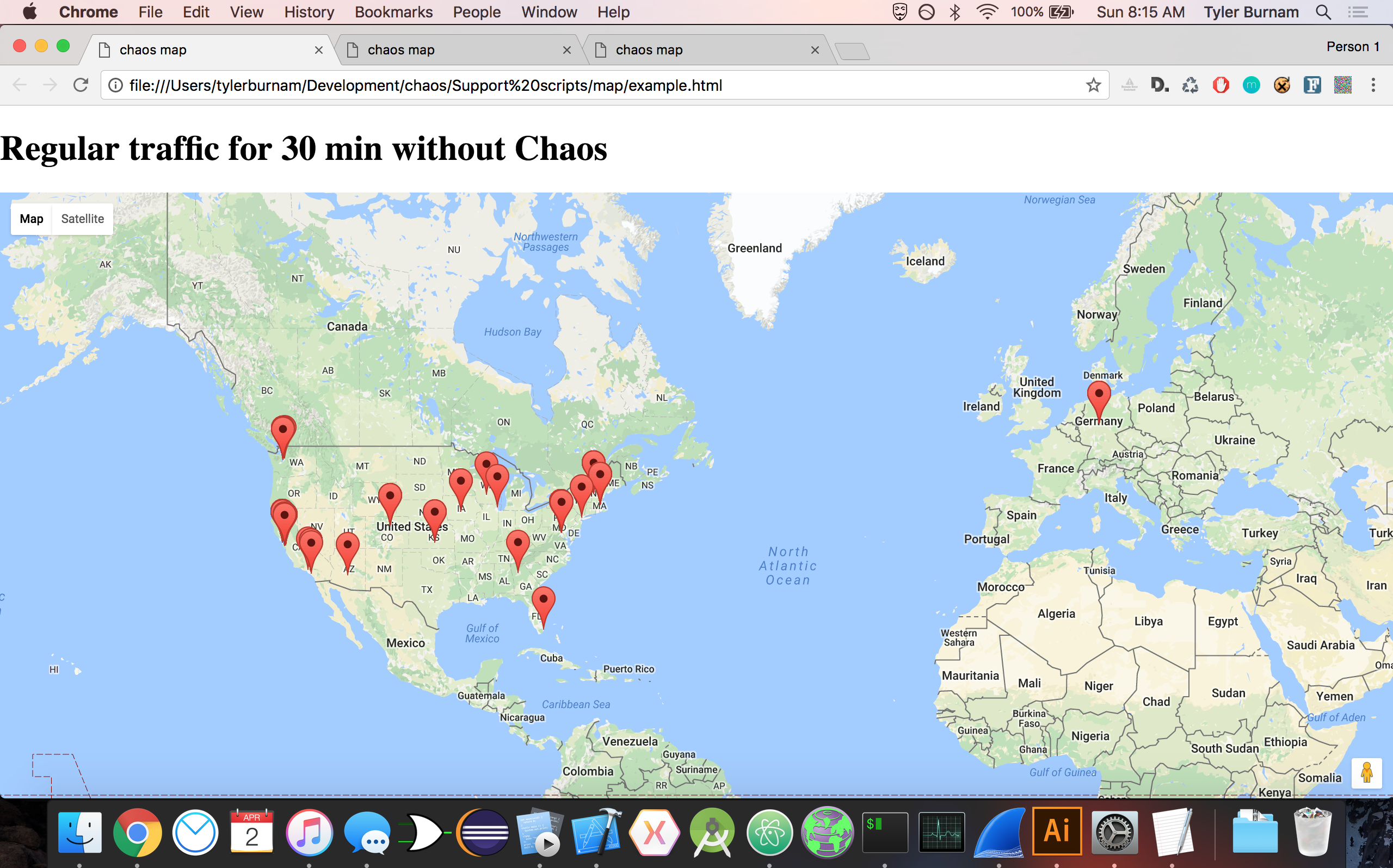
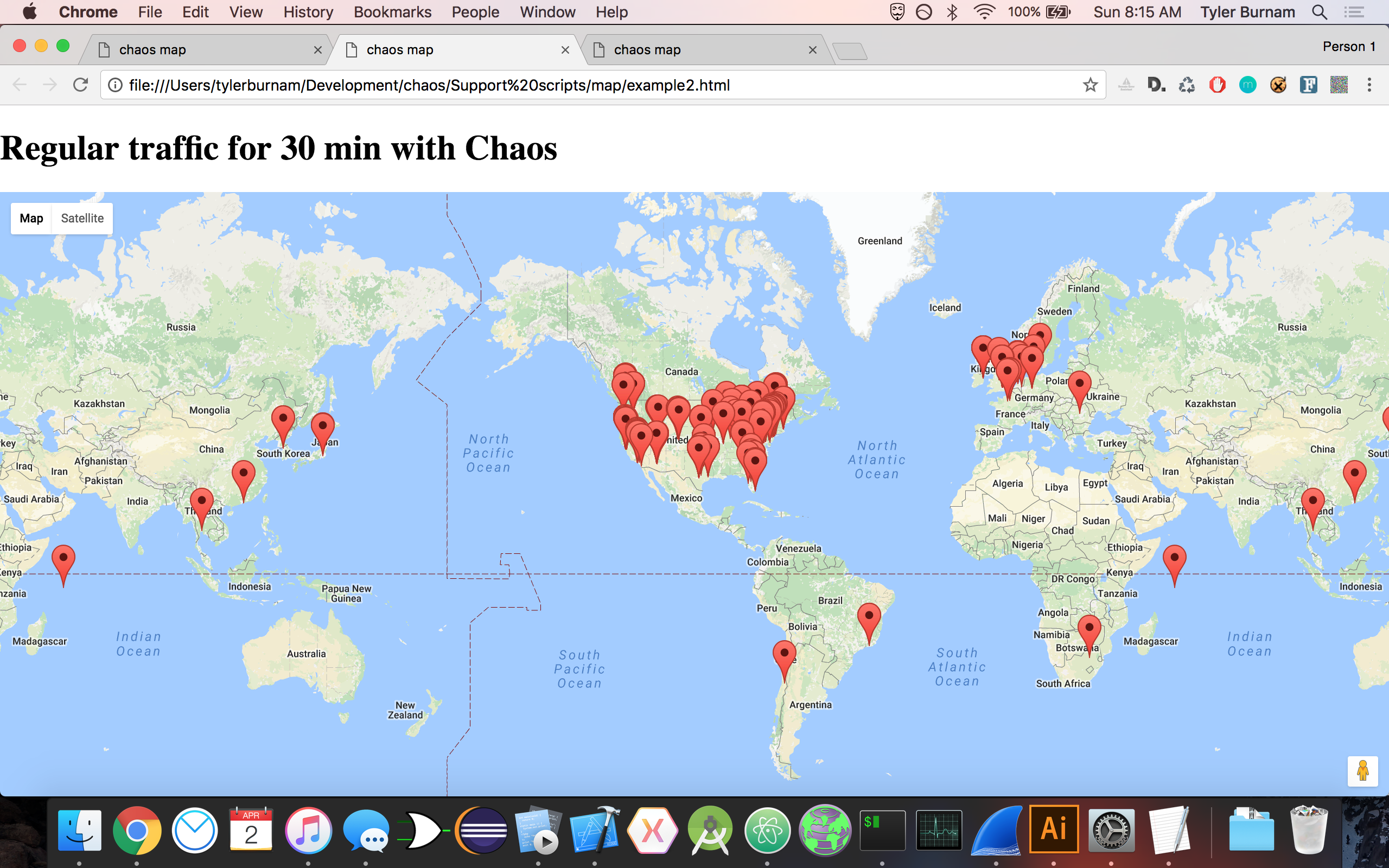
Chaos hides browsing patterns.
Chaos leverages chaos.js, a custom headless browser we built on top of PhantomJS and QT, to scramble incoming/outgoing requests that distorts browsing data beyond use. Further, Chaos leverages its proxy network to supply users with highly-reliable and secure HTTPS proxies on their system.
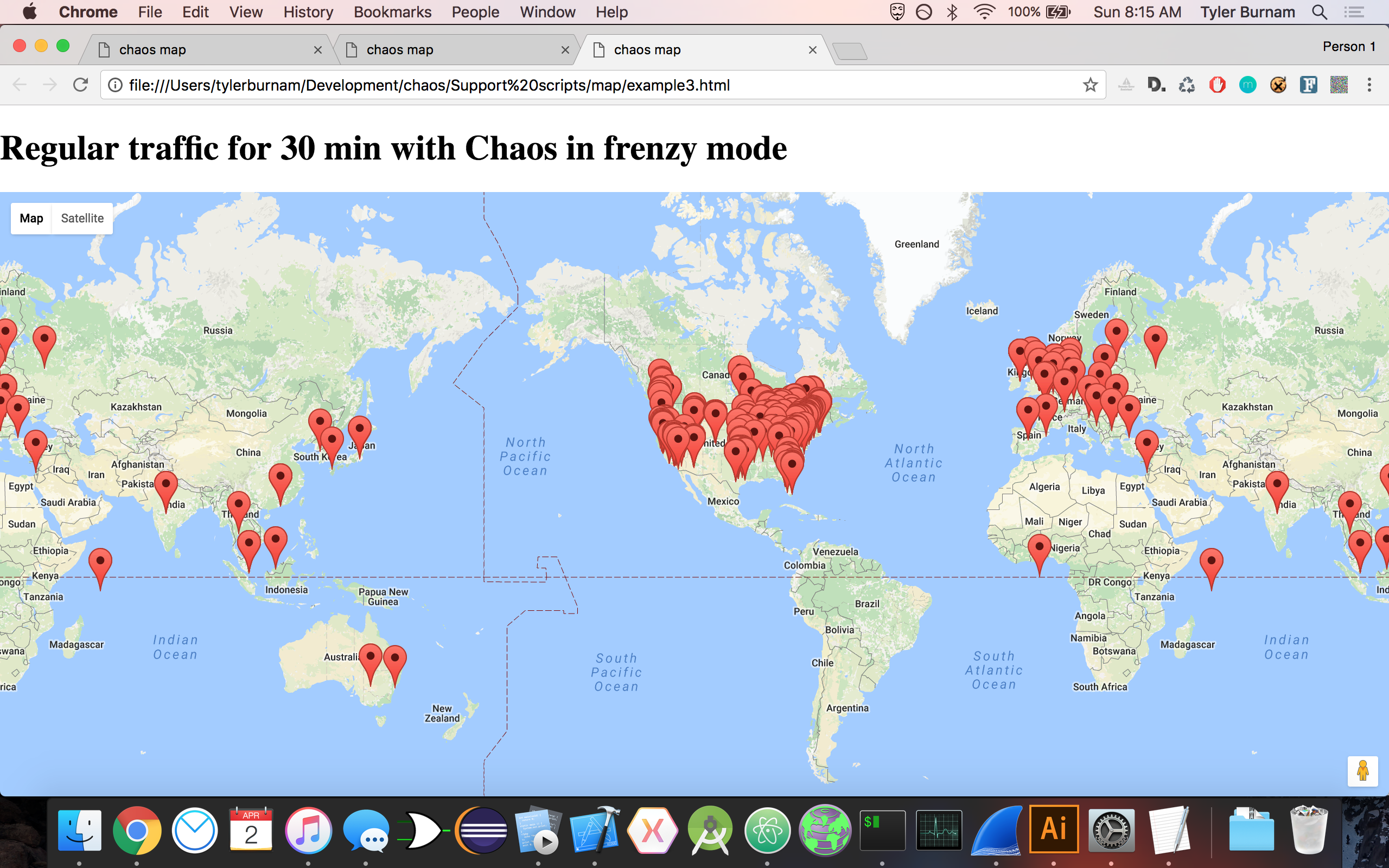
By using our own custom browser, we are able to dispatch a lightweight headless browser that mimics human-computer interaction, making its behavior indistinguishable from our user's behavior. There are two modes: chaos and frenzy. The first mode scrambles requests at an average of 50 sites per minute. The second mode scrambles requests at an average of 300 sites per minute, and stops at 9000 sites. We use a dynamically-updating list of over 26,000 approved sites in order to ensure diverse and organic browsing patterns.
How we built it
Development of the chaos is broken down into 3 layers we had to build
- OS X Client
- Headless browser engine (chaos.js)
- Chaos VPN/Proxy Layer
Layer 1: OS X Client

The Chaos OS X Client scrambles outgoing internet traffic. This crowds IP data collection and hides browsing habits beneath layers of organic, randomized traffic.
OS X Client implementation
- Chaos OS X is a light-weight Swift menubar application
- Chaos OS X is built on top of chaos.js, a custom WebKit-driven headless-browser that revolutionizes the way that code interacts with the internet. chaos.js allows for outgoing traffic to appear completely organic to any external observer.
- Chaos OS X scrambles traffic and provides high-quality proxies. This is a result of our development of chaos.js headless browser and the Chaos VPN/Proxy layer.
- Chaos OS X has two primary modes:
- chaos: Scrambles traffic on average of 50 sites per minute.
- frenzy: Scrambles traffic on average of 500 sites per minute, stops at 9000 sites.
Layer 2: Headless browser engine (chaos.js)
Chaos is built on top of the chaos.js engine that we've built, a new approach to WebKit-driven headless browsing. Chaos is completely indiscernible from a human user. All traffic coming from Chaos will appear as if it is actually coming from a human-user. This was, by far, the most technically challenging aspect of this hack. Here are a few of the changes we made:
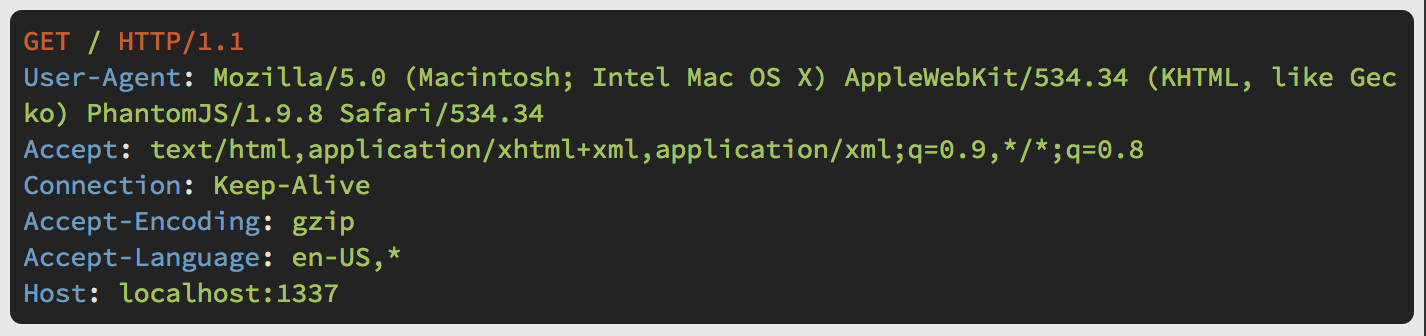
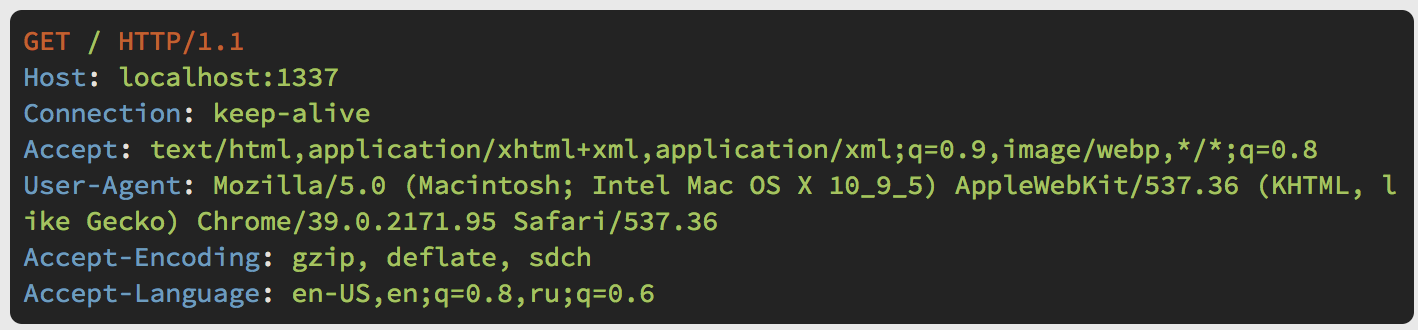
#Step 1: Modify header ordering in the QTNetwork layer
Chrome headers

PhantomJS headers

The header order between other WebKit browsers come in static ordering. PhantomJS accesses WebKit through the Qt networking layer.
Modified: qhttpnetworkrequest.cpp
Step 2: Hide exposed footprints
Modified: examples/pagecallback.js
src/ghostdriver/request_handlers/session_request_handler.js
src/webpage.cpp
test/lib/www/*
Step 3: Client API implementation
- User agent randomization
- Pseudo-random bezier mouse path generation
- Speed trap reactive DOM interactions
- Dynamic view-port
- Other changes...
Layer 3: Chaos VPN/Proxy Layer
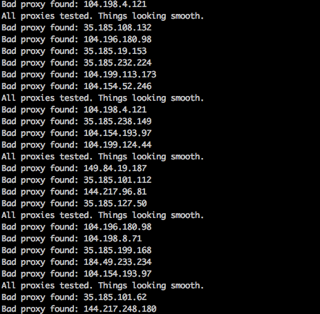
The Chaos VPN back-end is made up of two cloud systems hosted on Linode: an OpenVPN and a server. The server deploys an Ubuntu 16.10 distro, which functions as a dynamic proxy-tester that continuously parses the Chaos Proxies to ensure performance and security standards. It then automatically removes inadequate proxies and replaces them with new ones, as well as maintaining a minimum number of proxies necessary. This ensures the Chaos Proxy database is only populated with efficient nodes.
The purpose of the OpenVPN layer is to route https traffic from the host through our VPN encryption layer and then through one of the proxies mentioned above, and finally to the destination. The VPN serves as a very safe and ethical layer that adds extra privacy for https traffic. This way, the ISP only sees traffic from the host to the VPN. Not from the VPN to the proxy, from the proxy to the destination, and all the way back. There is no connection between host and destination.
Moving forward we will implement further ways of checking and gathering safe proxies. Moreover, we've begun development on a machine learning layer which will run on the server. This will help determine which sites to scramble internet history with based on general site sentiment. This will be acomplished by running natural-language processing, sentiment analysis, and entity analytics on the sites.
Challenges we ran into
This project was huge. As we peeled back layer after layer, we realized that the tools we needed simply didn't exist or weren't adequate. This required us to spend a lot of time in several different programming languages/environments in order to build the diverse elements of the platform. We also had a few blocks in terms of architecture cohesion. We wrote the platform in 6 different languages in 5 different environments, and all of the pieces had to work together exceedingly well. We spent a lot of time at the data layer of the respective modules, and it slowed us down considerably at times.

Accomplishments that we're proud of
- We began by contributing to the open-source project pak, which allowed us to build complex build-scripts with ease. This was an early decision that helped us tremendously when dealing with
netstat, network diagnostics and complex python/node scrape scripts.
- We're most proud of the work we did with chaos.js. We found that every headless browser that is publicly available is easily detectable. We tried PhantomJS, Selenium, Nightmare, and Casper (just to name a few), and we could expose many of them in a matter of minutes. As such, we set out to build our own layer on top of PhantomJS in order to create the first, truly undetectable headless browser.
- This was massively complex, with programming done in C++ and Javascript and nested Makefile dependencies, we found ourselves facing a giant. However, we could not afford for ISPs to be able to distinguish a pattern in the browsing data, so this technology really sits at the core of our system, alongside some other cool elements.
What we learned
In terms of code, we learned a ton about HTTP/HTTPS and the TCP/IP protocols. We also learned first how to detect "bot" traffic on a webpage and then how to manipulate WebKit behavior to expose key behaviors that mask the code behind the IP. Neither of us had ever used Linode, and standing up two instances (a proper server and a VPN server) was an interesting experience. Fitting all of the parts together was really cool and exposed us to technology stacks on the front-end, back-end, and system level.
What's next for chaos
More code! We're planning on deploying this as an open-source solution, which most immediately requires a build script to handle the many disparate elements of the system. Further, we plan on continued research into the deep layers of web interaction in order to find other ways of preserving anonymity and the essence of the internet for all users!


Log in or sign up for Devpost to join the conversation.