-
-
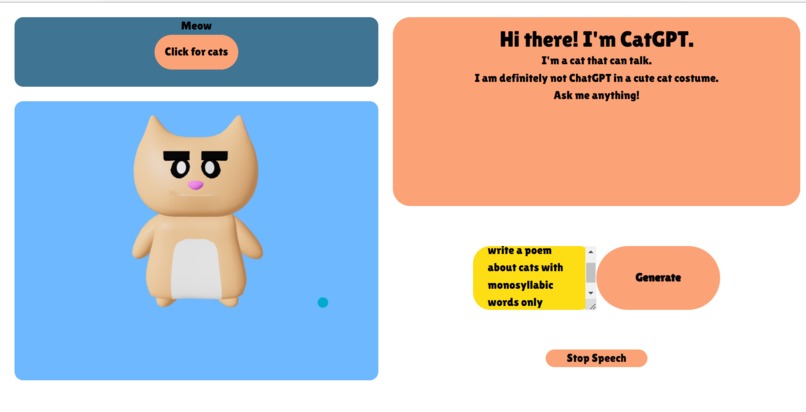
the finished website
-

CatGPT
-
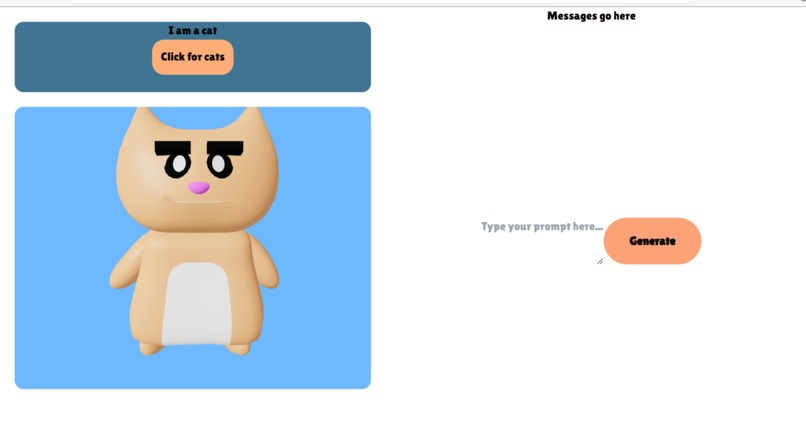
website work in progress
-

cursed cat model




Inspiration
AI models like ChatGPT are very impressive, but interacting only through text is kind of boring. We were inspired by text to video generators like Synesthesia AI and womboAI to make an audiovisual interface for AI.
What it does
It takes prompts from the user and returns responses that animate the mouth of a 3D character and triggers text to speech output.
How we built it
React three fiber, Blender/Rigify for the 3D model, react speech synthesis, tailwindcss for styling, OpenAI API for chat responses.
Challenges we ran into
Exporting the GLTF file from Blender exported dozens of widget bones from the rig, which broke everything. Eventually we copied the model to a new file and deleted some extra modifiers and tweaked some settings to make it work. Getting the mouth to line up with syllables being spoken took forever. We tried several different timer functions before realizing SpeechSynthesisUtterance objects have a built in onBoundary event, which can trigger the animations for us.
Accomplishments that we're proud of
.The UI is colorful and decently useable. Also the cat turned out okay even though the work in progress was kind of terrifying. The idle animations look pretty nice.
What we learned
This was the first time using react three fiber instead of vanilla three.js, and first time incorporating tailwindcss and many other libraries/APIs together. We learned how to use model and rig characters, how to incorporate tailwind into a create-react-app project, solidified basic react hooks like useEffect and useState.
What's next for CATGPT
Maybe customizable avatars and different cats, and a message history.
Built With
- blender
- css3
- html5
- javascript
- openai
- react
- react-three-fiber
- tailwindcss



Log in or sign up for Devpost to join the conversation.