Inspiration
As a developer working with RAG-LLM systems, I felt that the ways in which they were often implemented resulted in excess calls being made. See, modern AI systems even at small scales, but especially with larger businesses (35% of Fortune 500) increasingly rely on multi-step pipelines, where a single task is broken into many LLM calls to improve output quality. While effective, this approach introduces significant inefficiency. Redundant prompts, repeated context, and unnecessary formatting steps all increase cost, latency, and energy usage. I was interested in whether these pipelines could be automatically simplified without sacrificing output quality, and what impact that could have at scale. A basic calculation of current business LLM usage suggests that a reduction of calls by 20% across even just half of these businesses would result in enough energy being saved to power ~4,000 households for a year.
What it does
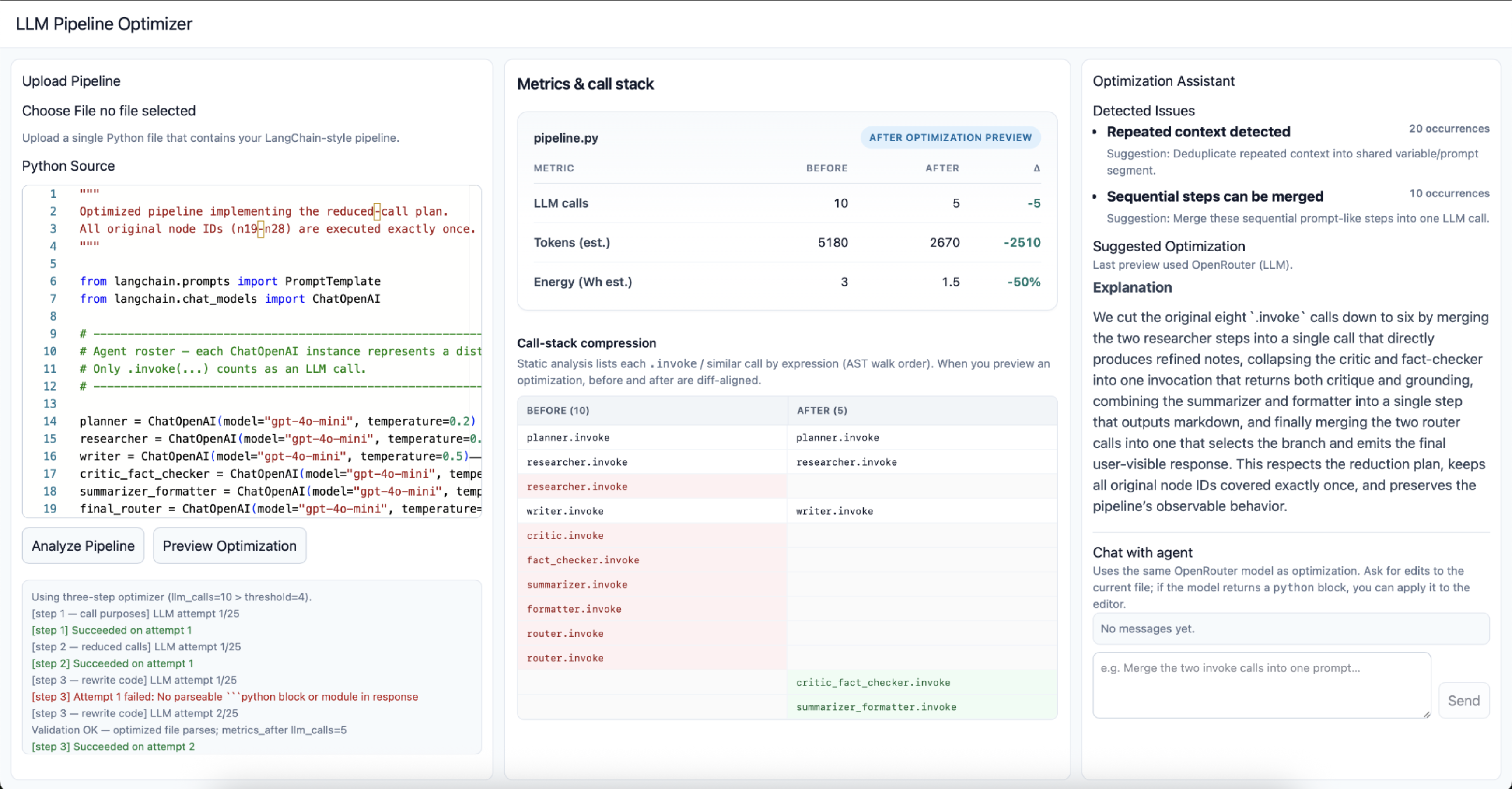
ChainOpt is a tool that analyzes LLM pipelines and automatically optimizes them by reducing redundant model calls. Users can upload a Python file containing a LangChain-style pipeline, and ChainOpt will:
- Parse and extract the pipeline structure
- Identify inefficiencies (such as mergeable or redundant steps)
- Generate an optimized version of the code
- Show a preview diff of changes before applying them
- Display before/after metrics, including call count, token estimates, and energy usage The result is a streamlined pipeline that performs the same task with significantly fewer LLM calls. This leads to lower cost, faster return time, and above all, less environmental waste due to energy usage.
How we built it
I built ChainOpt using a full-stack approach:
- Frontend: React (Vite), TypeScript, Tailwind CSS, and shadcn/ui for a clean and responsive interface. Monaco Editor was used to display and interact with code.
- Backend: FastAPI (Python) handled file uploads, parsing, and optimization logic.
- Pipeline Analysis: I used Python’s AST module to extract a simplified representation of the pipeline from user-provided code.
- Optimization Engine: An LLM was used to interpret pipeline steps and generate a rewritten, optimized version by merging sequential prompts and removing redundant transformations.
- Metrics Engine: ChainOpt then estimated improvements by tracking LLM call counts and approximating token and energy usage. The system follows a structured workflow: upload → parse → analyze → optimize → preview → apply → repeat
Challenges we ran into
One of the biggest challenges was dealing with the flexibility of real-world LLM pipelines. LangChain code can be highly dynamic, making it difficult to reliably parse and understand using static analysis. We addressed this by narrowing our scope to sequential pipelines and building a simplified intermediate representation.
Another challenge was ensuring that optimizations did not break the intended behavior of the pipeline. Since we cannot perfectly verify semantic equivalence, we focused on high-confidence transformations (like merging sequential prompt steps) and added a preview + accept workflow to keep the user in control.
We also initially experimented with graph-based visualizations, but found they added complexity without improving clarity. Redesigning the UI to focus on before/after comparisons and metrics significantly improved usability.
Accomplishments that we're proud of
- Successfully built a working system that can analyze and rewrite real LLM pipelines
- Achieved significant reductions in LLM calls (often 25–45%) in test cases
- Created a clean, developer-friendly interface with code diff previews
- Designed a clear and compelling way to visualize optimization impact
- Scoped the project effectively to deliver a polished, end-to-end demo within a hackathon timeframe
What we learned
I learned that optimizing LLM systems is less about improving models and more about improving how they are used. Small inefficiencies in pipeline design compound quickly at scale. To put it into perspective, the 25-45% energy reduction per task, scaled up to an industry level for one company at the Fortune 500 scale could translate to saving hundreds of gigawatt-hours annually—equivalent to powering tens of thousands of homes.
I also learned the importance of scoping: trying to support all possible pipeline structures is unfeasible, but focusing on common patterns can still deliver meaningful results.
On the technical side, I gained experience combining static analysis (AST parsing) with LLM-based reasoning, and learned how to design systems where AI assists rather than replaces deterministic logic.
What's next for ChainOpt
Next, I want to expand ChainOpt beyond simple sequential pipelines to support more complex workflows, including branching and tool-based agents.
I am also interested in:
- Improving accuracy of optimizations and validating output quality
- Integrating directly with frameworks like LangChain as a drop-in optimization layer
- Adding real-time optimization during development (e.g., IDE integration)
- Refining metrics with more precise cost and energy modeling While this project used a visual component for clarity, I ultimately see ChainOpt evolving into a “compiler layer” for AI systems—automatically making them more efficient without requiring developers to change how they build them.
Built With
- fastapi
- gemini
- nvidia-nemotron
- python
- python-ast
- react
- tailwind
- tailwind-css
- typescript

Log in or sign up for Devpost to join the conversation.