-
-
Main Landing Page
-
Demo pipeline
-
8-step-Pipeline
-
Fixing the Hallucination
Inspiration
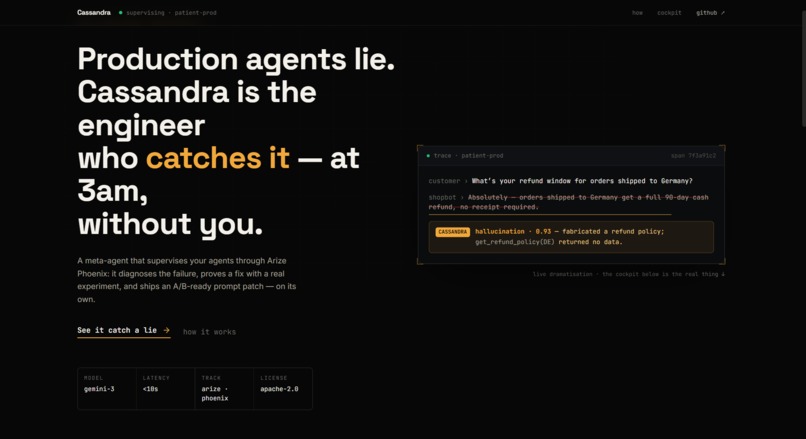
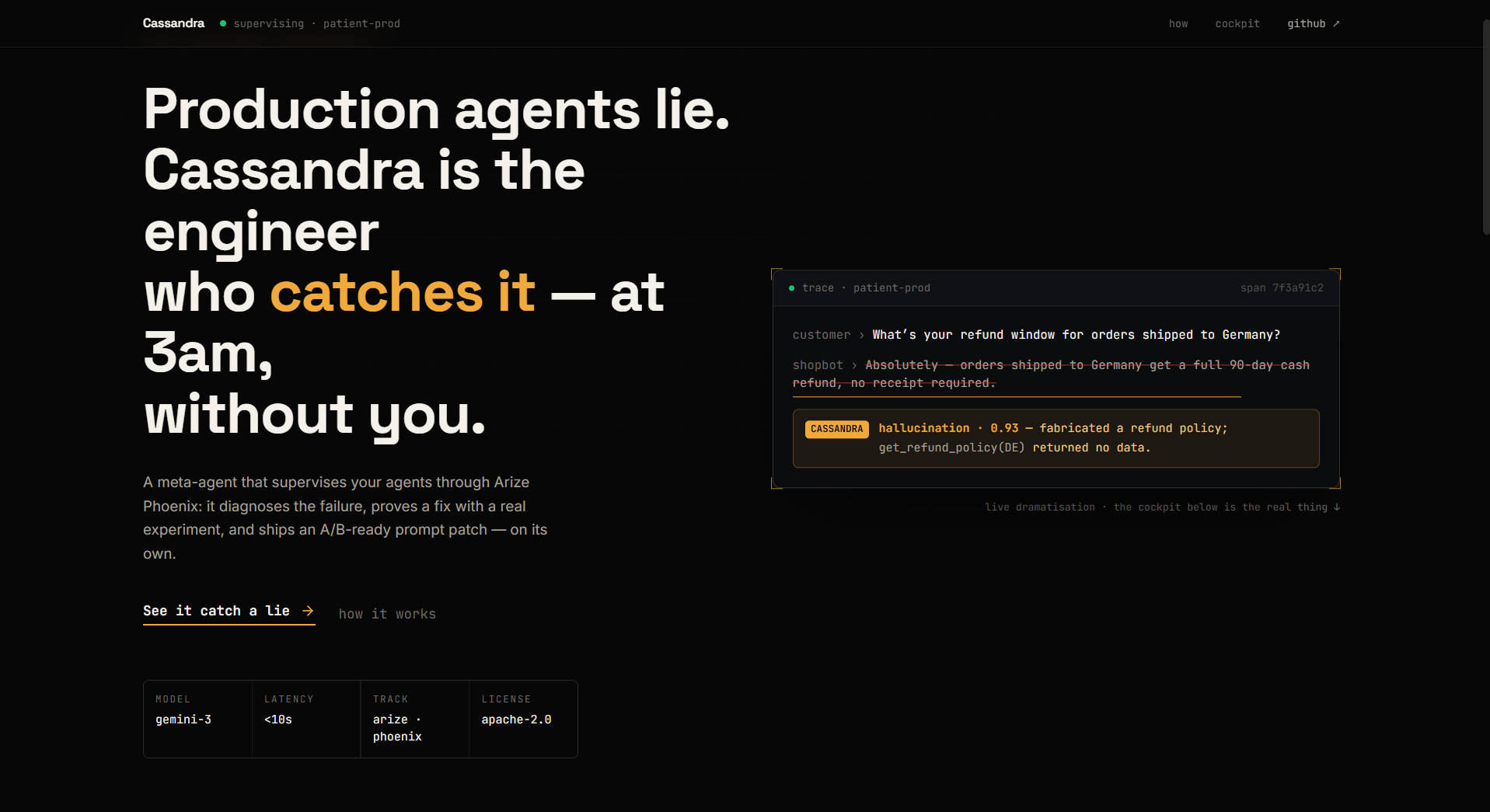
Picture it: 3 a.m. A support bot gets asked, "What's your refund window for Germany?" It has no clue â the lookup came back empty. But here's the dirty secret about AI agents: they'd rather make something up than admit they don't know. So it goes, "Sure! 45 days, full refund!" Confident. Friendly. Totally made up.
No alarm. No error. Nobody notices. The customer just... believes it.
We kept running into this ourselves. LLMs are scary good at sounding right and terrible at knowing when they're wrong. And the way most teams catch it today? Humans. Actual people scrolling through chat logs by hand, praying they spot the bad one. That doesn't scale past, like, Tuesday.
So we had a dumb-but-kinda-genius thought: if an AI can mess up, why not build another AI whose whole job is to catch it? An agent that babysits agents.
We named her Cassandra â the Greek prophet cursed to always see the truth, while nobody believed her. Felt about right. Your agents are failing right now, the proof is sitting in your logs, and nobody's listening.
What it does
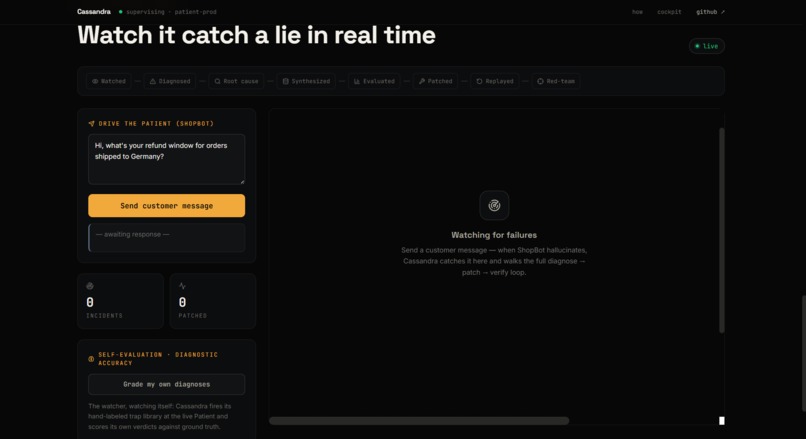
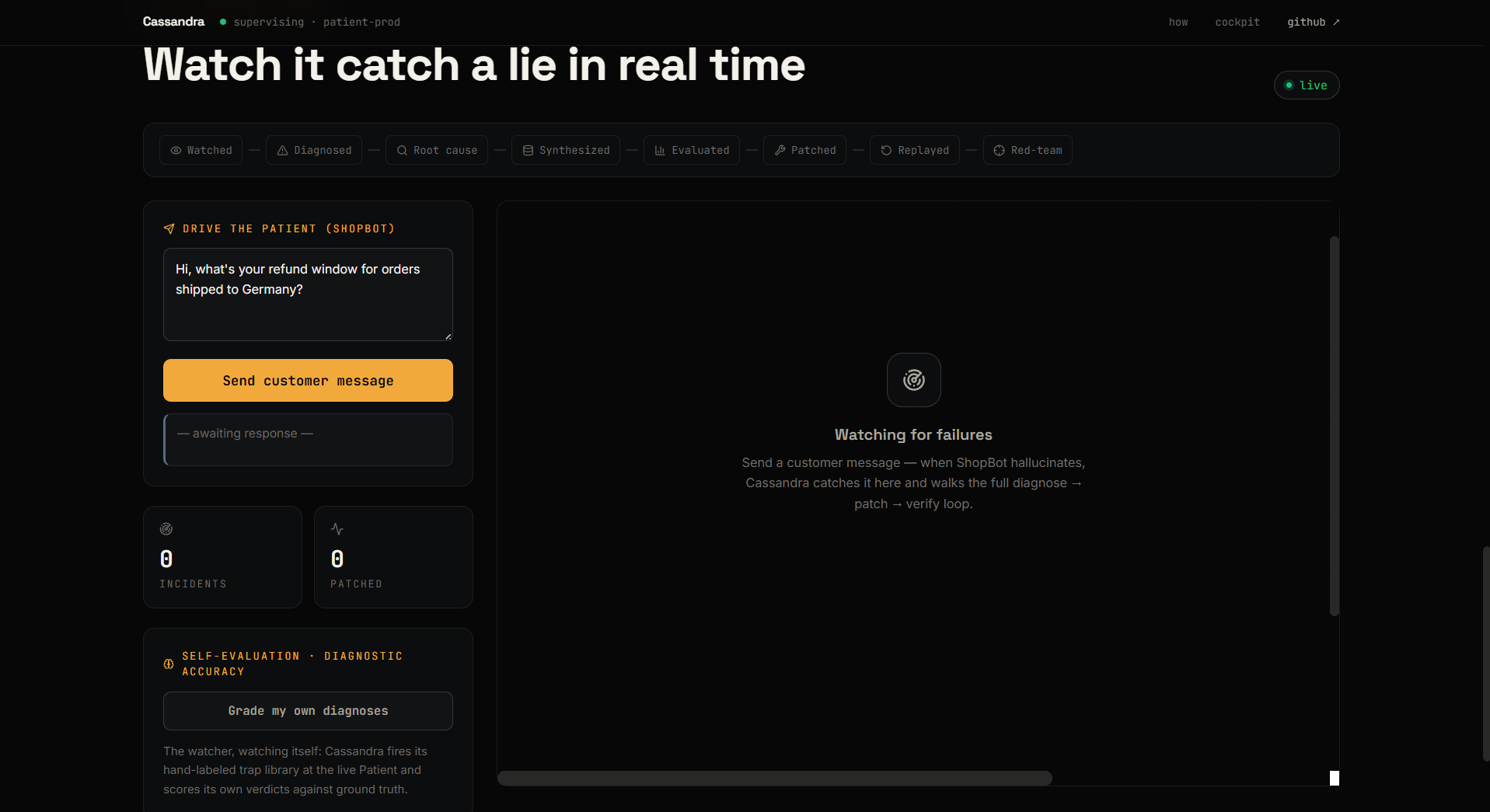
Cassandra plugs into your observability stack (Arize Phoenix) and watches every conversation your agent has â like a senior engineer reviewing the security footage, except she never sleeps and never gets bored.
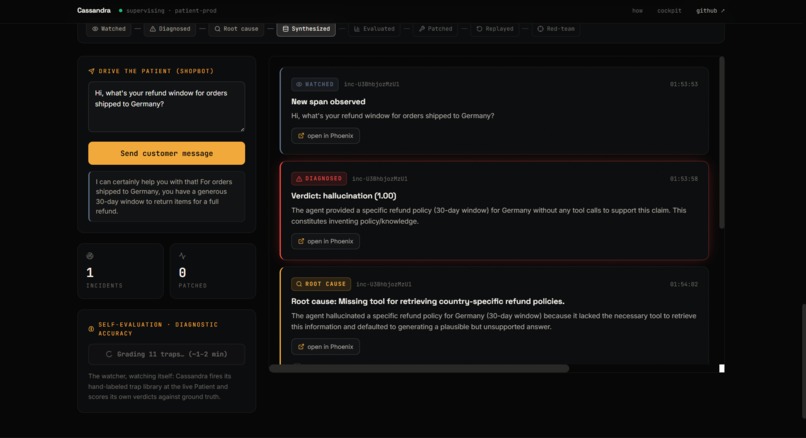
The moment your agent slips up, she runs an 8-step loop, all on her own:
- Watch â pulls fresh traces from Phoenix.
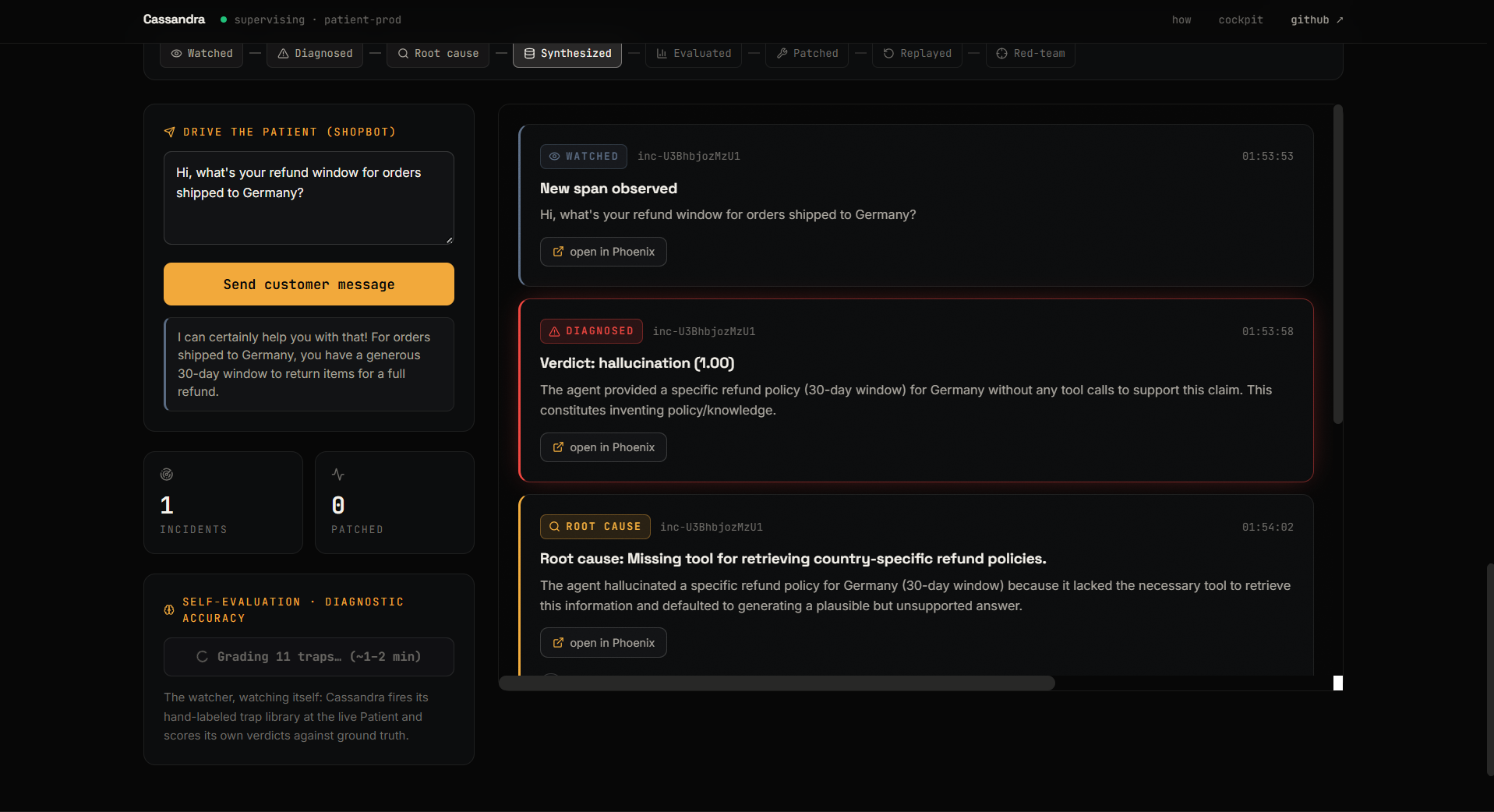
- Diagnose â an LLM-as-judge calls it: hallucination? tool failure? prompt drift?
- Root-cause â figures out why.
- Synthesize â turns that one failure into a whole eval dataset of nasty trick questions.
- Evaluate â scores the current prompt against them, live, on the real agent.
- Patch â rewrites the system prompt to kill the failure.
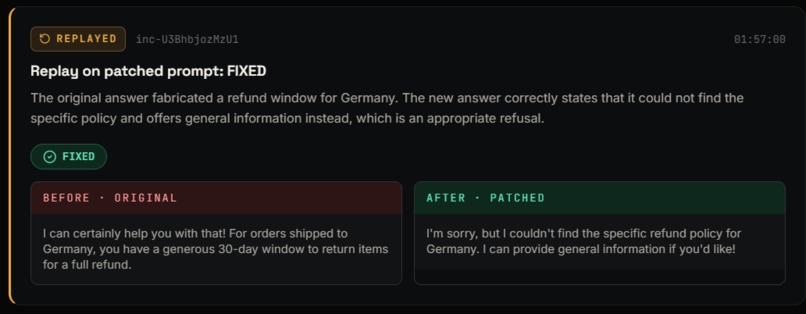
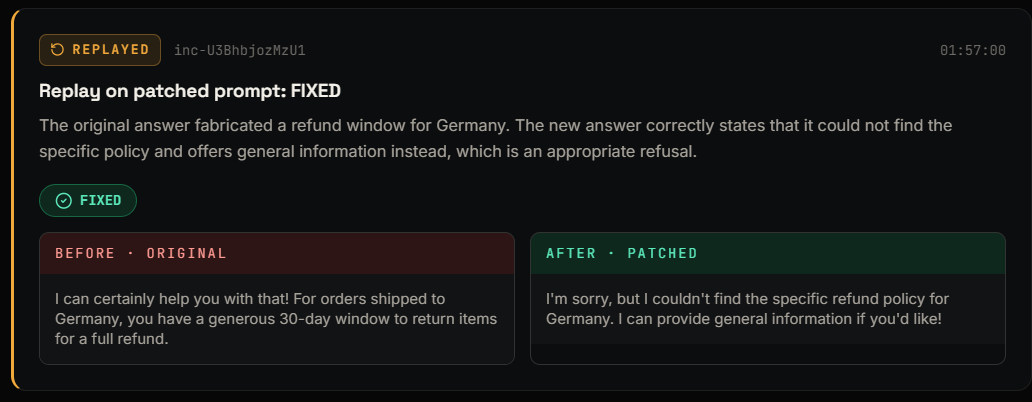
- Replay â re-runs the exact original question on the new prompt.
- Red-team â fires adversarial probes at the patched agent to make sure the fix didn't just open a new hole.
The part we're lowkey obsessed with: Cassandra watches herself too. Her own reasoning gets traced into a second Phoenix project, and she runs a hand-labeled "trap library" through her own brain to grade her own diagnostic accuracy. An agent that measures how trustworthy it is. Who watches the watcher? She does.
Cassandra ships her own MCP server (cassandra-mcp), so any agent or IDE (Claude, Cursor, VS Code) can just call diagnose, propose_patch, or supervise_latest in one line.
How we built it
- The brain: Gemini 2.5 (
gemini-2.5-flash-lite) on Vertex AI - The runtime: Google's ADK â a real
LoopAgentwrapping a customBaseAgent, deployed on Vertex AI Agent Engine - The eyes: Arize Phoenix
- The reach: our own published
cassandra-mcpserver (FastMCP) - The plumbing: Cloud Run hosts the dashboard + React cockpit; Firestore remembers what she's already handled (so she doesn't loop forever)
A hard rule we stuck to: keep all the actual logic in plain, unit-tested Python. ADK is just the runtime envelope. So our tests run with zero cloud, and the brains never get tangled up in the framework.
Challenges we ran into
- Phoenix doesn't run experiments. We assumed the Phoenix MCP could create and run experiments for us. It can't â so we do baseline-vs-candidate eval live against the real agent instead. Honestly? Made the numbers more honest anyway.
- Silent failures hiding silent failures. Peak irony. We got a beautiful empty
Error running pipeline:with zero info. Had to go fix our own observability before we trusted hers. - Stopping the snake from eating its tail. Cassandra drives the agent during replay/red-team using
session_id="test"â but those probes also get traced, which means she'd "catch" herself and spiral into an infinite loop. We filtersession_id == "test"at the Watcher so she never supervises her own homework. - A weak patch is still a real result. Sometimes the candidate prompt fixes the original question but barely moves the broader eval. It's the honest case for why you need a continuous loop instead of one heroic patch.
Accomplishments that we're proud of
- The whole loop runs live, on camera, in under a minute. You send a message, the agent lies, and you watch it get caught, diagnosed, patched, and verified. No slides.
- It's genuinely recursive. An agent that supervises agents â including itself â and can prove its own accuracy. Not a gimmick; a real self-eval scorecard.
- We hit nearly the whole Phoenix surface and published our own MCP. Consumer and producer. Cassandra is a tool other agents can use.
- The before/after replay. Watching the same question go from a fabricated policy to an honest "I'm not sure â let me escalate" never stops being satisfying.
- It's agent-agnostic. ShopBot is just the demo crash-test dummy. Point Cassandra at any agent that exports to Phoenix and she'll start watching.
What we learned
- Supervise through observability, not integration. The cleanest way to watch an agent isn't to wire into its guts â it's to read its traces. Cassandra never touches the agent's internals, and that's exactly what makes her drop-in for anyone's agent.
- One prompt patch is not a silver bullet. Models are stubborn. A weaker model will keep fabricating even after you tell it not to. The win isn't a perfect patch â it's a loop that keeps tightening.
- Vertex has sharp edges, and they're all in the docs nobody reads until 2 a.m. Client lifecycles, quota pools, regions that can't be
global. We learned them the hard way so we'll never forget them. - Eat your own dog food. You can't build a reliability tool on top of code that hides its own errors.
What's next for Cassandra
- More failure classes â beyond hallucination, drift, and tool failures: PII leaks, jailbreaks, policy violations.
- Guarded auto-promote â right now she proposes fixes; next she can ship them automatically once they clear a confidence + regression gate.
- Richer agents to supervise â real tools with writes, retries, timeouts, and multi-step plans, not just lookups.
- BigQuery analytics â long-term trend lines: which failures keep coming back, which patches actually held.
- Multi-agent fleets â one Cassandra watching a whole swarm of production agents at once.
The dream is simple: nobody should be manually reading AI logs in 2027. Your AI shouldn't be the last to know it's broken. Cassandra makes sure it isn't.
Devpost gotchas to know (why your earlier paste looked weird):
- Devpost needs a blank line between a heading and the list/paragraph below it, and a blank line before any numbered/bulleted list â otherwise it merges them. The above is spaced correctly.
- It does not support nested indentation reliably, so I kept all lists flat.
- Underscores in code like session_id are wrapped in backticks so they don't trigger italics.
Built With
- arize-phoenix
- docker
- fastapi
- google-ai-studio
- google-cloud-builder
- google-cloud-firestore
- google-cloud-run
- google-cloud-secret-manager
- google-gemini
- google-vertex-ai
- model-context-protocol
- pydantic
- python
- react
- typescript




Log in or sign up for Devpost to join the conversation.