-
-
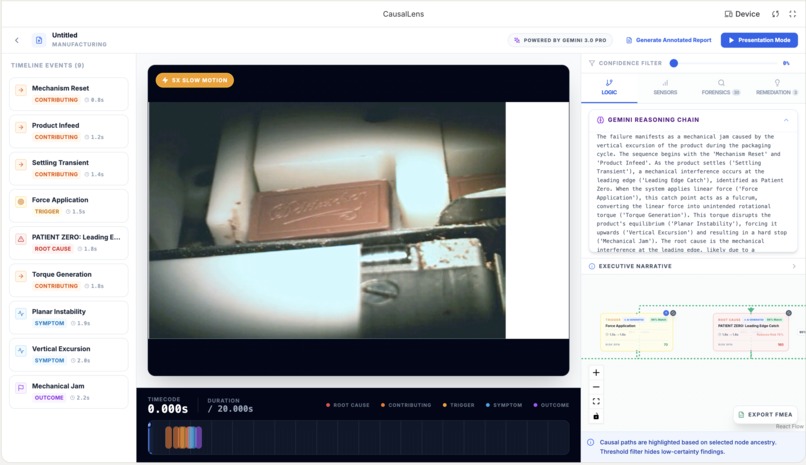
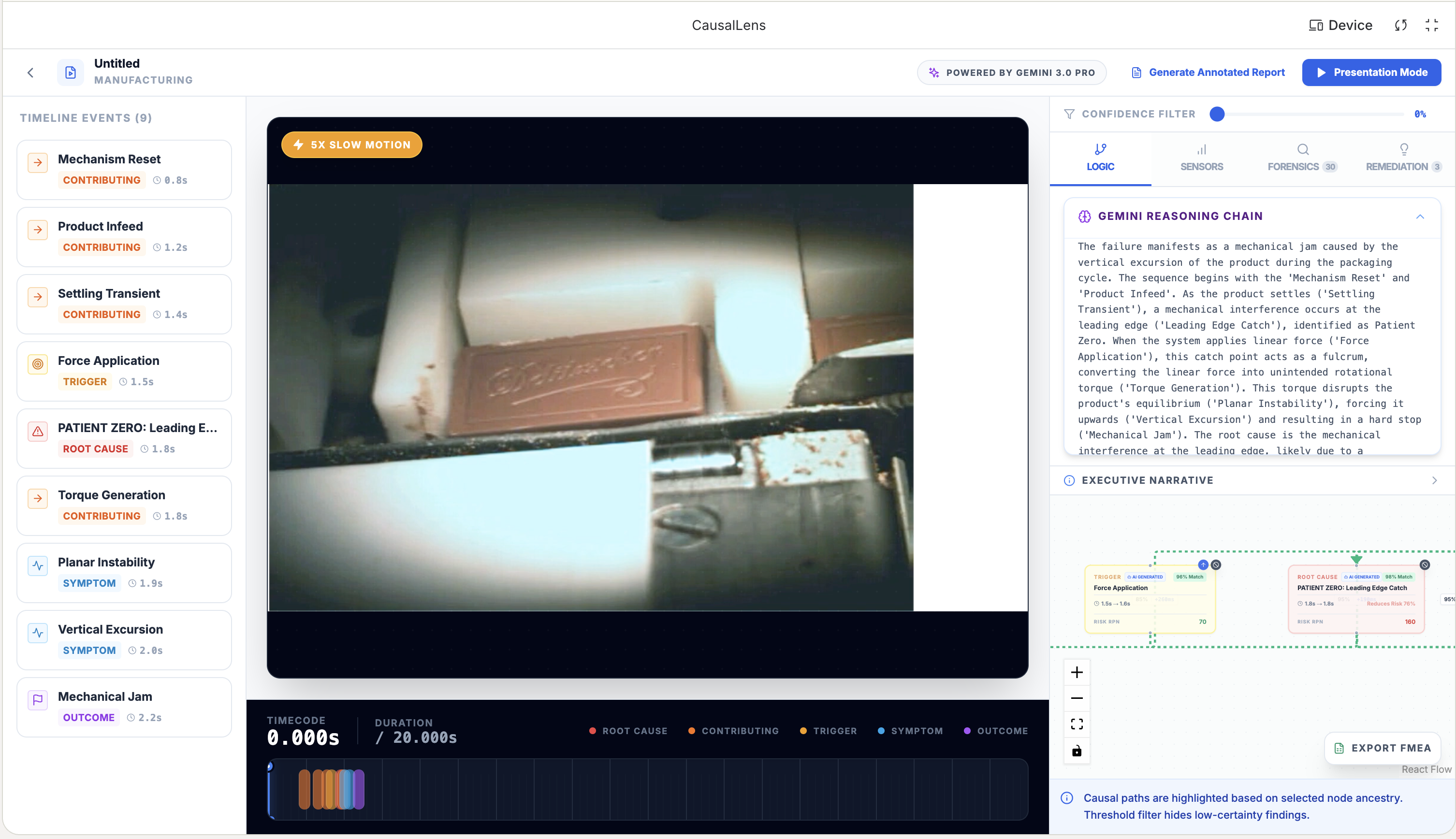
Video analysis
-

Annotated pdf export
-
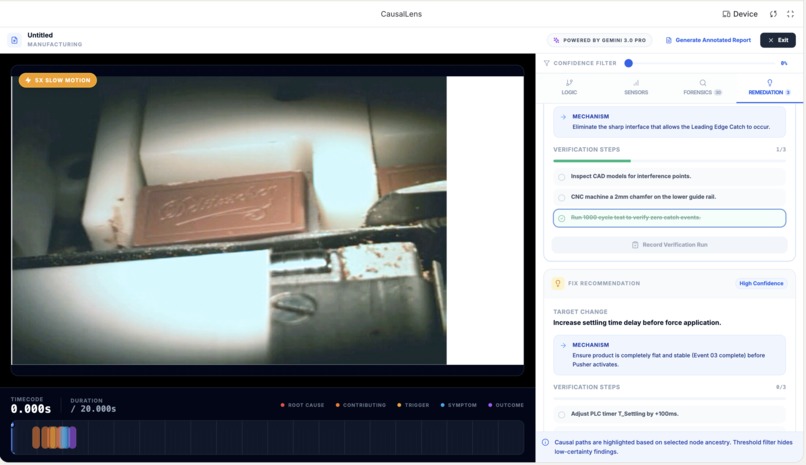
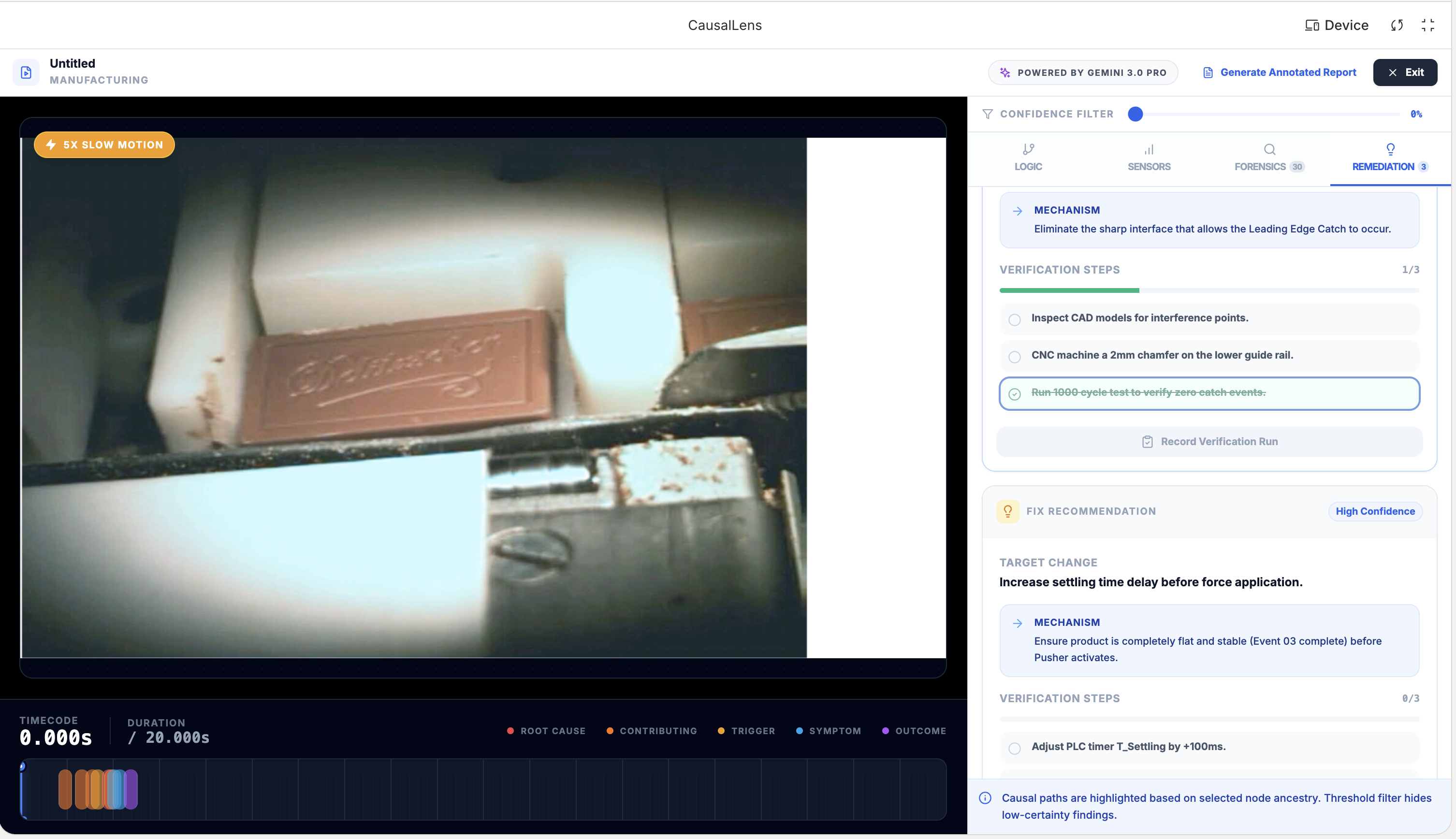
Recommended fixes

Inspiration
Root cause analysis in engineering is still largely manual. When a robot collapses on a factory floor or a packaging line jams, engineers spend days scrubbing through footage frame by frame, trying to reconstruct what happened and why. The output is usually a Word document with screenshots and best guesses.
I wanted to see if Gemini 3's extended thinking and multimodal capabilities could replace that entire workflow. Not just detect what happened, but reconstruct the full causal chain from root cause to outcome, with enough rigor to feed directly into compliance processes like FMEA and 8D reporting.
What it does
CausalLens is a forensic intelligence platform. You upload failure footage and it returns:
- Every discrete failure event with bounding boxes on the exact components involved
- Event classification as root cause, contributing factor, trigger, symptom, or outcome
- A full interactive causal graph showing how events cascade from cause to effect
- FMEA risk scores (Severity, Occurrence, Detection, RPN) per event, exportable as CSV
- Actionable remediation with specific verification steps engineers can follow
- An annotated forensic report (PDF with bounding box overlays on evidence frames, full chronology, and remediation steps)
- Counterfactual analysis: select any event and see which downstream failures would be prevented if you fixed it
- Human-in-the-loop controls: engineers can override AI classifications and mark findings as verified, creating an audit trail
It adapts to different footage types automatically. For high-speed events (impacts, ballistics, electrical arcs), the system applies dynamic slowdown from 2x up to 40x so nothing is missed.
How I built it
CausalLens runs a four-phase pipeline across three Gemini models:
Phase 0 - Temporal Screening (gemini-3-flash-preview): Three sampled frames are sent to Gemini Flash, which classifies the video's motion profile (normal vs. high-speed) and decides the optimal slowdown factor. This determines how many frames to extract and how to present them to the deeper models.
Phase 1 - Frame Extraction (browser-side): Based on the screening result, the system extracts 20 frames (standard) or 30 frames (high-speed) at 1280px resolution, each tagged with its exact timestamp for sub-100ms temporal grounding.
Phase 2 - Evidence Detection (gemini-3-pro-preview, thinkingBudget: 16,000 tokens): Gemini Pro analyzes all frames together to identify 8-15 discrete physical events. Each event gets bounding boxes (0-1000 normalized coordinates), observable descriptions, and confidence scores. The prompt enforces physics-based detection: hunt for precursor events 100-500ms before failure onset, distinguish mechanical from electrical signatures.
Phase 3 - Causal Reasoning (gemini-3-pro-preview, thinkingBudget: 32,768 tokens): A second Pro pass with maximum extended thinking reconstructs the full causal graph. It classifies each event, assigns FMEA scores, constructs directed edges with mechanism descriptions, and generates remediation recommendations with verification steps. The structured output is enforced via responseSchema with Type enums from the @google/genai SDK.
Post-processing intelligence runs on the resulting graph:
- Reverse causal edge purging: removes any edge where the effect's timestamp precedes the cause's by more than 0.2 seconds, because physics doesn't work backwards
- Orphan node auto-linking: disconnected events are linked to their nearest temporal neighbor with a 0.5 confidence "Temporal Sequence" edge, ensuring a coherent narrative
The frontend is React 19 + TypeScript + Zustand for state management, with ReactFlow for the interactive causal graph visualization. The counterfactual analysis uses BFS traversal through the causal graph to propagate the impact of preventing any single event.
A fourth model, gemini-3-pro-image-preview, handles branding (AI logo generation on the settings page).
The entire application was built in Google AI Studio using the Gemini repository template, running fully client-side with no backend server required.
Challenges I ran into
Getting structured output right. Gemini sometimes returns JSON wrapped in markdown code blocks, or partially malformed responses. I built a multi-strategy parser that tries raw JSON first, then strips markdown fences, then attempts substring extraction as a last resort. This made the pipeline robust enough for real-time use.
Temporal precision. For high-speed footage, events happen within 100ms of each other. Getting Gemini to anchor its analysis to exact frame timestamps rather than vague descriptions required careful prompt engineering: injecting "TIMECODE: X.XXs" tags alongside each frame and explicitly instructing the model to reference them.
Causal graph validation. Early versions of the pipeline sometimes produced edges that violated temporal causality (effect before cause). Rather than trying to fix this in the prompt, I added a post-processing step that programmatically purges impossible edges and auto-links orphaned nodes. This hybrid approach (LLM reasoning + algorithmic validation) proved far more reliable than prompt engineering alone.
Balancing thinking budgets. Phase 2 (evidence detection) needs enough thinking to identify subtle events but not so much that it hallucinates. Phase 3 (causal reasoning) needs deep reasoning to construct valid chains across 8-15 events. After testing, 16,000 tokens for detection and 32,768 for reasoning hit the right balance.
Accomplishments that I'm proud of
- The system genuinely works across domains. The same pipeline handles a humanoid robot collapsing on stage and a cookie packaging line jamming, adapting its analysis automatically.
- Reverse causal edge purging is a simple idea but it catches real errors that would undermine the entire analysis.
- The counterfactual "what-if" analysis is something engineers actually want. Being able to click a root cause and see every downstream event that would be prevented is immediately useful for prioritizing fixes.
- FMEA export generates industry-standard compliance spreadsheets directly from AI analysis, bridging the gap between AI insight and engineering workflow.
What I learned
- Extended thinking in Gemini 3 Pro is genuinely transformative for complex reasoning tasks. The difference between 4,000 and 32,768 token thinking budgets is not incremental; it's the difference between surface-level pattern matching and real causal inference.
- Structured output via
responseSchemawithTypeenums eliminates an entire class of parsing bugs. Worth the upfront schema design effort every time. - Hybrid architectures (LLM + algorithmic post-processing) are more robust than pure LLM approaches for tasks with hard physical constraints like temporal causality.
What's next for CausalLens
- Continuous monitoring: process live camera feeds instead of uploaded clips, flagging anomalies in real-time
- Multi-camera synthesis: fuse evidence from multiple angles into a single unified causal graph
- Industry-specific prompt libraries: pre-tuned analysis templates for automotive, aerospace, semiconductor, and pharmaceutical manufacturing
Built With
- gemini-3-flash-preview
- gemini-3-pro-image-preview
- gemini-3-pro-preview
- google-ai-studio
- google-genai
- lucide-react
- react
- reactflow
- tailwindcss
- vite
- ypescript
- zustand


Log in or sign up for Devpost to join the conversation.