-
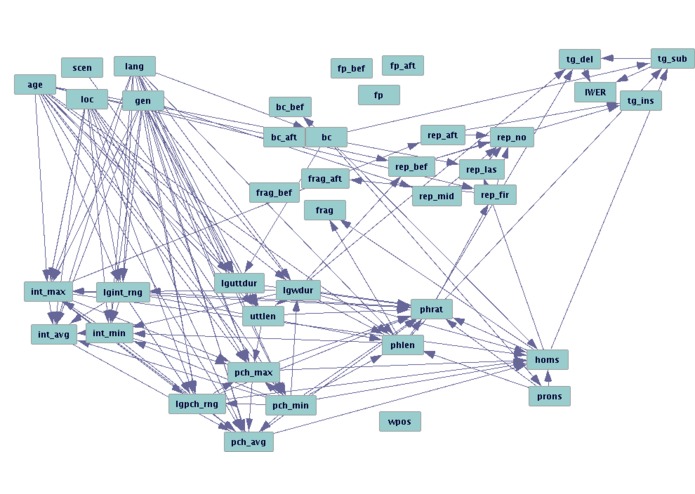
Causal model of recognition errors.

Motivation
Automatic Speech Recognition (ASR) of meetings is an important task for analysis and summarization of spoken content involving multiple individuals. It remains, however, a challenging task due to the nature of conversational speech and dialog between parties. Our goal is to understand the source of ASR errors when decoding meeting based speech and ultimately improve ASR transcription of meetings. We perform an error analysis on an ASR transcription of the AMI Meeting Corpus through a causal discovery of the effects of word based features on ASR transcription.
Methods
Conversational speech in groups tends to have variability due to a number of factors: high level of disfluency, non-canonical pronunciation, acoustic and prosodic variability, and speech dynamics of group dialog. Any one or more of these factors may trip up a typical ASR. For this project, our goal was to identify word-level features most likely to results in error.
We used a state-of-the-art time-delay neural network based speech recognizer in the Kaldi toolkit which achieved a Word Error Rate (WER) of 24.2%. This performance is comparable with reported performance in the research literature. Based on the decoded transcripts, we extracted a number of features falling in the a few groups:
Disfluency features.
- Filled pauses: words, such as "uh" and "um", which tend to have no meaning but have specific phonetic forms usually employed to delay speech. We extracted Boolean features which indicated whether a word was a filled pause, or whether it preceded or followed a filled pause.
- Fragments: partially spoken words, such as "wh-". We extracted Boolean features for the word and the preceding/following word (as above).
- Repetitions: multiple utterances of the same word, We extracted Boolean features as above. In addition, we extracted Boolean features indicating whether a word was first, last, or in the middle of, a repeated sequence,
Pronunciation features.
- Word length: the length of a word in phones.
- Number of pronunciations: the number of different pronunciations of a word in a phonetic dictionary (we used the CMU dictionary).
- Number of homophones: the number of words in a phonetic dictionary with the same pronunciation.
Prosodic features.
- Speech rate: the rate of phones uttered for the given word.
- Pitch: the pitch (fundamental frequency) of the utterance which was estimated using OpenSMILE. We used summary statistics of the estimated pitch: maximum, minimum, mean, logarithm of range, and standard deviation.
- Intensity: the intensity of the word utterance, also estimated using OpenSMILE and using summary statistics as above.
- Duration: the logarithm of word duration in seconds, as well as logarithm of duration of the utterance containing the word.
Metadata features.
This included speaker characteristics including identity, gender, age, and native language. In addition, we used the location of the conversation and meeting scenario, which were available from the AMI corpus metadata.
Target features.
Although our target feature is a Boolean presence or lack of an error relative to the reference transcription, we also included the types of error (insertion, substitution or deletion error) for a given word, in case this was useful for further analysis.
Causal Model
We used TETRAD to search for a causal model explaining which features caused errors to occur. Our data was missing metadata for a number of features and we chose to ignore such data instances. We also balanced the data based with respect to presence of error. This provides us with 35,000 instances and 40 features.
We used TETRAD's knowledge box to impose constraints on our model by creating three tiers. The first tier contained metadata features. These features were largely speaker or demographic characteristics and, while they may explain errors, they are usually mediated through linguistic or acoustic characteristics which we wish to identify. Thus, the second tier contained all linguistic or acoustic features above, while the third tier contained the target features. We employed the FGES algorithm in TETRAD with a penalty discount of 2 to discover a causal model.
Results
The image (attached to this submission) shows the causal graph discovered by TETRAD. We adjusted the layout of the graph to group nodes in clusters based on feature types mentioned above. There are a number of items worth noting.
As we expected, a large number of effects due to speaker characteristics (top left) are mediated by word level features, especially prosodic features (bottom center and left). However, as pointed out by the Joe Ramsey during the presentation, the relative density of the edges may indicate the presence of confounding variables which have not been identified. The GFCI algorithm may be used to identify likelihood of latent and confounding variables.
There are only six variables which have a direct effect on the errors: word is backchannel, log word duration, number of homophones, speech rate in phones, word length in phones, word follows repetition, word precedes repetition. These have likely explanations, for example a word following a repetition will tend to be enunciated more clearly, while a word preceding a repetition is likely to have been mispronounced or not clearly uttered. However, it is still interesting how few of the examined variables have direct effects on error and. Coupled with observation of confounding latent variables, we suspect that this model is incomplete with respect to variables. There are also some variables which may have little to no effect on error, such as filled pauses. This was surprising, and we plan to examine the literature as well as more data to confirm whether this holds generally.
Using the six variables above, and their associated 8 variables (e.g. all backchannel related variables), for a total of 14 variables, yields a logistic regression model which is on par with performance from a L1-regularized logistic regression model using all variables. We found that duration and repetition increased the likelihood of error by 7% and 9%, respectively, while backchannel and number of pronunciations decreased the likelihood of error by 25% and 26%, respectively.
Future Directions
Although this was a first attempt at a causal analysis, it is exciting to to see the relative strengths of hypotheses concerning word-level features of speech and their effect on recognition error. There are several avenues to pursue as we continue our investigation. We plan to use a different search algorithm determine the possibility of confounding and latent variables. We would also like to follow up with using more features motivated by linguistic and acoustic accounts of speech. Finally, we would like to examine possibilities related to group level interactions which manifest in speech which may account for recognition errors. Our ultimate goal is improve speech recognition for meetings and this has been an fruitful first step in that direction. We are grateful to the Center for Causal Discovery for the short course on causal discovery and hosting the datathon which helped make this possible.
Built With
- kaldi
- python
- tetrad
Log in or sign up for Devpost to join the conversation.