-
-

SMOTE
-

Discrimintating PCA Directions
-

Exploratory Data Analysis


Abstract:
During this hackathon, our team focused on developing a machine learning model by examining feature selection, addressing class imbalance, and assessing various algorithms. We commenced by normalising the data using Min-max scaling and employed four feature selection techniques: Pearson Correlation, Chi-Squared Test, Recursive Feature Elimination, and Lasso (L1) Regularization. With the help of ensemble based feature selection, we evaluated two feature selection strategies: a 63-feature union and a 31-feature intersection.
The dataset displayed significant class imbalance, which we tackled using the Synthetic Minority Over-sampling Technique (SMOTE). We investigated a variety of machine learning models, such as Logistic Regression, SVM, Naive Bayes, Stochastic Gradient Descent, k-Nearest Neighbours, Decision Trees, and ensemble methods like Random Forests, Gradient Boosting, AdaBoost, XGBoost, LightGBM with a sub-optimal hyper-parameters. We utilised cross-validation methods like the Leave One Out and Monte Carlo approach to identify the optimal model in each case.
Our findings revealed that the 63-feature strategy outperformed the 31-feature approach. Utilising this strategy with LeaveOneOut, we achieved the best performance with the XG model, exhibiting a precision of 0.833, recall of 1, MCC of 0.877, and an overall accuracy of 0.944. However, implementing SMOTE to manage class imbalance led to a decrease in model accuracy, indicating that the generated synthetic samples might not accurately represent the true distribution of the minority class.
Exploratory Data Analysis
Figure 1^ Figure 2^ Figure 3^
Feature Selection Approach:
Initially, we normalise data using the Min-Max scaling technique. Our team employed four sophisticated feature selection techniques to optimise our model for the hackathon: Pearson Correlation, Chi-Squared Test, Recursive Feature Elimination, and Lasso (L1) Regularization. We implemented two distinct strategies for selecting features. The first approach combined the features identified by all four methods, resulting in a comprehensive union. This yielded a total of 63 features. Alternatively, we selected only the features that were consistently recognized by all methods, creating an intersection of 31 features. Moving forward, we intend to rigorously compare these two approaches to determine the most effective feature selection strategy for our hackathon project.
Small Dataset Approach:
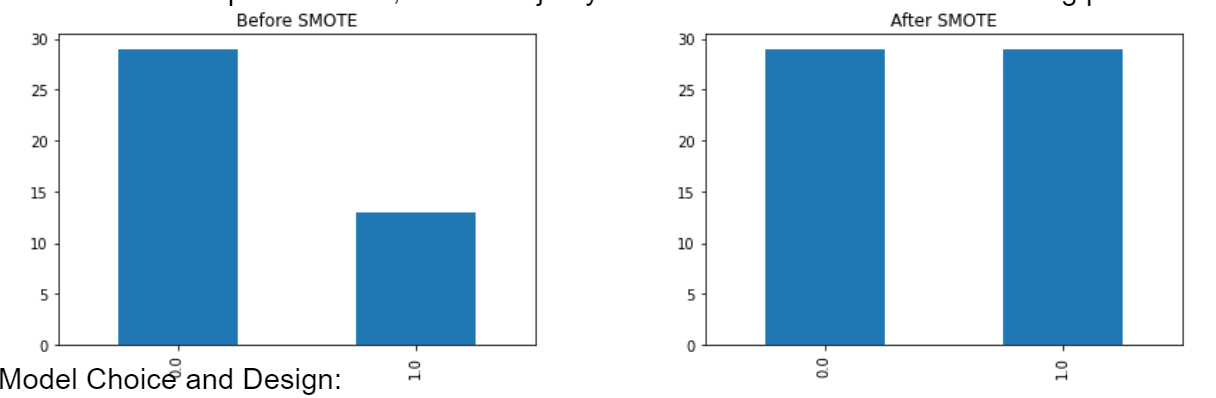
This dataset had a strong class imbalance. There were 29 data points under the threshold and 13 points over the threshold.The Synthetic Minority Over-sampling Technique (SMOTE) is a powerful method for addressing class imbalance in datasets. This imbalance
Figure 4 ^
Model Choice and Design:
Explored various basic Machine Learning models, such as LogisticRegression, SVC, GaussianNB, MultinomialNB, SGDClassifier, KNeighborsClassifier, DecisionTreeClassifier and ensemble based methods such as RandomForestClassifier, GradientBoostingClassifier, XGBClassifier. Implemented Cross Validation methods such as Leave One Out Approach and MonteCarlo to get the best model during the training.
Model Performance:
Upon executing various models utilising the 63 features (a comprehensive union of all selected features), we achieved notable results. However, when applying the alternate strategy that employed only the 31 intersecting features, the model performance was significantly inferior. Due to the unsatisfactory outcomes associated with the 31-feature approach, we have chosen not to include these findings in the present report. Instead, we will focus on the insights gained from the more promising 63-feature methodology, which demonstrates the importance of thorough feature selection in optimising model performance.
LeaveOneOut
| Model Name | Precision | Recall | MCC | Accuracy |
|---|---|---|---|---|
| Logistic Regression | .385 | 1 | .385 | .556 |
| SVC | .4 | .8 | .305 | .611 |
| GaussianNB | .294 | 1 | .15 | .333 |
| Multinomial NB | .4 | .4 | .169 | .667 |
| SGDClassifier | .417 | 1 | .439 | .611 |
| KNeighborsClassifier | .273 | .6 | -0.014 | .444 |
| DecisionTreeClassifier | .571 | .8 | 0.523 | .778 |
| RandomForestClassifier | .833 | 1 | .877 | .944 |
| GradientBoostingClassifier | .429 | .6 | .269 | .667 |
| XGBClassifier | .833 | 1 | .877 | .944 |
| AdaBoost | .75 | .6 | .564 | .833 |
| LightGBM | .75 | .6 | .564 | .833 |
| Voting Classifier | .429 | .6 | .269 | .667 |
MonteCarlo
| Model Name | Precision | Recall | MCC | Accuracy |
|---|---|---|---|---|
| Logistic Regression | 0.417 | 1.0 | 0.439 | 0.611 |
| SVC | 0.444 | 0.8 | 0.372 | 0.667 |
| GaussianNB | 0.294 | 1.0 | 0.15 | 0.333 |
| Multinomial NB | 0.385 | 1.0 | 0.385 | 0.556 |
| SGDClassifier | 0.417 | 1.0 | 0.439 | 0.611 |
| KNeighborsClassifier | 0.333 | 0.8 | 0.175 | 0.5 |
| DecisionTreeClassifier | 0.385 | 1.0 | 0.385 | 0.556 |
| RandomForestClassifier | 0.75 | 0.6 | 0.564 | 0.833 |
| GradientBoostingClassifier | 0.556 | 1.0 | 0.62 | 0.778 |
| XGBClassifier | 0.714 | 1.0 | 0.777 | 0.889 |
| LightGBM | 0.714 | 1.0 | 0.777 | 0.889 |
| VotingClassifier | 0.571 | 0.8 | 0.523 | 0.778 |
XGB Model Performance with or without SMOTE:
While we attempted to address the imbalanced dataset using the Synthetic Minority Over-sampling Technique (SMOTE), our efforts resulted in an unexpected reduction in model accuracy. This outcome can be attributed to the generation of synthetic samples, which may not effectively represent the true underlying distribution of the minority class.
NOTE: PPT is uploaded in GitHub.
Built With
- keras
- python-package-index
- scikit-learn
- tensorflow

Log in or sign up for Devpost to join the conversation.