-
-
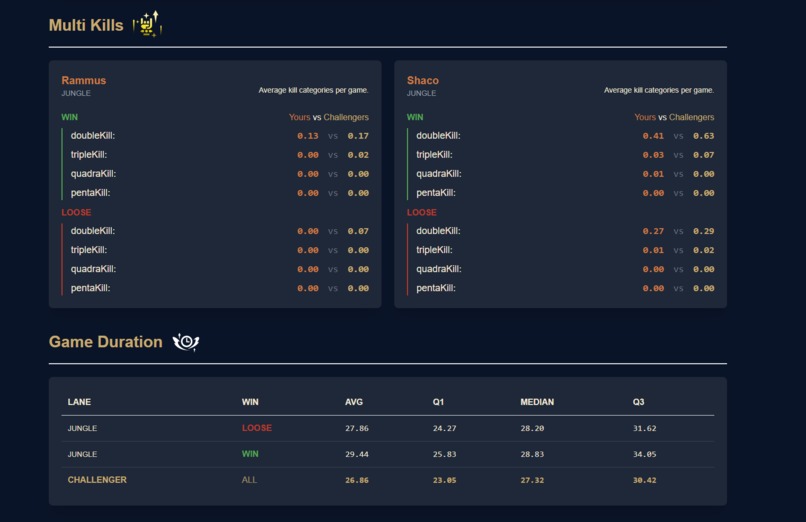
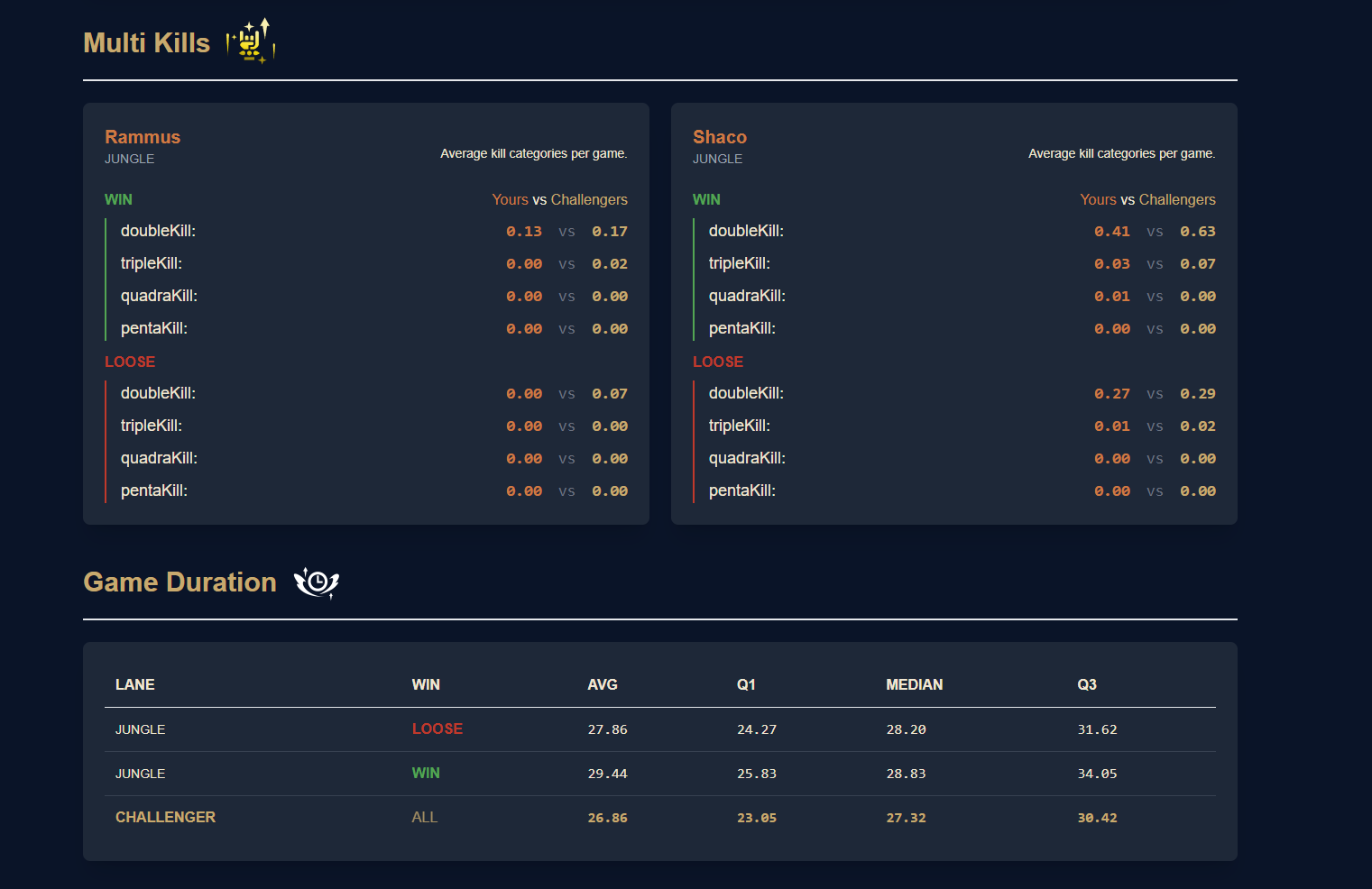
Multi elimination + Game duration compared with challengers
-
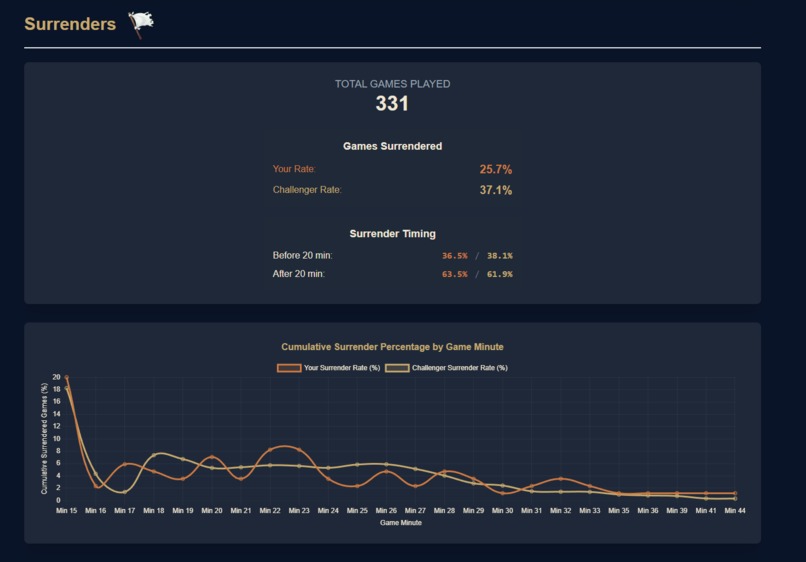
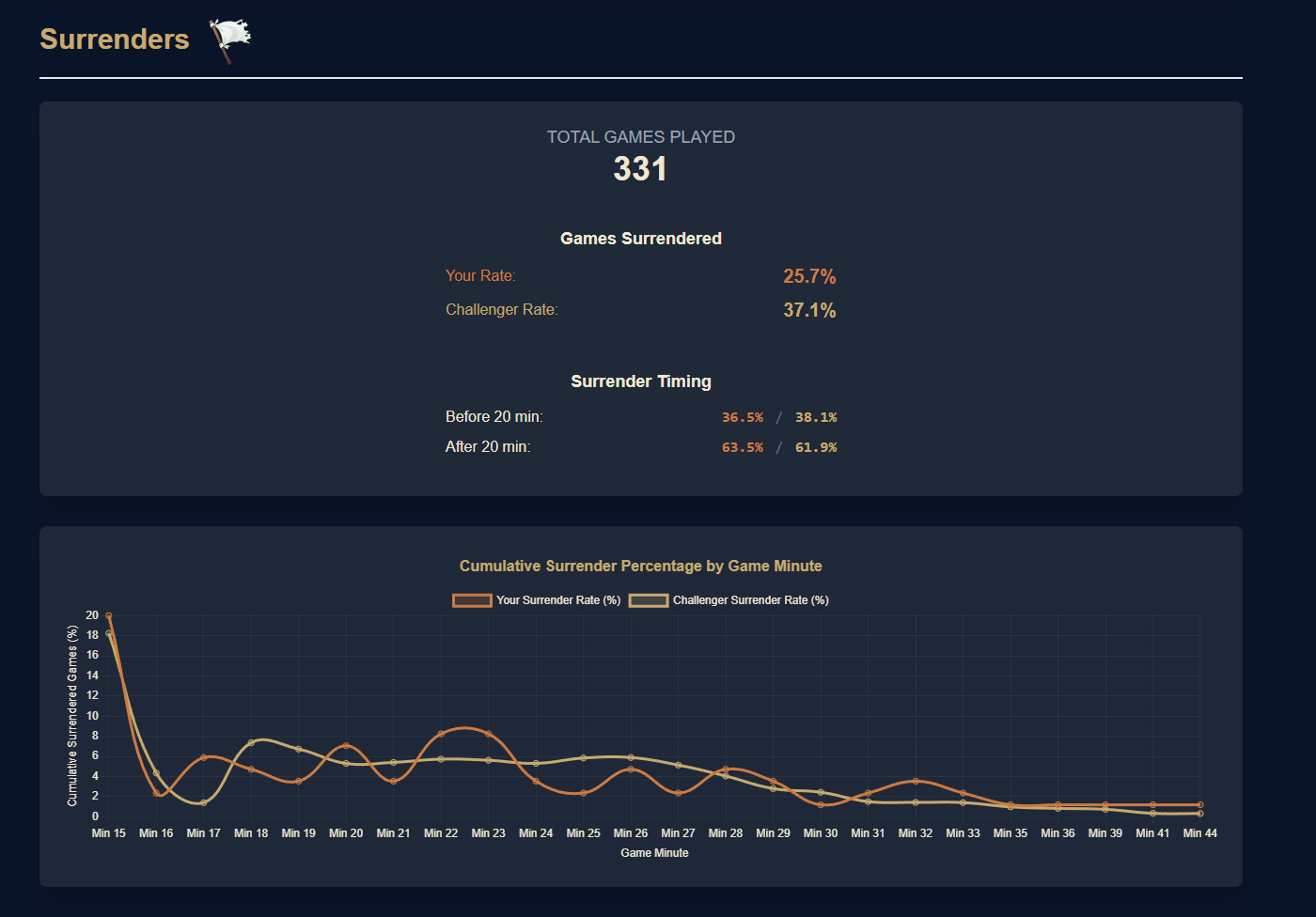
Surrender section
-
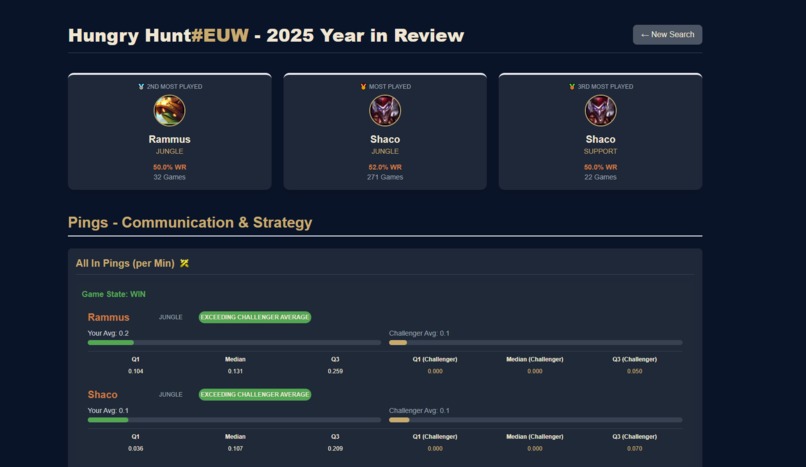
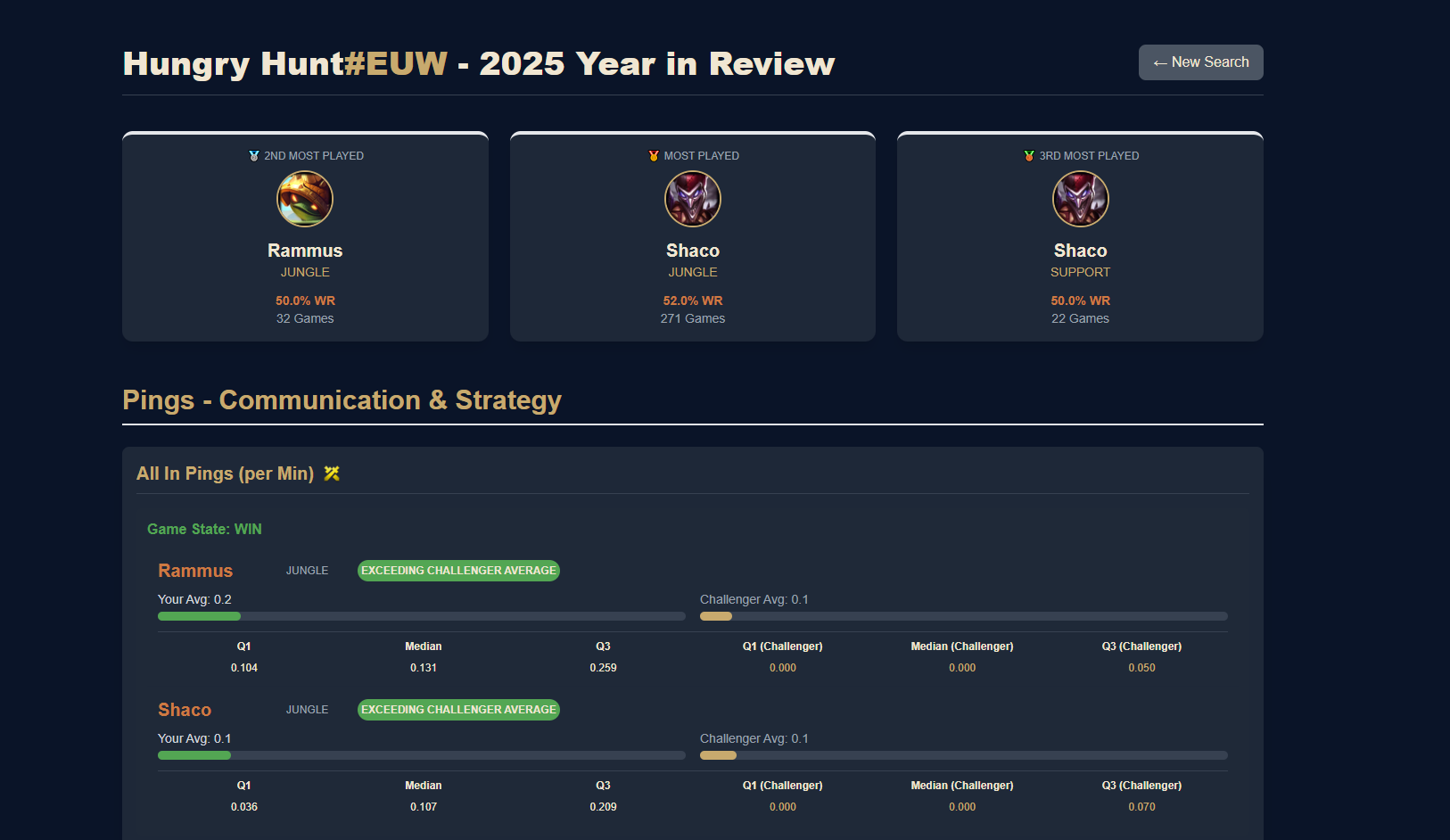
Most played champions and challenger comparison
-
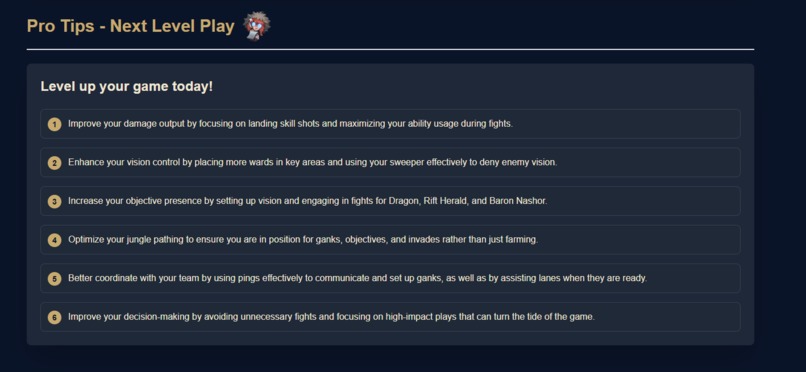
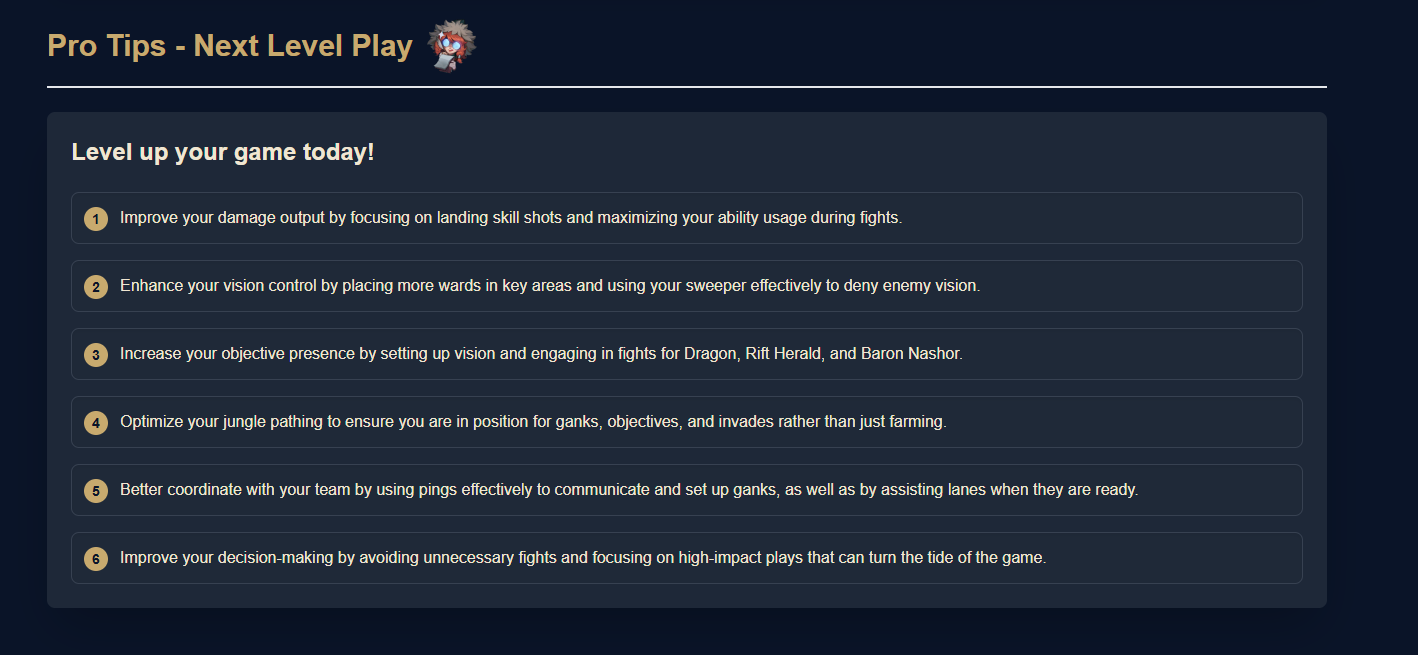
Pro tips from year review
-
Homepage
Inspiration
The main idea came from a website that was doing almost the same “year rewind.”
However, the goal of this project was not just to highlight my own successes — instead, we wanted to directly compare the areas of improvement that players should focus on.
We also included some fun facts, such as surrender patterns and average game durations.
Heads-up
Since the project use the basic Riot API Key, mock data have been tuned up.
The only accounts name accepted are my wifes and mine account :
- Hungry Hunt
- Happy Hunt
What it does
The main goal we set for ourselves was to allow every user to compare their performance throughout the year with those of the top players in the world — specifically, Challenger players on the EUW server.
Based on this data, users can directly compare themselves to the best players who play the same role and champion.
Due to the complexity of a League of Legends match, simply comparing overall results by role would not be meaningful. For example, comparing a tank support, an engage support, and an enchanter support would provide misleading information that wouldn’t help users improve effectively.
To ensure relevance, we compare the player’s three most-played champions for a specific role with the results of top Challenger players using the same champions and roles.
We also introduce granularity based on match outcomes — users can compare their statistics in wins versus losses, alongside those of Challenger players. This helps identify whether a player tends to underperform under pressure or lose focus after victories.
How we built it
The entire architecture was built on AWS, following the hackathon requirements.
Instead of using a traditional server-based architecture (with instances behind a load balancer, requiring network management, scaling policies, and image maintenance), we chose a fully serverless architecture for several reasons:
- Infinite scalability
- Low setup and operational costs
- Pay-as-you-go billing model
The decisive factor was the pay-as-you-go approach. Since the application’s purpose is to summarize a player’s entire year, the generated results remain identical on repeated usage — except for the advice section.
We estimated that an average user would use the platform no more than a dozen times per year.
Given that the League of Legends player base is finite, and not all players are interested in personal performance analysis, we expect usage spikes mainly during end-of-season periods, followed by lower traffic for the rest of the year. This usage pattern does not justify maintaining a 24/7 infrastructure.
Thus, we opted for a minimal yet sufficient architecture that fulfills our functional needs while keeping costs extremely low.
Website Hosting
The website is hosted on AWS S3, using static web hosting.
Users accessing the interface are served static assets (HTML, CSS, JavaScript, and images) stored in the S3 bucket.
Because the bucket is publicly accessible, it only contains essential files required for the website’s functionality.
Back-end
The web interface collects three inputs from users:
- Username
- Player Tag
- Region
These inputs trigger an AWS Lambda function, which:
- Retrieves user data from the Riot Games API
- Extracts and transforms key insights from a full year of match data
- Compares the user’s statistics with those of top Challenger players
- Sends areas of underperformance to Amazon Bedrock, which generates personalized advice using a specialized knowledge base
AI Components
We wanted to provide personalized recommendations for each player’s division, lane, and top three champions, ensuring highly tailored feedback.
To achieve this, we focused on designing a robust and cost-efficient knowledge base, implemented using AWS S3 Vector Buckets.
This solution was significantly cheaper than maintaining an OpenSearch Serverless cluster, which requires continuous compute resources.
The chosen model was Nova Lite 1.0, for the following reasons:
- Much lower cost per token than alternative models
- League of Legends performance advice is not a core training domain for most LLMs, meaning specialized knowledge had to come from our curated database
- By relying on a structured, well-designed knowledge base, we minimized the risk of model hallucination and ensured accurate, relevant advice
Our team’s expertise lies primarily in data processing and management, so we decided to focus our efforts on this aspect: understanding how to best leverage data to help players achieve their ultimate goal — reaching the highest ranks.
The project was divided into three main phases:
- Data collection
- Data exploration and insight extraction
- AWS architecture design
As in any data-driven project, data collection was the critical foundation. Without sufficient, relevant data, the entire project would have been at risk.
We collected data not only from Challenger players but also from top One-Trick Ponies (OTPs) across Europe to gain insight into how players specializing in a single champion achieve elite performance.
This was done through custom local scripts that ran for several days to harvest as much data as possible.
Because Riot API keys expire daily, the scripts were designed with checkpointing mechanisms — inspired by Apache Spark Streaming’s checkpoint system — to resume data extraction seamlessly after interruptions.
We focused our data analysis on the following key aspects:
- Communication: As League of Legends is a team game, assessing player communication is crucial. We analyzed the average use of various pings per match.
- KDA: Evaluating average kills/deaths/assists to benchmark expected performance.
- Damage Output: Measuring total damage dealt based on role and champion, covering champions, objectives (e.g., Dragon, Baron), and structures.
- Multi-kills: Tracking the frequency of double, triple, or higher kill streaks by champion and role.
- Game Duration: Comparing a player’s average match length (in wins and losses) with Challenger benchmarks for the same role.
- Surrender Patterns: Assessing player tendencies to surrender too early or too often, and comparing them to Challenger behavior to identify mental resilience gaps.
These metrics form a strong foundation for player improvement analysis and can be expanded in future iterations.
Our AI efforts focused primarily on developing a precise, practical knowledge base to answer a single question:
“How can a player become better?”
The knowledge base was built from three sources:
- Insights derived from our data exploration phase
- The in-game experience of our team members
- Coaching tips from reputable free online sources
We organized this knowledge by rank division, ensuring contextualized recommendations.
For instance:
- Iron/Bronze players should focus on CS (Creep Score) consistency and mechanical mastery of their champions.
- Emerald-level players should prioritize macro strategy and map awareness.
With this structured knowledge base and precise player data supplied by the Lambda functions, Nova Lite 1.0 delivers highly relevant and personalized improvement advice.
Challenges we ran into
Learning to use AI tools was a new but extremely rewarding experience. It allowed us to better understand their full potential and even consider continuing this project beyond the hackathon to further master these technologies.
This project is mostly data-centered. Since the project was developed by a single person, it was not possible to parallelize data downloads using multiple API keys. As a result, data collection consumed a considerable portion of the overall effort.
Accomplishments that we're proud of
- As a Data Engineer, building websites and user interfaces was not something I specialized in. Even if it was mostly “vibe-coded,” the front end is pretty acceptable for someone with no experience in this field.
- Being able to create a truly cost-efficient architecture that works.
- First experience with Bedrock topics — really cool stuff! It made me want to go deeper into the subject.
What we learned
We learned about AWS Bedrock, knowledge bases, and agents.
This opened our team to new perspectives and possibilities for both personal and professional projects.
We also learned that vibe coding has really become a thing, especially for quick web interfaces — and that some modern models are quite good at producing usable backbones.
What's next for Challenger Wannabe
- Better API key rate-limit management
- More efficient data processing — ideally computing insights in real time as data is received, instead of separating download and processing phases
- If the rate limit issue is solved, exploiting far more data at every division level, enabling players to compare themselves with peers, strengthen the knowledge base, and deploy specialized agents for different topics — leading to better recommendations
- Implementation of unit testing for robustness
- Creation of an infrastructure-as-code deployment with Terraform (planned but not completed due to time constraints)
- Purchase a domain name with Route 53 and map it to the S3 endpoint
- Add functionalities that weren’t finished in time for submission, such as:
- Spell usage frequency
- Grey screen duration
- Other fun features to make the experience more engaging than just statistics and improvement tracking
- Spell usage frequency
- Find a dude for the front end
Built With
- amazon-web-services
- bedrock
- lambda
- pyspark
- python
- s3

Log in or sign up for Devpost to join the conversation.