-
-
cover
ChangeScribe + AskScribe
Inspiration
Domain knowledge is locked inside code.
When someone asks, "Can a customer get a refund if their order already shipped?", the answer usually exists, but only inside code mixed with logging, retries, database calls, and implementation details. That creates friction everywhere: engineers have to read unfamiliar code to answer business questions, important rules change without anyone explicitly reviewing the knowledge change, and AI systems that rescan raw code on every query are slow, expensive, and inconsistent.
I wanted to solve that by making knowledge extraction part of the code review workflow itself. Not a separate documentation task. Not a wiki nobody updates. The core idea behind ChangeScribe is simple: if code changes domain behavior, that knowledge change should be visible, reviewable, and committed alongside the code. Then AskScribe can answer questions from that reviewed knowledge first, instead of rebuilding context from scratch every time.
What it does
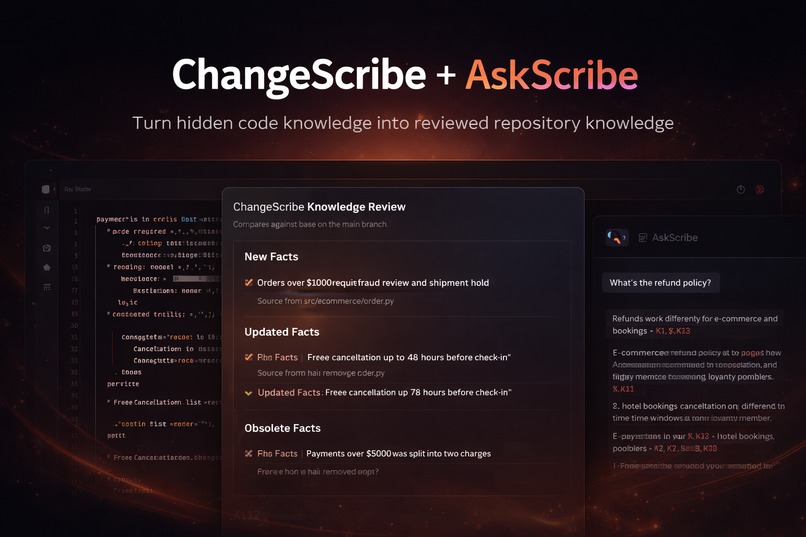
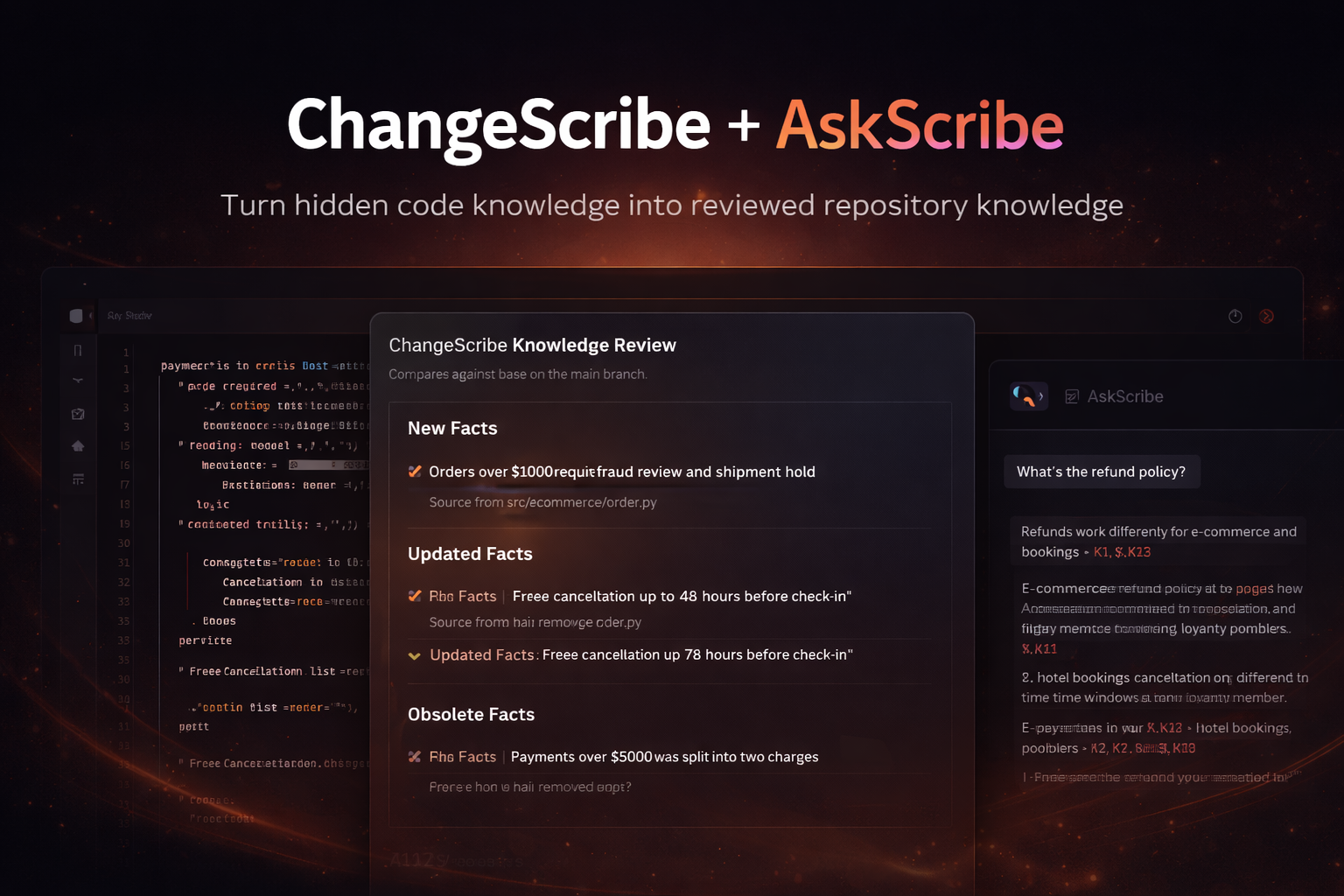
ChangeScribe + AskScribe turns hidden code knowledge into reviewed repository knowledge.
ChangeScribe is a GitLab flow. When you mention it on a merge request or assign it as reviewer, it reads the MR diff, compares the code changes against the existing knowledge base, and posts a diff-style review of domain facts:
- new facts
- updated facts
- obsolete facts
- unchanged facts
Developers can then respond with commands like:
- @changescribe accept all
- @changescribe accept f1 f3
- @changescribe reject f2
- @changescribe edit f1: corrected wording
Once approved, ChangeScribe commits the updated knowledge back into the repo under knowledge/.
AskScribe is a GitLab agent. It answers questions from the reviewed knowledge base with citations to stable fact IDs like K1, K2, and so on. For most questions, it answers instantly from reviewed knowledge. If the knowledge base does not cover the topic, or the user explicitly asks for a deeper investigation, AskScribe can also read the source directly and clearly mark those findings as unreviewed.
This gives the repo a maintained, queryable knowledge layer that evolves with the code.
How I built it
I built the project entirely on GitLab Duo Agent Platform using:
- a custom multi-agent flow for ChangeScribe
- a custom chat agent for AskScribe
- GitLab built-in tools for reading merge requests, diffs, files, notes, and committing updates
- GitLab-managed Anthropic Claude through the GitLab AI Gateway for all reasoning
The system has three main parts.
ChangeScribe flow
A multi-agent flow with a Reader and a Writer.
The Reader:
- reads merge request metadata and diffs
- reads full file contents for changed files
- reads the current knowledge files
- filters out likely infra and boilerplate files
- extracts and classifies domain facts as new, updated, obsolete, or unchanged
- auto-discovers domain names from changed file paths, so src/payments/ becomes knowledge/payments.md automatically
The Writer:
- formats the review comment
- processes accept, reject, and edit commands
- selective accept leaves other facts pending, so accepting f1 when f1-f4 exist only processes f1
- updates only the knowledge/ folder
- commits approved changes back to the MR source branch
Knowledge files
Instead of using an external database, I store reviewed knowledge directly in the repository as markdown files under knowledge/, split by domain:
- knowledge/ecommerce.md
- knowledge/booking.md
Each fact is structured, stable, and human-readable. Facts are grouped by type such as Rule, Constraint, Behavior, and Integration, and each one links back to its source file.
AskScribe agent
AskScribe reads the repository knowledge first and answers with citations to reviewed facts. That makes common questions fast and grounded. When the reviewed knowledge is not enough, it can still deep-dive into the code and clearly distinguish those answers from reviewed knowledge.
Challenges I ran into
I explored several architectures that depended on external persistence, cross-repo automation, and backend calls, then had to keep simplifying as I learned what was actually practical inside the hackathon environment. The hardest design question was finding a version that still felt valuable without depending on an external backend or database in the critical path.
Another challenge was making the extraction useful rather than noisy. If the system blindly summarized code, it quickly became a smart comment bot. To make it valuable, I had to focus on domain knowledge and not technical detail, and explicitly filter out infra noise like config, middleware, and database plumbing.
A third challenge was command handling and safety. Once I allowed review commands like accept, reject, and edit inside MR comments, I had to make sure the flow only processed valid aliases, only modified reviewed facts, and only wrote to the knowledge/ folder. All guardrails were tested manually during development.
Accomplishments that I'm proud of
I am proud that the final project feels like a real GitLab-native workflow and not just a chatbot with a prompt.
A few things I am especially happy with:
- the split between ChangeScribe and AskScribe is clear and easy to understand
- the diff-style MR review makes knowledge changes visible at the same moment code changes happen
- the human-in-the-loop flow is simple but powerful: accept, reject, or edit proposed facts
- selective accept works correctly: accepting f1 when f1-f4 exist only processes f1 and leaves the rest pending
- domain files are discovered automatically from source paths, so no repo-specific config is needed
- reviewed knowledge is stored directly in the repo, so there is no hidden state and no external database dependency
- AskScribe gives a strong user experience by answering from reviewed knowledge first, but still supporting deep dives when needed
- I built meaningful guardrails around what the system can write and how it responds to misuse
Most importantly, I turned knowledge extraction from an abstract AI idea into something concrete, reviewable, and commit-able.
What I learned
I learned that platform constraints shape the product more than the initial idea does.
At first I was thinking about a larger knowledge system with external storage and richer automation. But the more I worked inside GitLab Duo Agent Platform, the more I realized the winning version had to be simpler, more native, and more workflow-driven.
I also learned that there is a big difference between generating documentation and making knowledge changes reviewable. That distinction became the heart of the project. The real value is not just extracting facts. It is making important domain knowledge changes visible during code review, with human approval before they become part of the knowledge base.
I also learned that no external backend can be a strength. It forced me to design the system in a way that is easier to understand, easier to demo, and more aligned with the platform.
What's next for ChangeScribe + AskScribe
- Multi-repo knowledge: right now ChangeScribe works inside a single repository. The real opportunity is tracking facts across services so teams can query domain behavior that spans the whole platform, not just one project.
- Vector store for facts: storing facts in a vector database instead of markdown files would make AskScribe significantly more powerful, enabling semantic search across thousands of facts without reading every file on each query.
- Onboarding new projects: a one-shot scan that extracts the full knowledge base from an existing codebase, so teams can get value from day one without waiting for MRs to accumulate facts over time.
Built With
- agentic
- ai
- anthropic
- automation
- claude
- code-review
- gitlab
- gitlab-duo
- knowledge-management
- llm
Log in or sign up for Devpost to join the conversation.