-
-

-
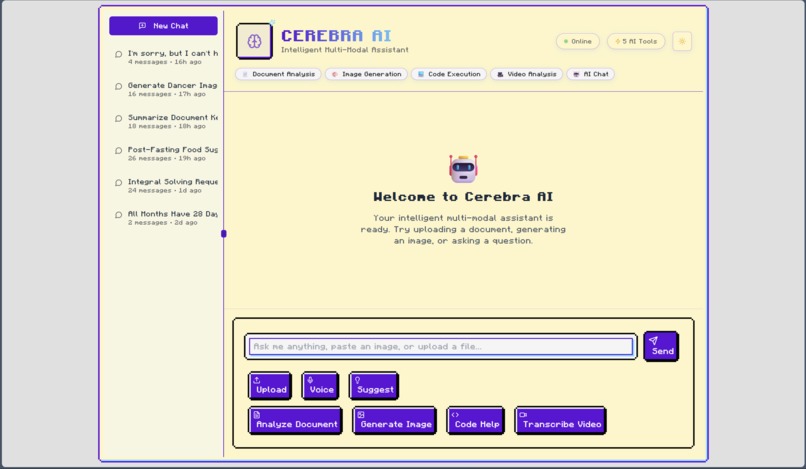
CEREBRA-AI UI

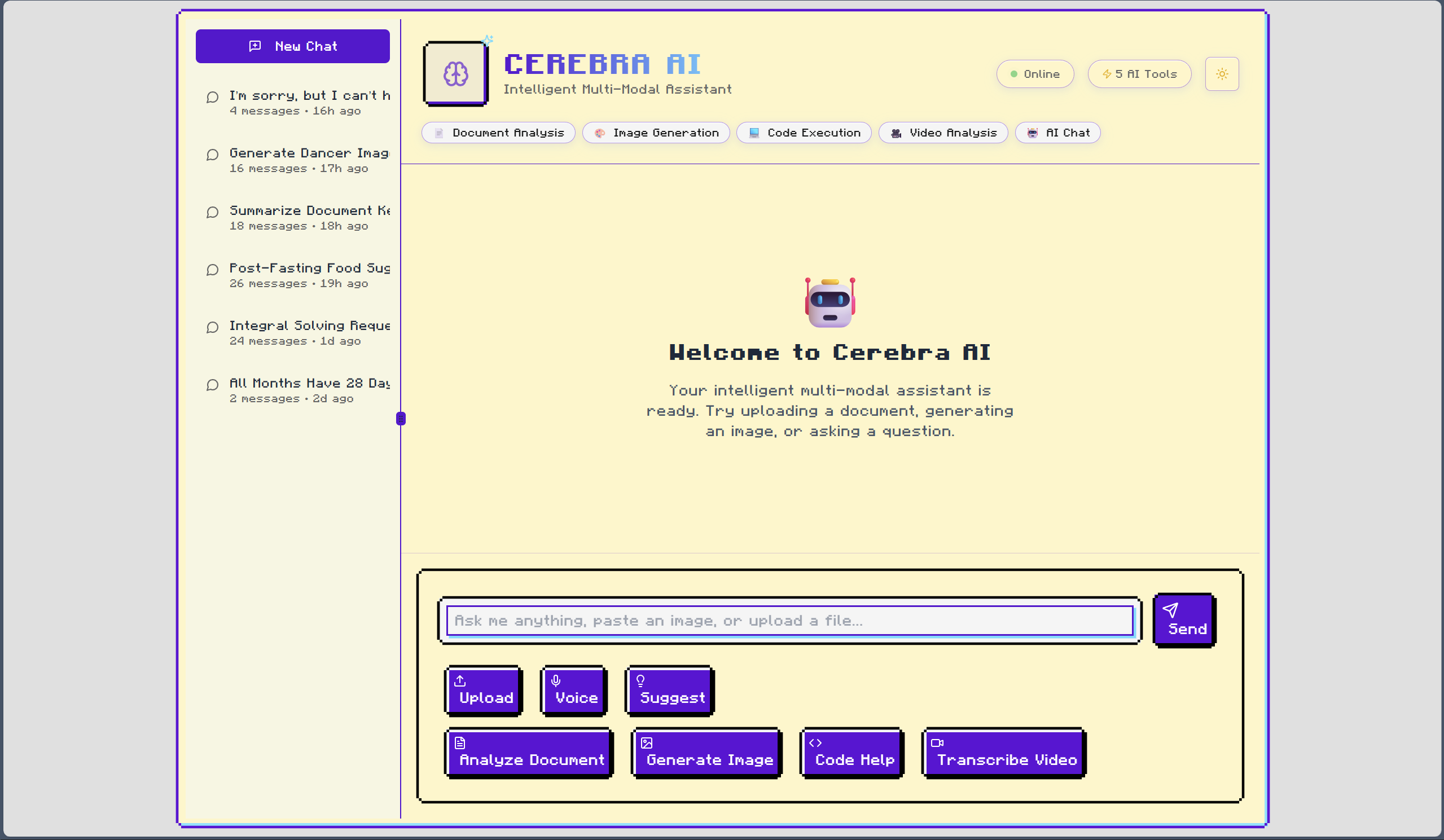
Inspiration
In a world filled with AI chatbots, I noticed a fundamental limitation: most are one-trick ponies. You use one tool for text, another for images, and a third for coding help. This fragmented experience forces the user to be the "intelligent router," constantly switching contexts and tools. My inspiration for Cerebra AI came from a simple question: What if an AI assistant could be more like a human expert, capable of understanding a complex request and then delegating it to the right specialist? I wanted to build an AI that doesn't just respond, but thinks before it acts.
What it does
Cerebra AI is a powerful, locally-runnable, full-stack application that functions as an intelligent, multi-modal assistant. At its core, it's a sophisticated chat application, but its real power lies in its backend AI Router. This router analyzes user prompts and dynamically selects the best tool for the job from a suite of specialized plugins:
- 🧠 General Chat: Engages in conversation using a local LLM via Ollama.
- 📄 Document Analysis: Allows users to upload PDFs and ask complex questions about their content.
- 🎨 Image Generation: Integrates with a running ComfyUI instance to generate high-quality images from text prompts.
- 👁️ Vision Analysis: Users can upload images and have the AI describe or answer questions about them.
- 🎬 Video & Audio Transcription: Utilizes OpenAI's Whisper to provide transcriptions and summaries of media files.
- 💻 Safe Code Execution: A dedicated plugin allows the AI to write, execute, and debug Python code in a sandboxed environment to solve complex problems.
The entire experience is wrapped in a sleek, responsive frontend with persistent chat history, giving users a single, powerful interface for all their AI-driven tasks.
How I built it
Cerebra AI is built with a decoupled architecture, ensuring scalability and maintainability.
The Backend is a robust FastAPI application written in Python. Its central nervous system is the AI Router, which uses an LLM call to classify the user's intent and required parameters. Based on the classification, it routes the request to the appropriate plugin. I used SQLAlchemy with SQLite for persistent, session-based chat history, and Pydantic for rigorous data validation. For the AI functionalities, I integrated several powerful open-source tools:
- Ollama for running local LLMs (like Llama 3).
- OpenAI Whisper for high-accuracy audio transcription.
- An API client to connect to a separate ComfyUI instance for state-of-the-art image generation.
- A custom-built, secure code execution environment using Python's
subprocessmodule.
The Frontend is a modern single-page application built with React and TypeScript, bundled with Vite. We focused heavily on user experience, creating a responsive and intuitive chat interface using a combination of shadcn/ui, Tailwind CSS, and the unique pixel-retroui library for a distinctive aesthetic. All state management and server communication are handled efficiently by TanStack React Query. The entire frontend is deployed on Vercel for fast, global access.
Challenges I ran into
One of the biggest challenges was designing the AI Router. Prompt engineering was key here; we had to create a prompt that could reliably classify user intent and extract structured JSON output from the LLM, even with varied and ambiguous inputs.
Another significant hurdle was asynchronous task handling in FastAPI. Processing a video transcription or a complex document analysis can take time. I had to structure my application to handle these long-running tasks without blocking the server, which involved learning the nuances of Python's asyncio and ensuring our file handling and API calls were non-blocking.
Finally, ensuring robust error handling between the frontend and the multi-part backend was complex. With so many services (FastAPI, Ollama, ComfyUI, Whisper), I had to implement comprehensive health checks and clear error messaging on the frontend to inform the user when a specific part of the AI's "brain" was unavailable.
Accomplishments that I am proud of
I am incredibly proud of the AI Router. It's the core of what makes Cerebra AI special. Seeing it correctly interpret a vague user request and select the right tool, like triggering the image generation plugin when a user says "Show me a picture of..." is incredibly rewarding.
I am also proud of creating a fully local, private AI workspace. In an era of cloud-based everything, building a powerful tool that respects user privacy by running on their own machine feels like an important accomplishment.
Finally, the seamless integration of so many different AI models and tools into a single, cohesive application is something we worked hard to achieve.
What I learned
This project was a deep dive into the practicalities of building with modern AI tools. I learned that the real power of LLMs isn't just in generating text, but in using them as a reasoning engine to orchestrate other tools. This "LLM as a router" pattern is something I believe will be fundamental to the next generation of AI applications.
I also gained significant experience in full-stack development, from designing a REST API with FastAPI to building a responsive and state-managed frontend with React. Most importantly, I learned the value of modularity; by designing each AI capability as a separate "plugin," we've made the system incredibly easy to extend in the future.
What's next for Cerebra AI
The modular design of Cerebra AI opens up a world of possibilities. My immediate next steps are focused on expansion and refinement:
- Deploying the Full Backend: Package the FastAPI backend and its dependencies into a Docker container for easy, one-click deployment on platforms like Render or a home server.
- Adding More Tools: I plan to add new plugins, such as a web search tool for real-time information and a tool for summarizing web articles from a URL.
- Streaming Responses: Implement streaming for LLM responses to make the chat feel more interactive and instantaneous.
- Enhanced Memory: Improve the long-term memory of the assistant, allowing it to recall information from previous conversations to provide a more personalized experience.
Built With
- aiofiles
- carousel
- comfyui
- css
- embla
- fastapi
- git
- lucide
- ollama
- pixel-retroui
- postcss
- pydantic
- python
- python-dotenv
- pytorch
- react
- recharts
- shadcn/ui
- sonner
- sqlalchemy
- sqlite
- tanstack
- transformers
- typescript
- uvicorn
- vercel
- vite
- whisper


Log in or sign up for Devpost to join the conversation.