-
-
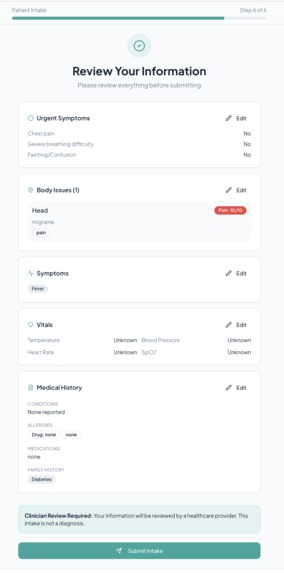
Review of Intake Form - Patient Side
-
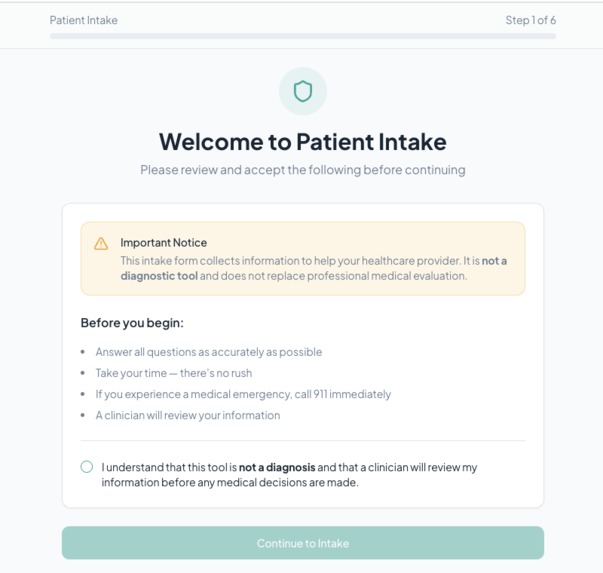
Start of Intake Form (in clinic submission) - Patient Side
-
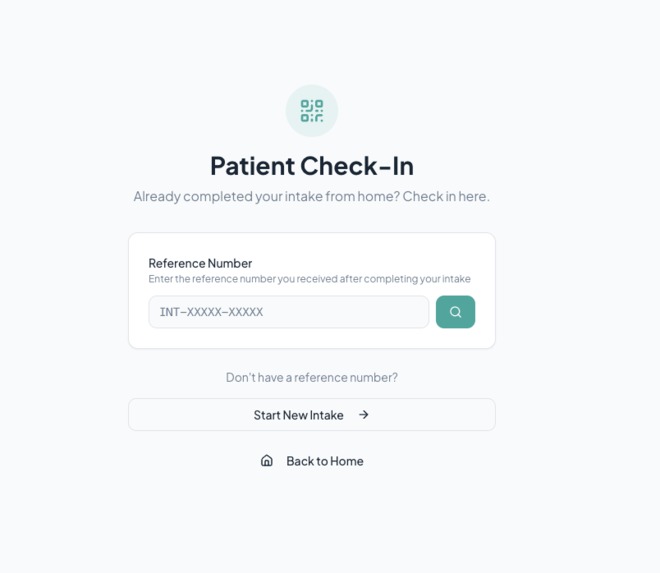
Patient Check-in (for online intake form submission) - Patient Side
-
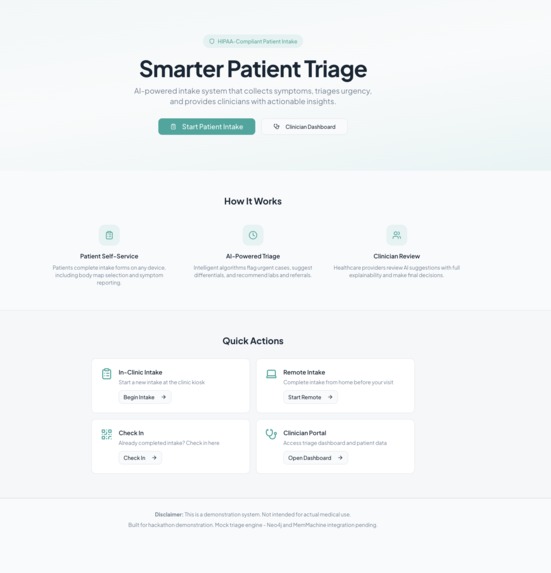
Home Page for Hackathon use (actual will use endpoints)
-
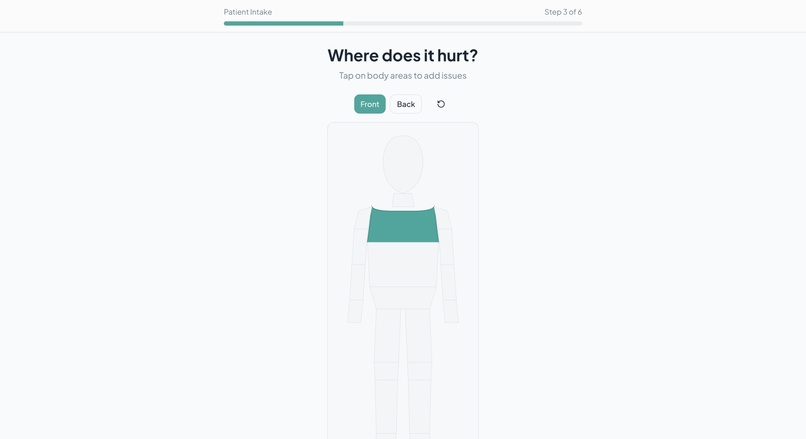
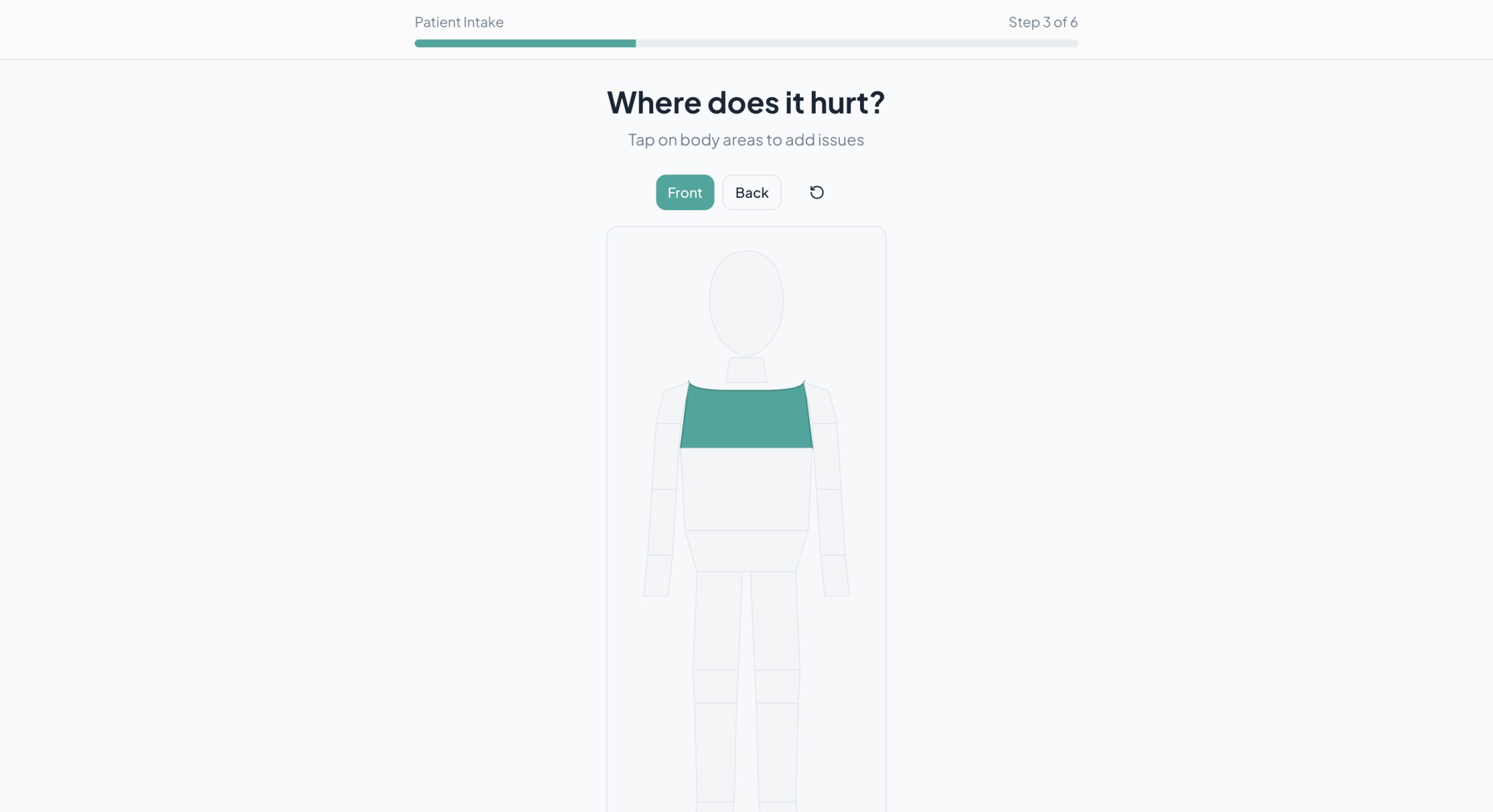
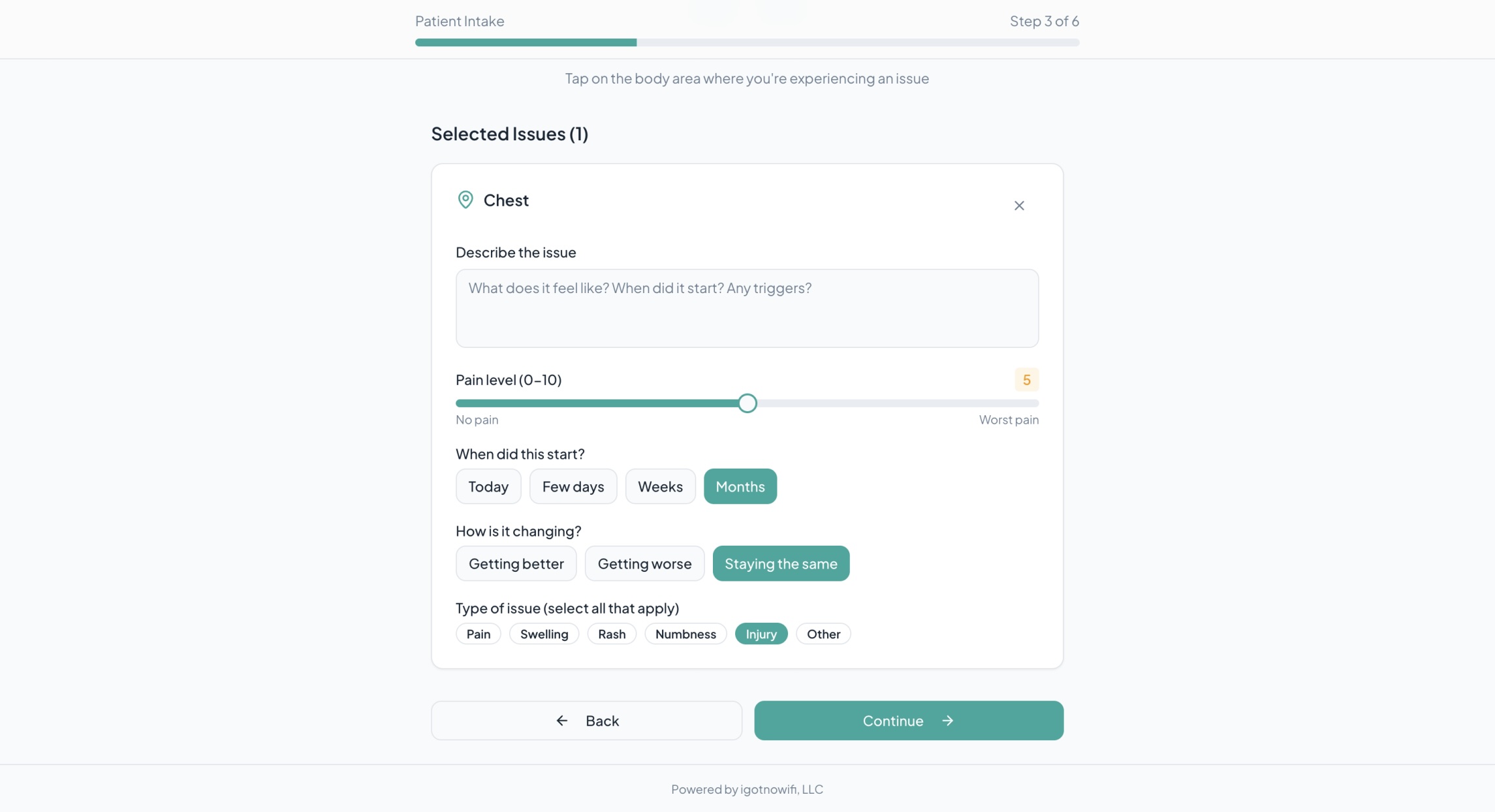
Body Map (To indicate area of concern) - Patient Side
-
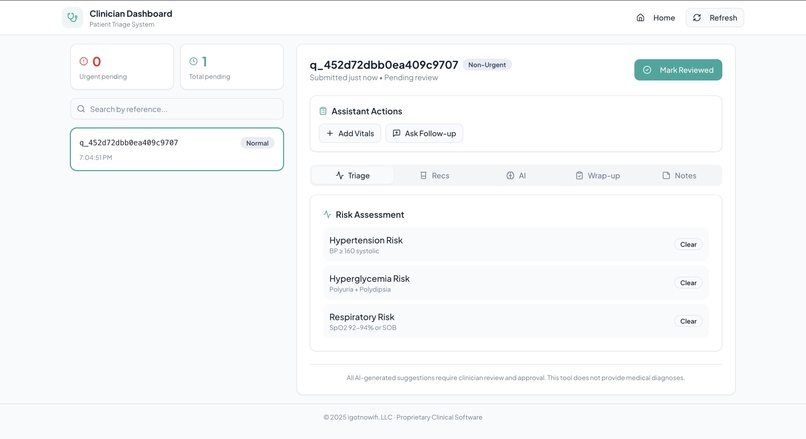
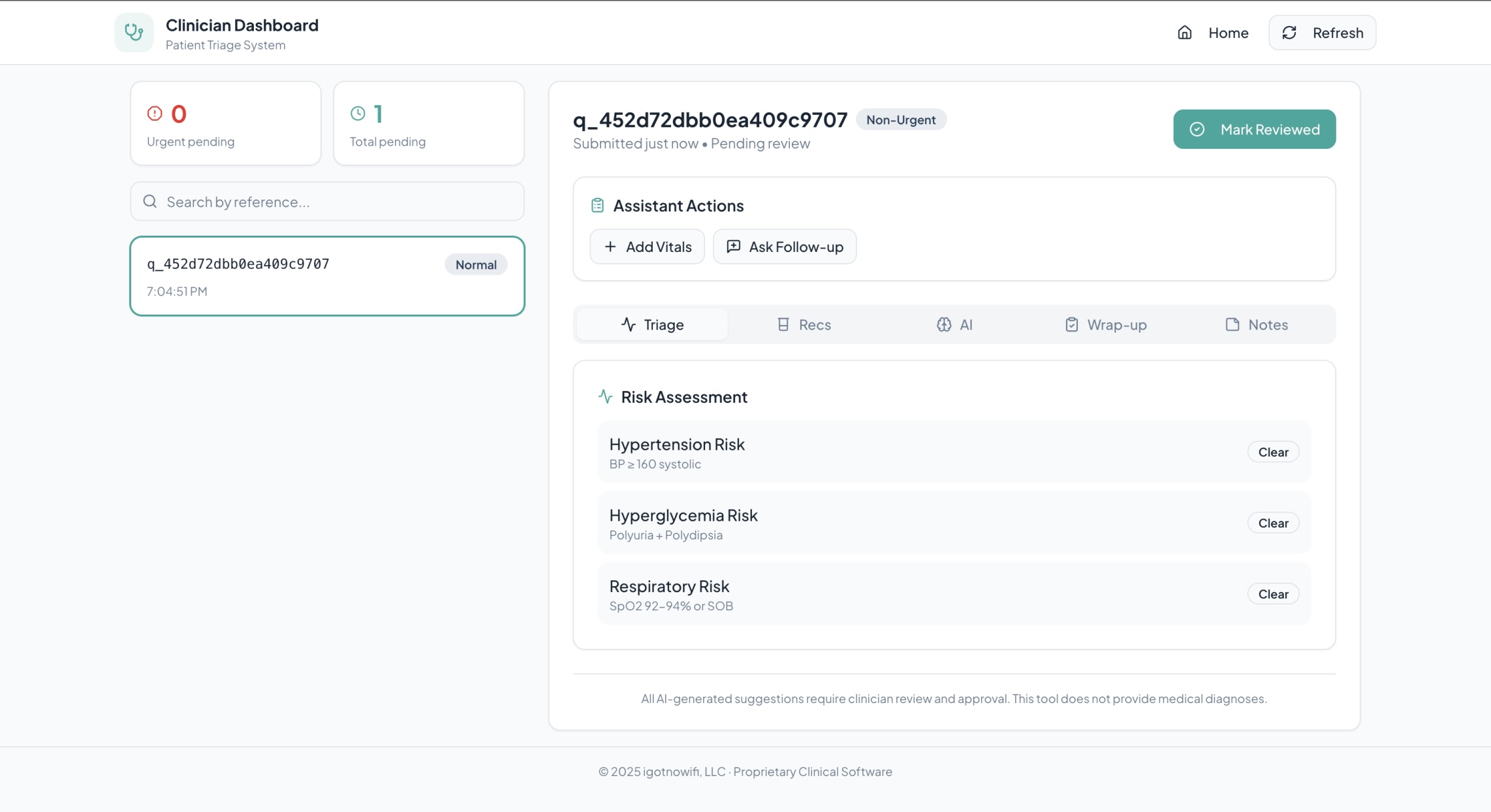
Practioner Dashboard - Clinical Staff Side
-
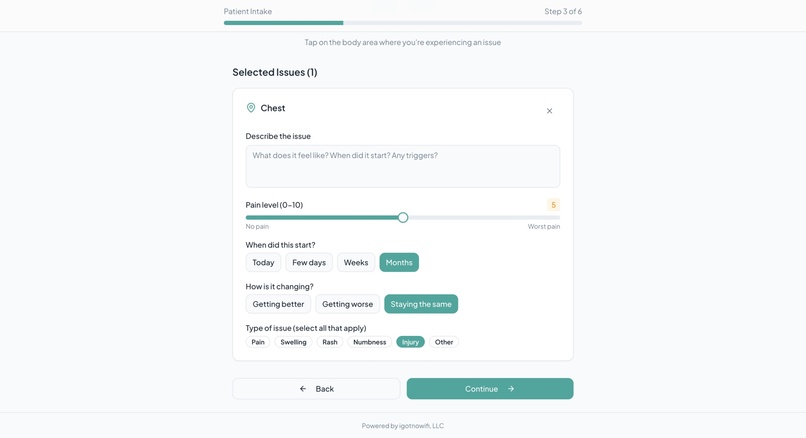
Clarification of Body Map - Patient Side
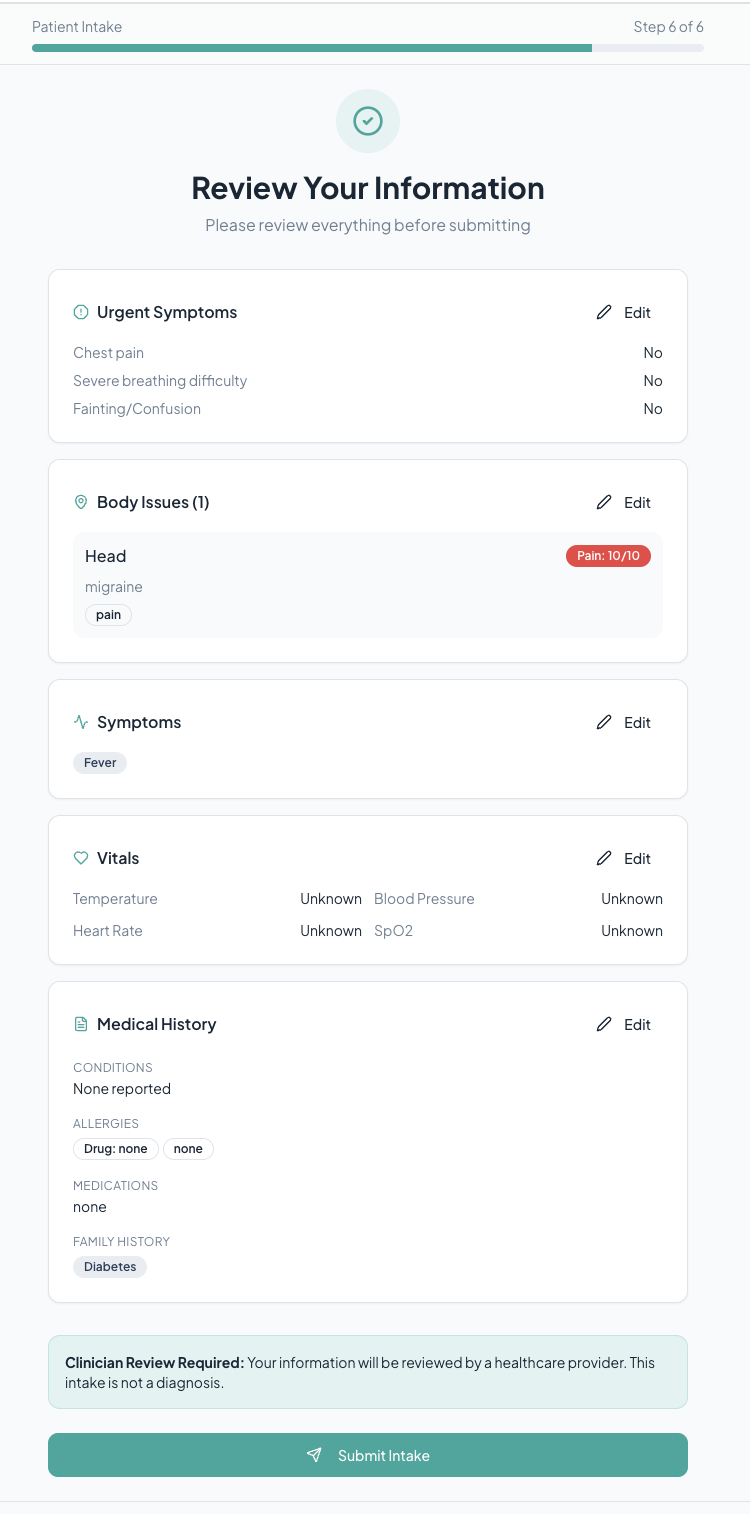
About the Project
Inspiration
We were inspired by a recurring gap in real clinical workflows: patient intake and triage systems are often fragmented, brittle, and poorly aligned with how clinicians actually work. Patients are asked to complete long, static forms, clinicians receive incomplete or poorly structured information, and critical signals like red flags or missing data are handled inconsistently or too late.
As engineers working closely with real-world systems, we wanted to design intake not as a one-off form, but as a stateful, clinician-in-the-loop process that mirrors how clinics actually operate. Our goal was to build something practical, extensible, and workflow-aware rather than a purely theoretical solution.
What We Built
We built a Clinic Intake & Triage System that supports the full pre-visit clinical workflow:
- Patient check-in with identity verification (first name, last name, date of birth)
- A dynamic intake flow with branching logic, symptom mapping, and red flag screening
- A rule-driven triage engine that computes condition probabilities and urgency
- A clinician dashboard that surfaces only patients who have properly checked in
- Clear separation between patient-facing experiences and clinician-facing tools
Each component is modular but connected, allowing the system to evolve without breaking clinical safety guarantees.
How We Built It
The system is implemented as a modern web application with a strongly typed backend and a reactive frontend:
- Frontend: React + TypeScript, with a multi-step intake flow and a dedicated check-in gate
- Backend: FastAPI with Pydantic models enforcing strict schemas and validation
- Triage Engine: A rule-based scoring system driven by structured knowledge packs (symptoms, conditions, red flags)
- Workflow State: Explicit session tokens and state transitions (
checked-in,intake-submitted,triaged) to avoid ambiguity
At the core of triage is a weighted scoring function that combines symptom overlap, patient history, issue descriptions, and red flag signals:
[ \text{score} = 2 \cdot (\text{matched symptoms}) + (\text{supporting history}) + (\text{issue matches}) + \text{red flag bonus} ]
This produces a ranked differential diagnosis with confidence labels while preserving clinician oversight.
Knowledge Graph & Memory Architecture
Neo4j for Clinical Knowledge Graph (RAG)
We use Neo4j to model a clinical knowledge graph that supports diagnosis and triage reasoning. The graph encodes structured relationships between clinical entities, including:
- Symptoms and conditions
- Conditions and red flags
- Conditions and medication classes
- Conditions and supporting history factors
- Symptoms and body regions
During triage, the system retrieves relevant subgraphs to inform scoring, ranking, and explanations. This allows the triage engine to reason over clinically meaningful relationships rather than relying on flat text or hard-coded rules. Neo4j serves as the foundation for our knowledge-graph–driven RAG architecture and is intentionally separated from transactional application state.
Memory Machine for Assistant Context & Workflow Awareness
We designed the system around a memory machine architecture to support stateful, context-aware workflows without relying on fragile client-side storage or purely stateless API calls.
In the current implementation, the backend maintains authoritative session and workflow state (such as check-in status, intake submission, triage results, and clinician edits) at the API layer, while the memory machine is used to support assistant-level memory and preferences that persist across sessions.
This includes the ability to store and recall:
- Clinician preferences and dashboard configuration
- Drafting and communication style preferences
- Reusable follow-up patterns and assistant context
- Workflow-related metadata that improves continuity across interactions
The memory machine is intentionally decoupled from patient-identifying data and raw intake responses, allowing assistant memory to evolve independently of protected clinical data. This design avoids entangling AI memory with core workflow persistence, while keeping the system flexible and future-proof.
Why This Matters
By separating clinical knowledge (Neo4j knowledge graph), authoritative workflow state (backend session management), and assistant memory (memory machine), the system remains explainable, extensible, and aligned with real clinical processes.
This layered approach allows us to safely incorporate richer decision-support models, personalization, and clinician feedback loops over time—without rewriting core infrastructure or conflating AI memory with patient records.
What We Learned
Building this system highlighted several important lessons:
- Workflow design matters more than UI polish. Features only work if they align with real clinical processes.
- State transitions must be explicit. “Submitted”, “checked in”, and “ready for clinician” are distinct states with real consequences.
- Strict validation is a feature, not a bug. Pydantic errors surfaced hidden assumptions and improved data quality.
- Frontend–backend contracts must be deterministic. Even small routing inconsistencies can cause misleading failures.
Challenges We Faced
Some of the key challenges included:
- Designing intake logic that remains robust with partial or missing data
- Aligning frontend flow with backend enforcement of check-in before clinician visibility
- Debugging intermittent issues caused by development proxy and routing mismatches
- Hardening the triage engine against incomplete or imperfect knowledge base entries
Each challenge pushed us to make the system more explicit, safer, and closer to real clinical practice.
Next Steps
We see several clear directions to evolve this project further:
Improve the RAG + Knowledge Graph with expert feedback
Incorporate clinician and domain-expert feedback to refine condition weights, symptom relationships, and scoring logic, enabling more accurate and explainable triage recommendations.Expand the intake questionnaire to mirror real clinical procedures
Add more structured and context-aware questions that reflect actual clinical workflows, improving data quality and reducing follow-up burden on clinicians.Strengthen privacy and security for HIPAA requirements
Introduce additional safeguards such as data encryption at rest and in transit, access controls, audit logging, and role-based permissions to better align with healthcare compliance standards.Run pilot programs to refine UI/UX
Partner with clinics or healthcare teams to pilot the system in real settings, gathering feedback to further improve usability, accessibility, and clinician efficiency.Add ensemble decision-tree models to augment diagnosis support
Integrate ensemble-based approaches (e.g., decision trees and tree-based ensembles) alongside the existing rule-based system to provide practitioners with complementary diagnostic signals and confidence ranges, while keeping final clinical judgment with the human clinician.
Why This Matters
By treating check-in, intake, triage, and clinician review as a single coherent system, our project demonstrates how clinical software can be safer, more transparent, and more workflow-aware.
The architecture is intentionally extensible and designed to support future enhancements such as deeper clinical decision support, longitudinal patient tracking, and automated clinician communication—while keeping humans firmly in the loop.
Built With
- docker
- fastapi-(python)
- knowledge-graph?driven
- memmachine
- memory-augmented-state-machines
- neo4j
- pydantic
- rag
- react
- rest-apis
- rule-based-triage-engine
- tailwind-css
- typescript
- vite


Log in or sign up for Devpost to join the conversation.