-
-

-
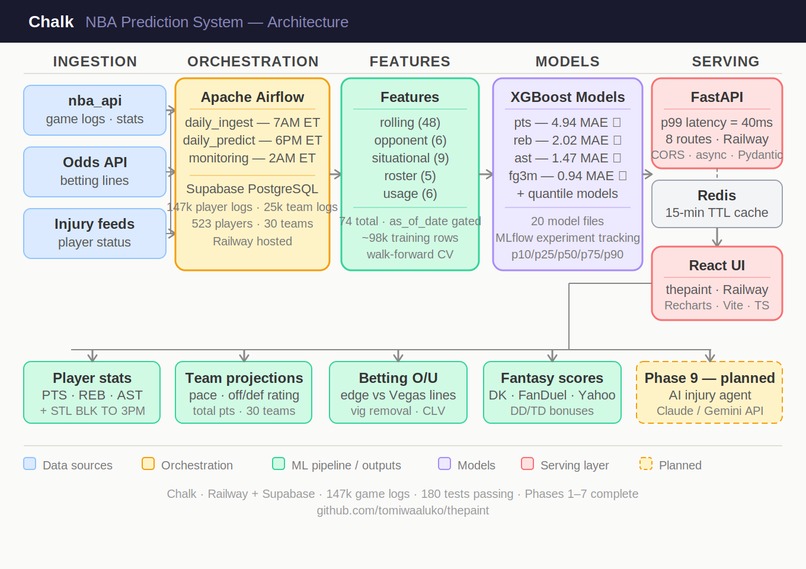
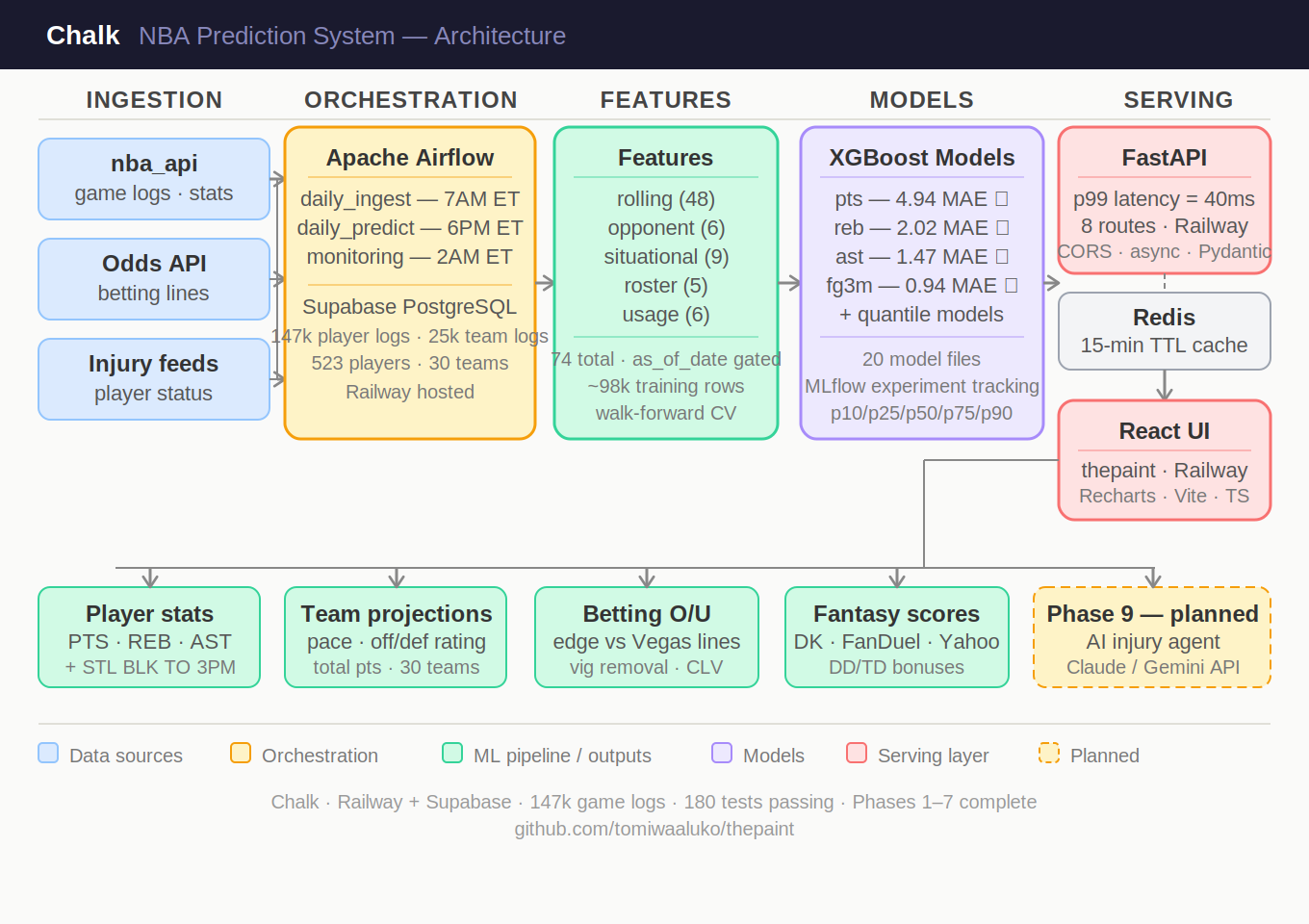
System Design
-
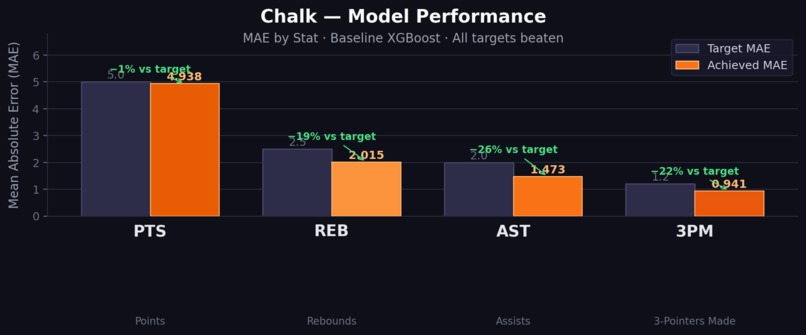
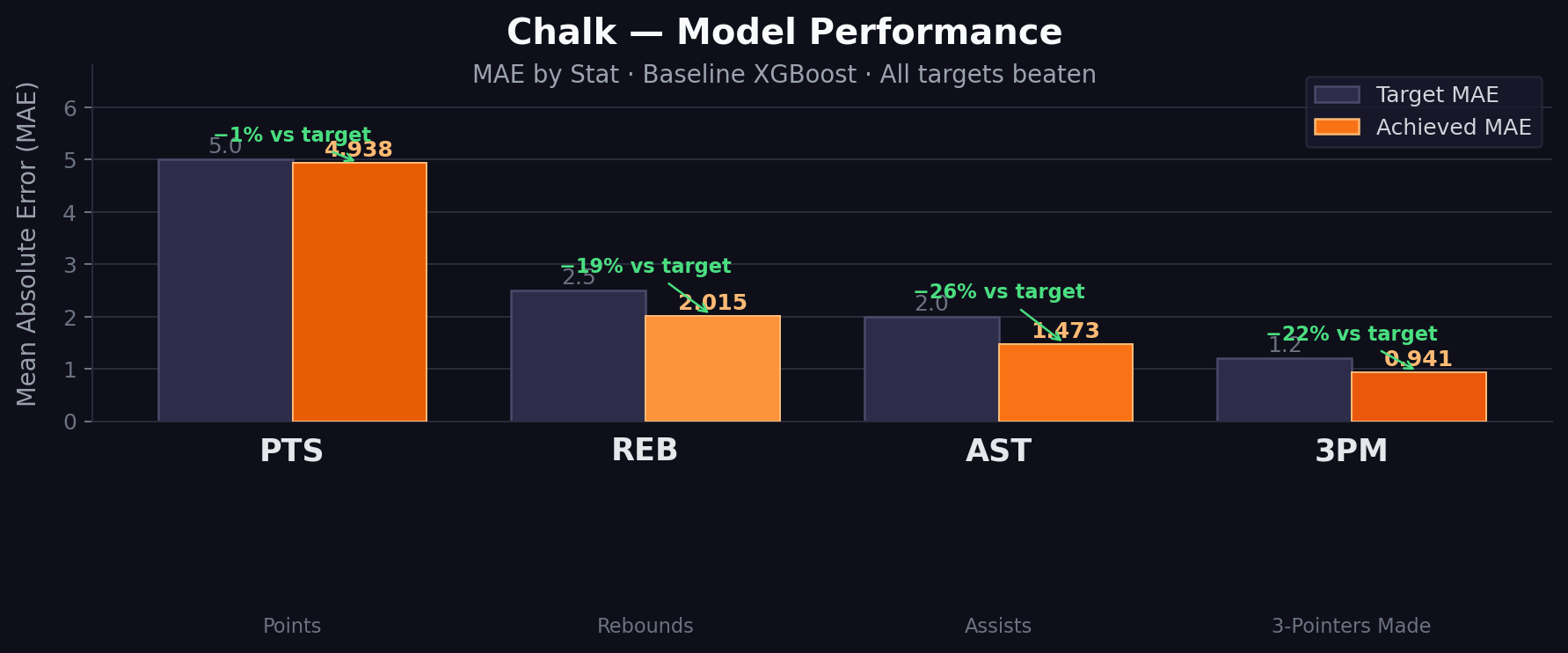
-

Disclaimer


Inspiration
I wanted to build Chalk because, honestly, I like sports betting. I wanted to mix my software engineering skills with something I already care about: following the NBA and placing bets on games. I’m not an addict — I bet recreationally, sporadically, and responsibly — but I thought it would be cool to have an app that could enhance my betting experience instead of relying only on gut feel and headlines.
I also wanted a serious project where I could learn machine learning hands-on: not just tutorials, but a real pipeline from raw data to predictions I could actually use.
What it does
Chalk predicts NBA statlines at both the player and team level. It produces:
- Player projections for points, rebounds, assists, steals, blocks, turnovers, threes, and efficiency-related stats
- Team-level game projections (pace and scoring context)
- Probability-oriented outputs for over/under style decisions
- Fantasy scoring projections across major scoring formats
The goal is to turn raw data into decision-ready outputs for game analysis, fantasy lineup building, and props research.
How I built it
Chalk is a full-stack ML system with separate ingestion, modeling, and serving layers:
- Backend/API: Python + FastAPI (async), with structured routes for players, teams, games, props, and fantasy
- Data layer: PostgreSQL (with async SQLAlchemy) + Redis caching
- Ingestion: NBA game/injury pipelines with retry/backoff, normalization, and idempotent upserts
- Modeling: XGBoost and LightGBM stat models, walk-forward time-series validation, and quantile-based uncertainty outputs
- Frontend: React + TypeScript dashboard for slate views, player cards, props boards, and fantasy value surfaces
- Ops: Dockerized services and scheduled production jobs for daily ingest/prediction refreshes
A key rule in the pipeline is that features only use data from before the game you’re predicting — so the model isn’t accidentally “cheating” with future information.
Challenges I ran into
Some of the hardest parts weren’t fancy math — they were patience and operations:
- Pulling all that historical data took forever. I set a wide date range for NBA games so the models would have enough history to learn from. Ingesting season after season of games and stats was slow, and I had to wait through long runs and sometimes debug why a batch stalled or failed.
- Keeping the live app fed on a schedule. I run separate scheduled jobs on Railway for daily ingest (pull new games, injuries, etc.) and for prediction updates. Getting those cron jobs reliable — right timing, right environment, not crashing when something upstream hiccups — took iteration.
- When the data source is flaky. The NBA’s public data doesn’t always cooperate: timeouts, odd responses, names spelled differently than you expect. I had to add retries, fallbacks, and a lot of “make this name match this player” logic so injuries and rosters don’t break the pipeline.
- Learning ML the honest way. Sports prediction is easy to get wrong if you accidentally let future games leak into training. I spent real time on validation and on building features that only use information you’d have had before tipoff.
I also learned that solid data and a clear process often beat tweaking models at random — especially when you’re the only one maintaining the whole thing.
Accomplishments I’m proud of
- Shipped a true end-to-end pipeline (ingest → features → train → predict → API → dashboard) as a solo dev
- Got strong error metrics on core player stats with API responses that feel fast enough to use
- Added more than single-number predictions — uncertainty and fantasy-style outputs too
- Built something I can extend as I learn more ML and add new markets or stats
What I learned
- If your training data sneaks in future information, your scores look amazing and your real-world results won’t — so boundaries matter
- Making external data pipelines reliable (retry, clean names, don’t double-insert junk) is half the battle
- You don’t need the fanciest model on day one; good features and honest validation go a long way
- The product isn’t just the model — it’s fresh data, a usable API, and a dashboard that actually answers “what should I look at tonight?”
What's next for Chalk
- Track how my edges compare to closing lines over time
- Wire up more odds sources and smoother retraining on a cadence I can maintain solo
- Surface why a line moved (injuries, usage, matchup, pace) in plain language
- Keep improving how confident the numbers feel on real, in-season games
Built With
- docker
- fastapi
- lightgbm
- mlflow
- nba-api
- pandas
- postgresql
- python
- railway
- react
- recharts
- redis
- scikit-learn
- sqlalchemy
- typescript
- xgboost



Log in or sign up for Devpost to join the conversation.