-
App cover [1]
-
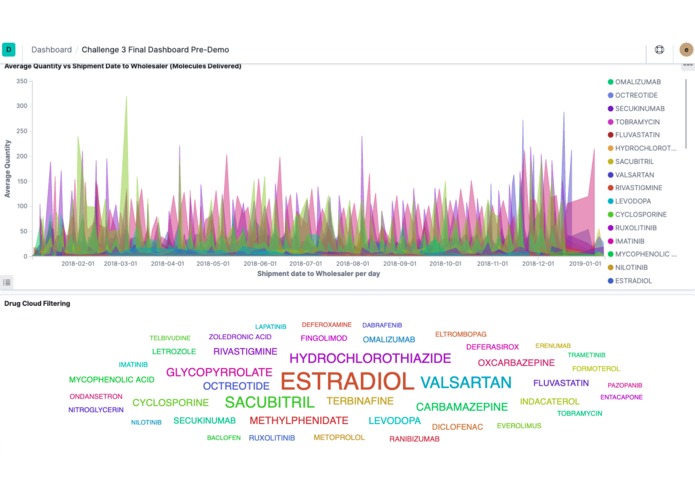
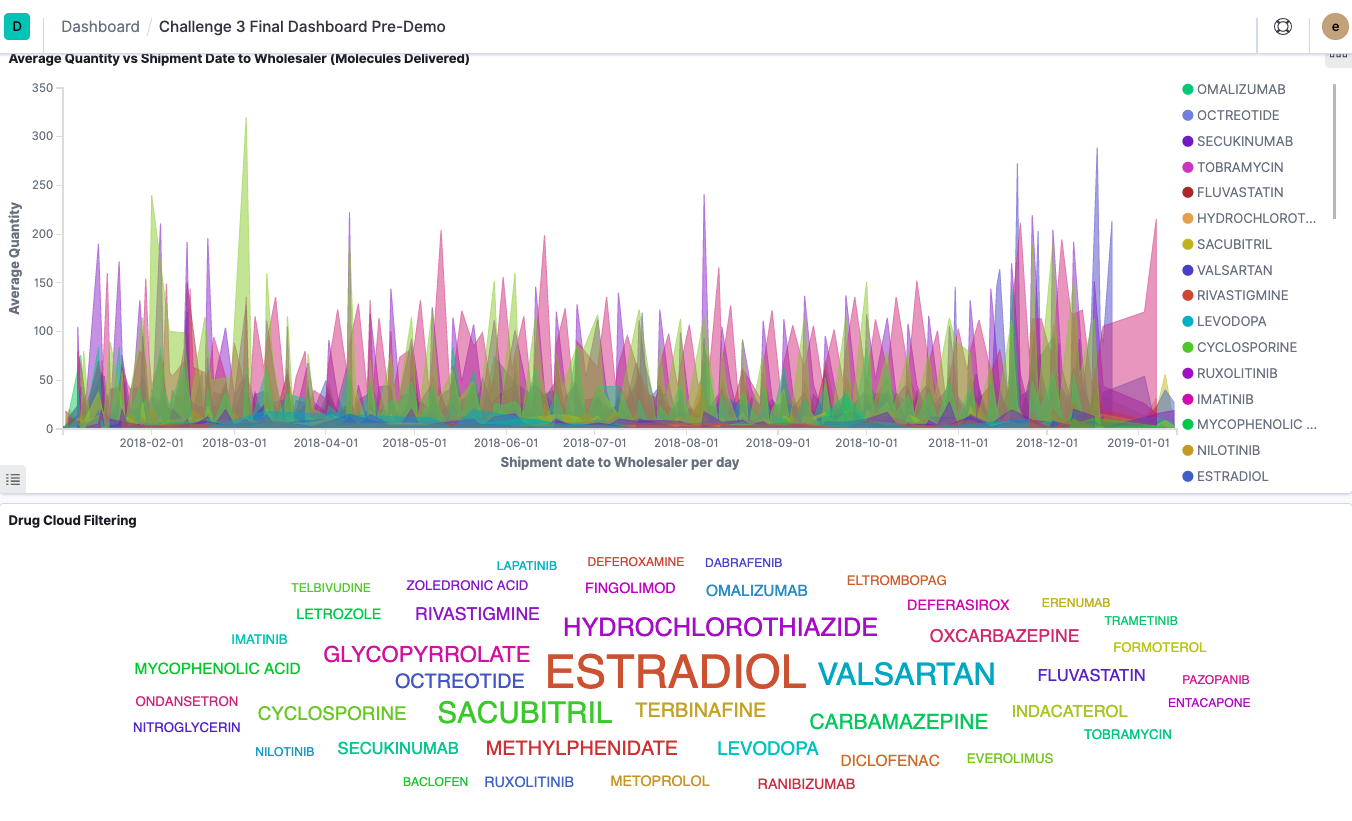
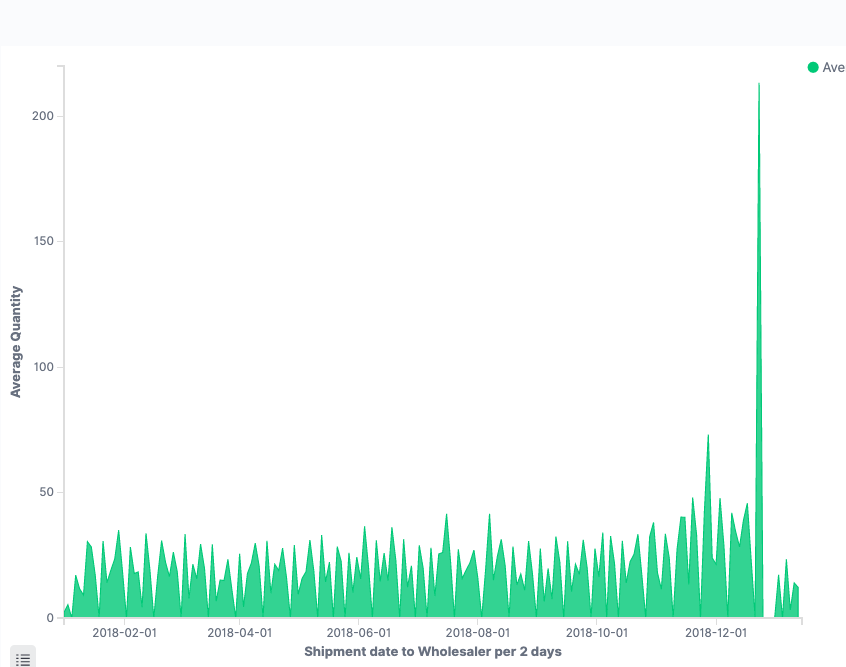
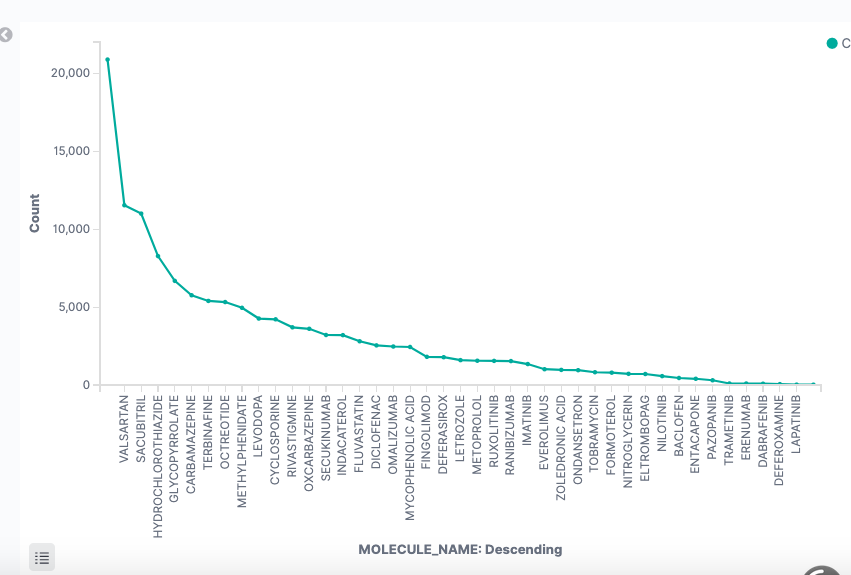
Visualization on average quantity on 69 given drugs over the time period [2018]
-
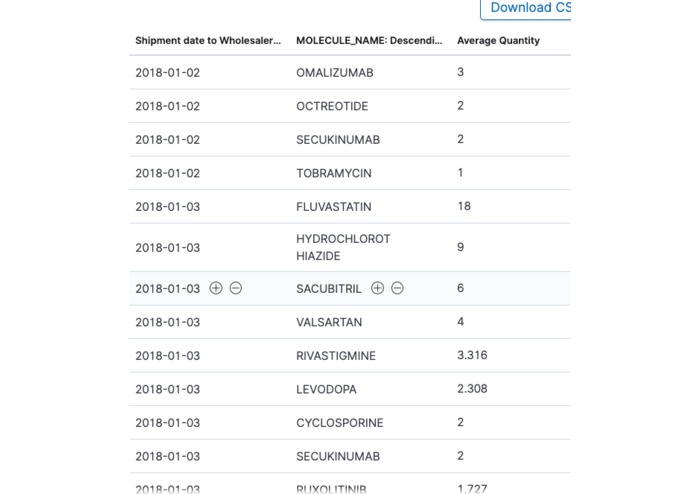
Compiled observations
-
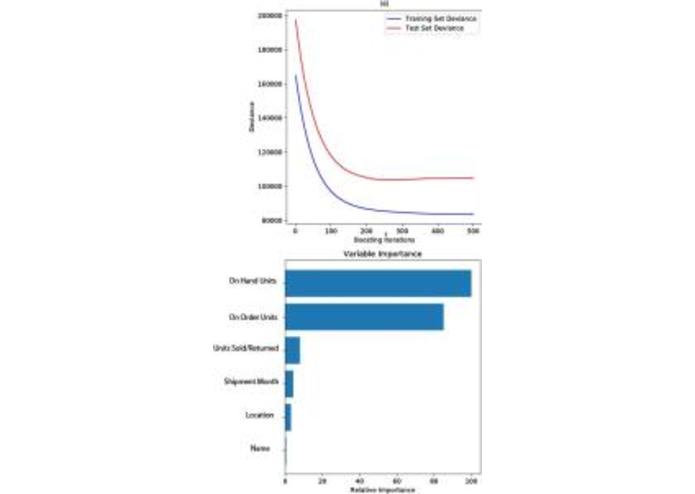
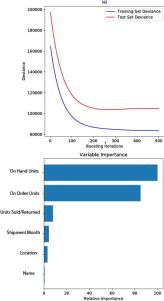
Output from Graident Boosting model combined with random forest and hyperparmeter
-
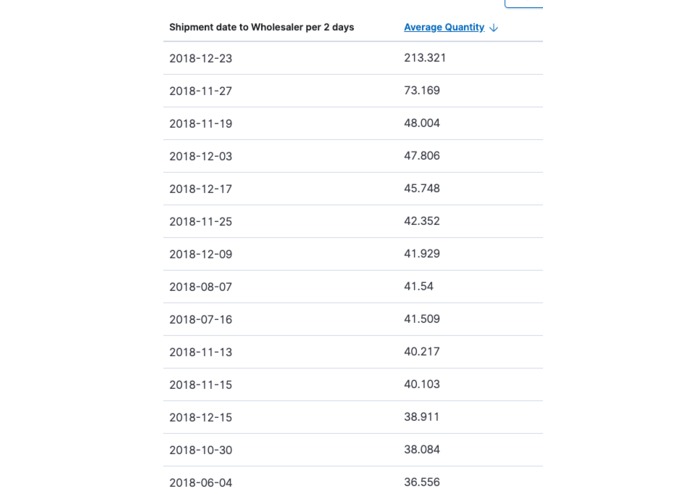
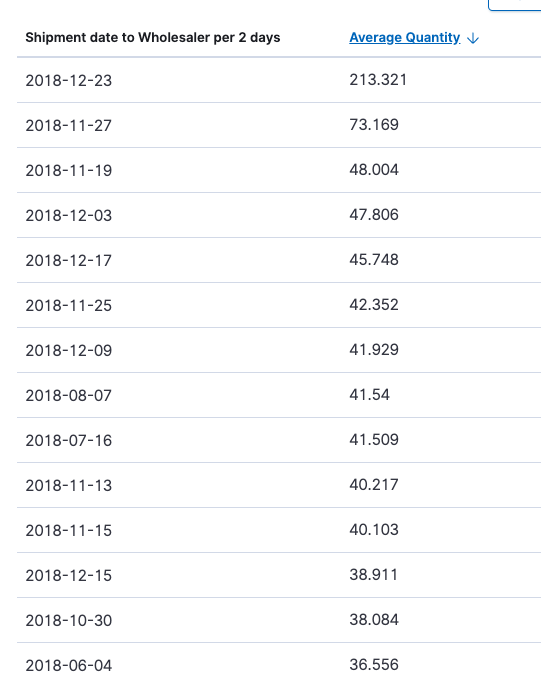
Outliers
-
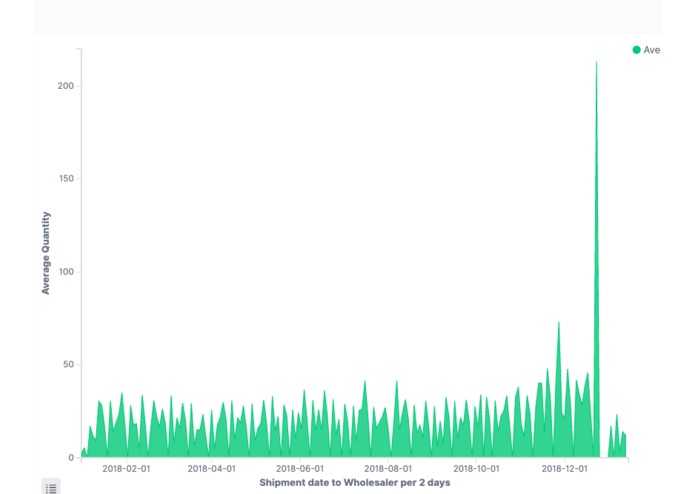
Shipment date to Wholesaler
-
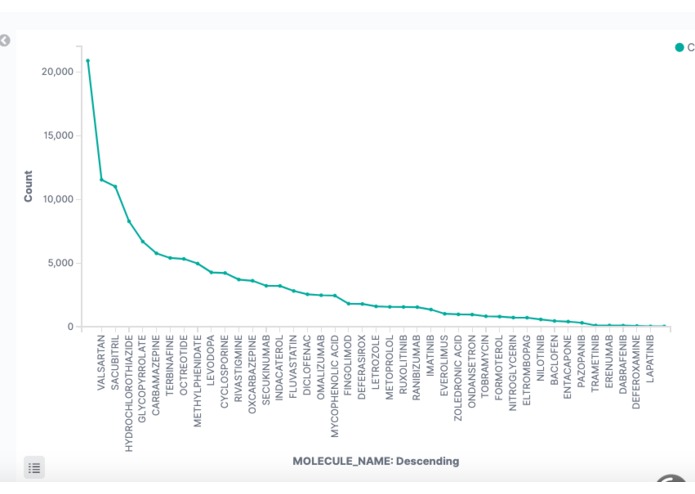
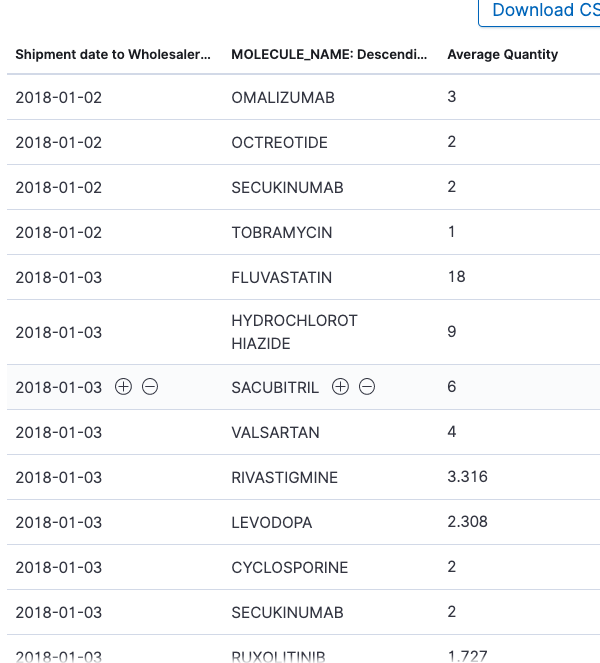
Molecule frequency distribution descending order
-
App menu [2]
-

App molecules [3]
-

App [4]
-
App [5]
-

ML Data Cleanup
-
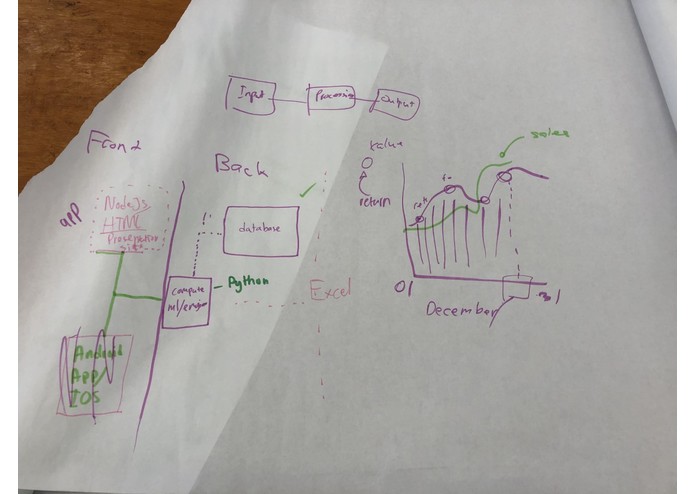
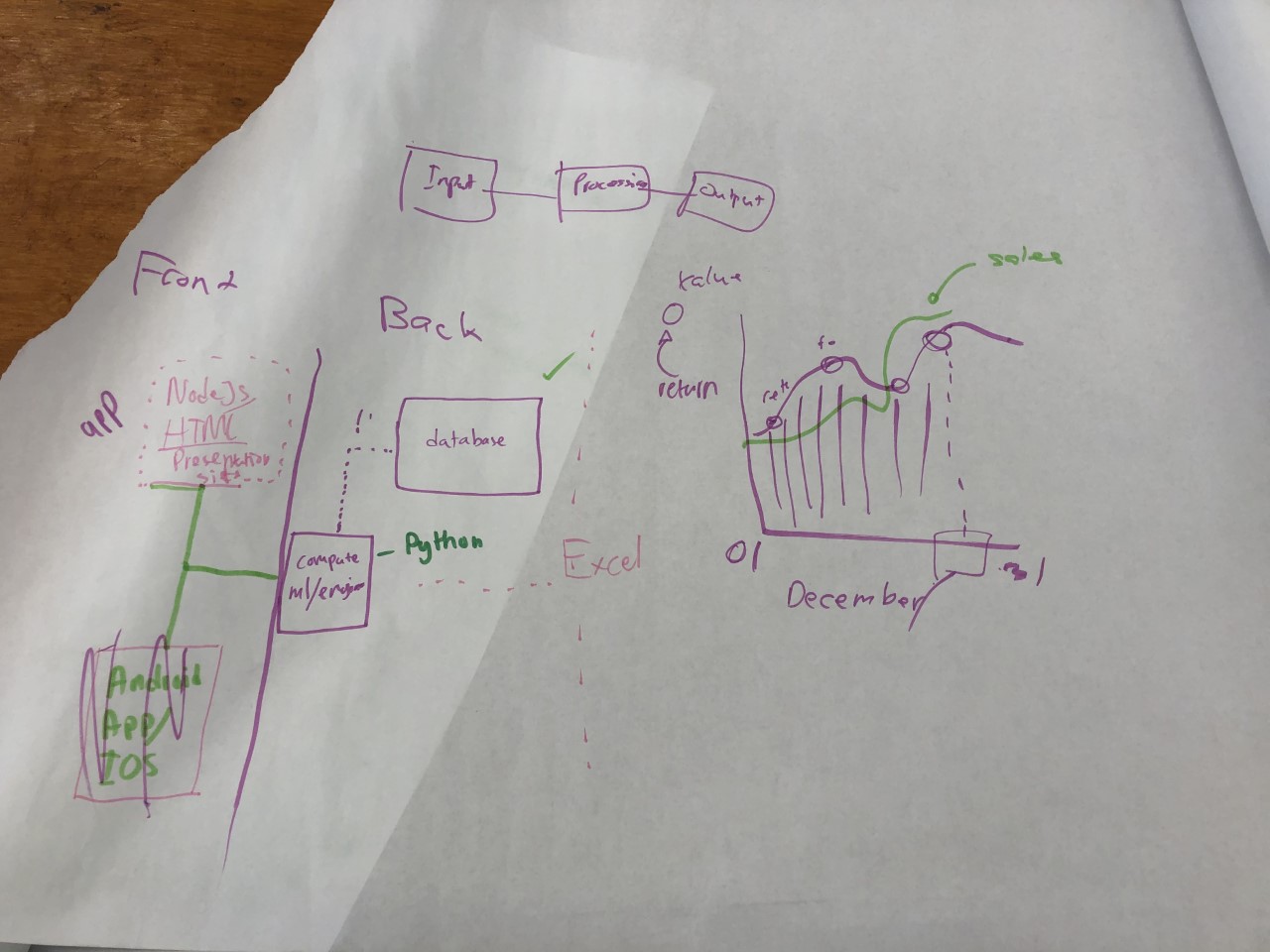
Architecture
-
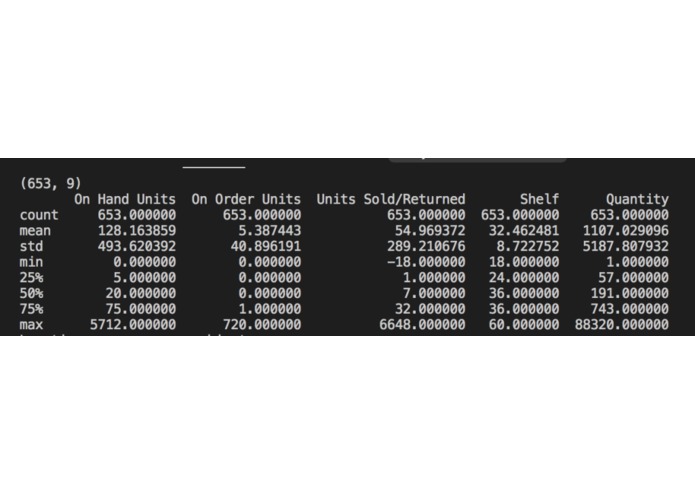
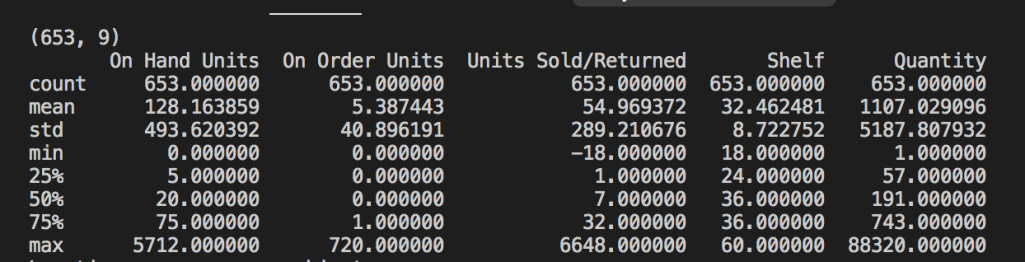
Pandas Inbuilt Stats, Note Outliers on the max side




PLEASE ASK FOR DASHBOARD ACCESS.
Inspiration
After the talk given by IB and Novartis, we are quite curious about the distribution route essential pharmaceutical take to get to retailers and patients, while keeping the drug's efficacy and potency in checks. Recalls on the product would be costly, and we wonder if we find any impacting variables that we can use to forecast supply chain fluctuation.
What it does
The .apk is a frontend to the prediction and is used a calculator to quickly get prediction on different batches or drug ids or molecules that may be lying around. Currently it connects to a private server that runs the machine learning computations and returns the predictive values or key metrics (Cost Analysis, Molecular Drug Historical Risk, etc)
The dashboard and visualizations describe the data and show the key metrics and aggregations that will help in building the correct models.
How we built it
We would like to aim for a more user-interaction oriented project, with the ease of both data collection and information presentation for the client. Thus we build an app inter-phase that will communicate with our own server running the modeling system in the background. Our modelling system uses Sklearn's machine learning algorithm, in particularly gradient boosting with random forest implementation, to optimize and find correlation among multiple variables within a large data set.
Challenges we ran into
Most of our team members are not familiar with the machine learning paradigm and how pharmaceutical works in Canada. We definitely learned a lot from each other and from the superiors that patiently answers our questions every day.
Accomplishments that we're proud of
To be able to finish most what we projected by the end of the competition, along with some crash course on pythons, pandas, sklearns, and machine learning on the spot. We also found some interesting data on the Health Canada website regarding the NOC dating back to 2012.
What we learned
We believe we just touched briefly on potential causation relationship among the variables given in this short period of time. We are interested in the brand conversion rate among customers when a generic drug launches. Also things definitely don't always go in the directions we expect! But we should still be happy with what we have achieved, and next time we will aim for the better
What's next for Challenge #3 - Supply Chain Management
We have found quite a lot of interesting data along the Health Canada database, and we hope to launch it on github soon
Log in or sign up for Devpost to join the conversation.