-
-
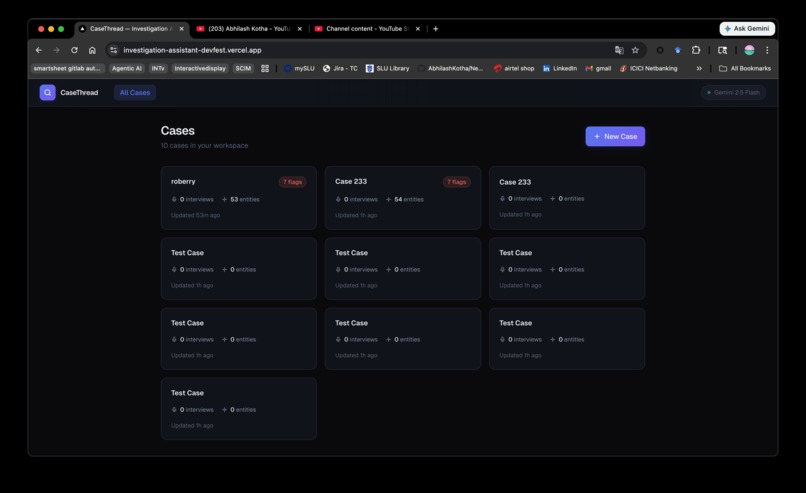
Home Page
-
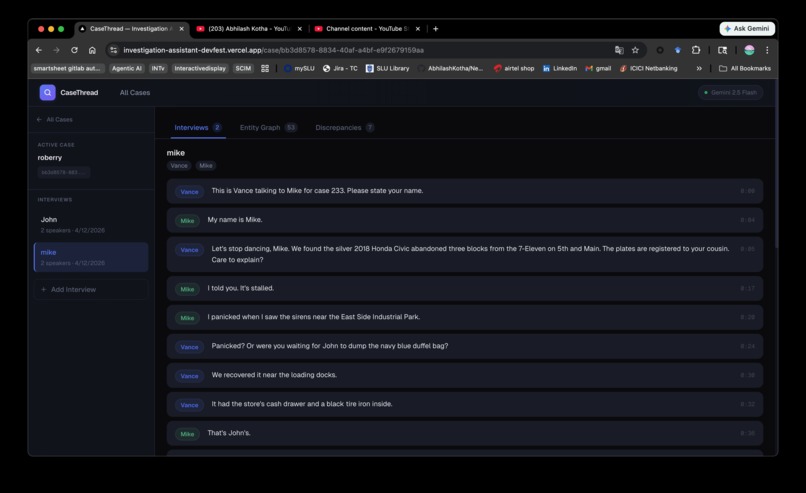
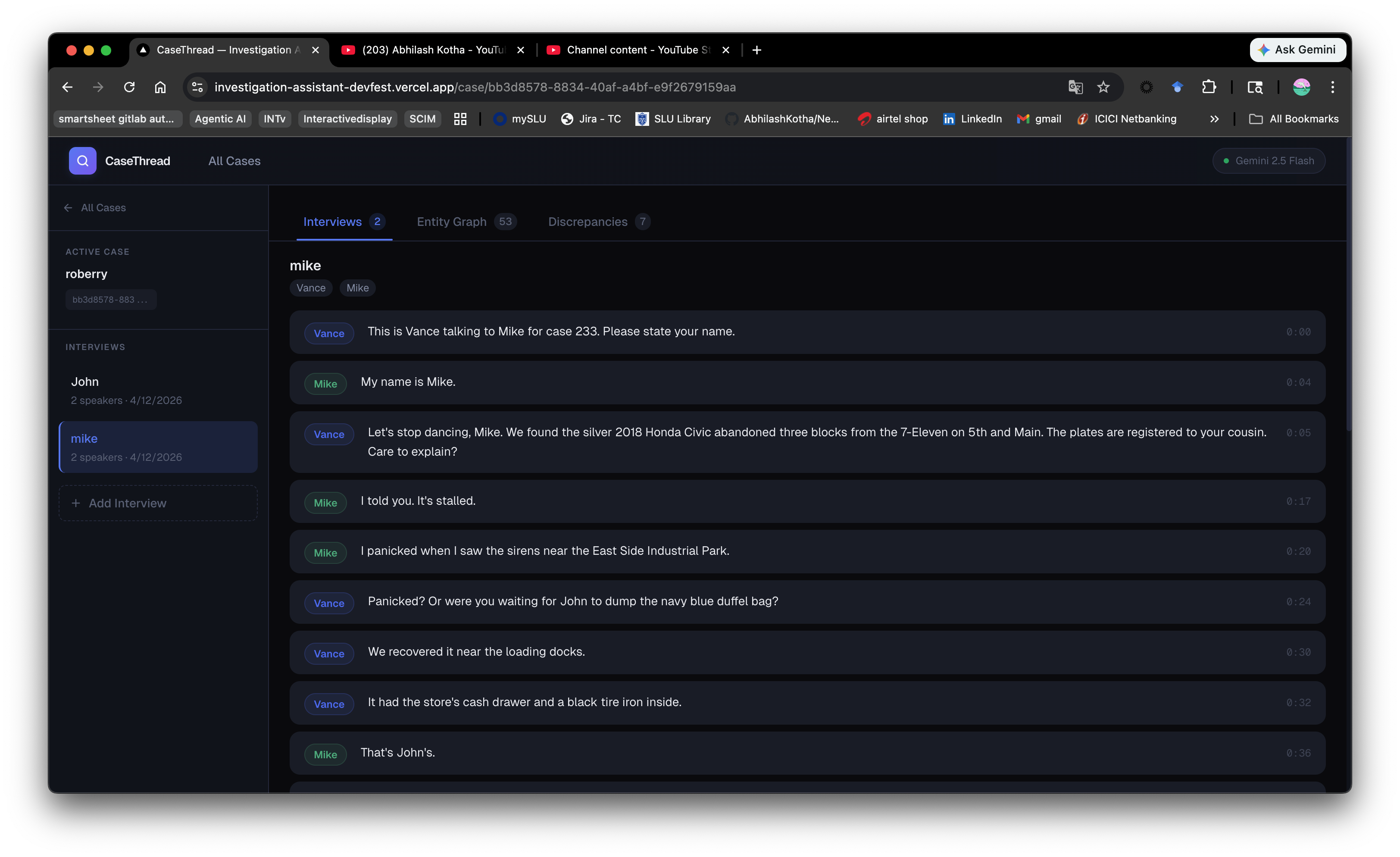
Transcriptions
-
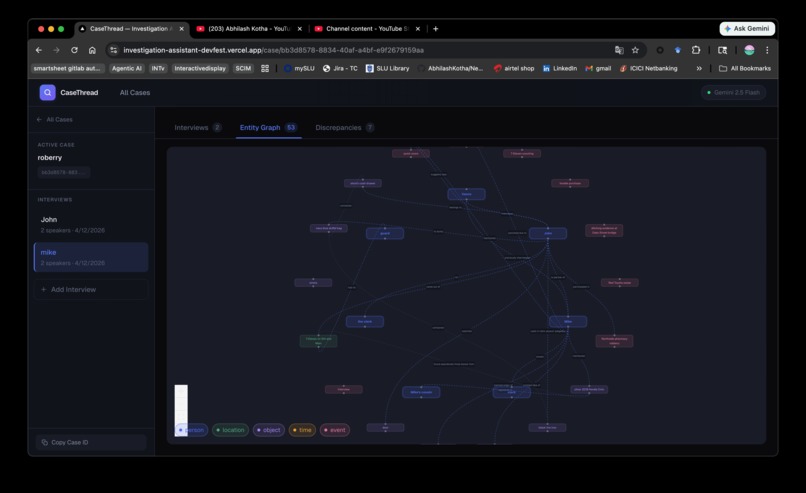
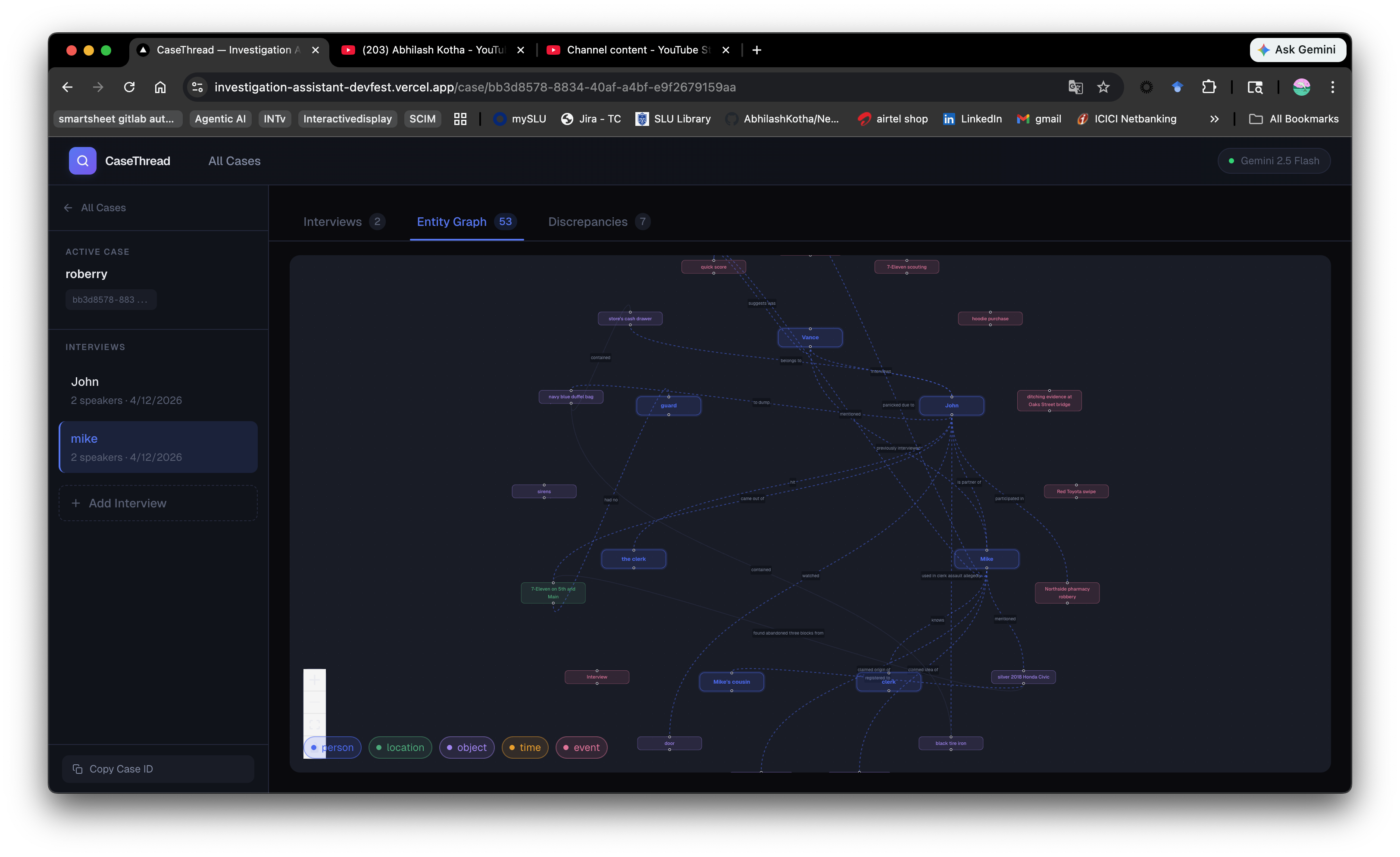
Entity graph
-
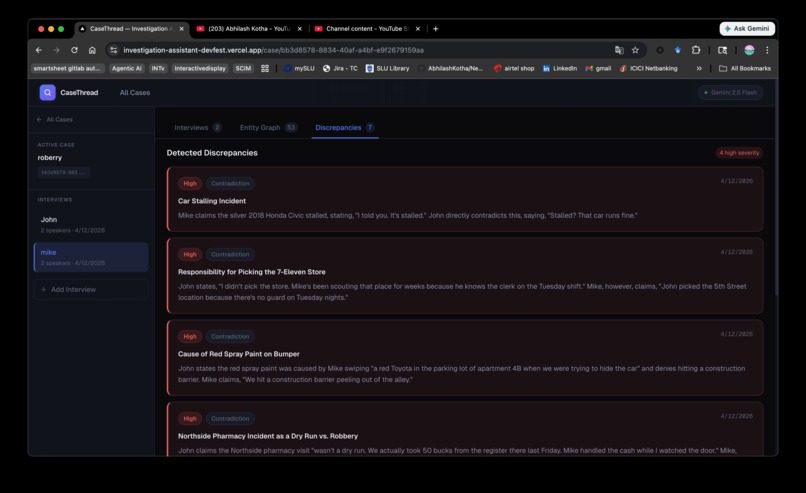
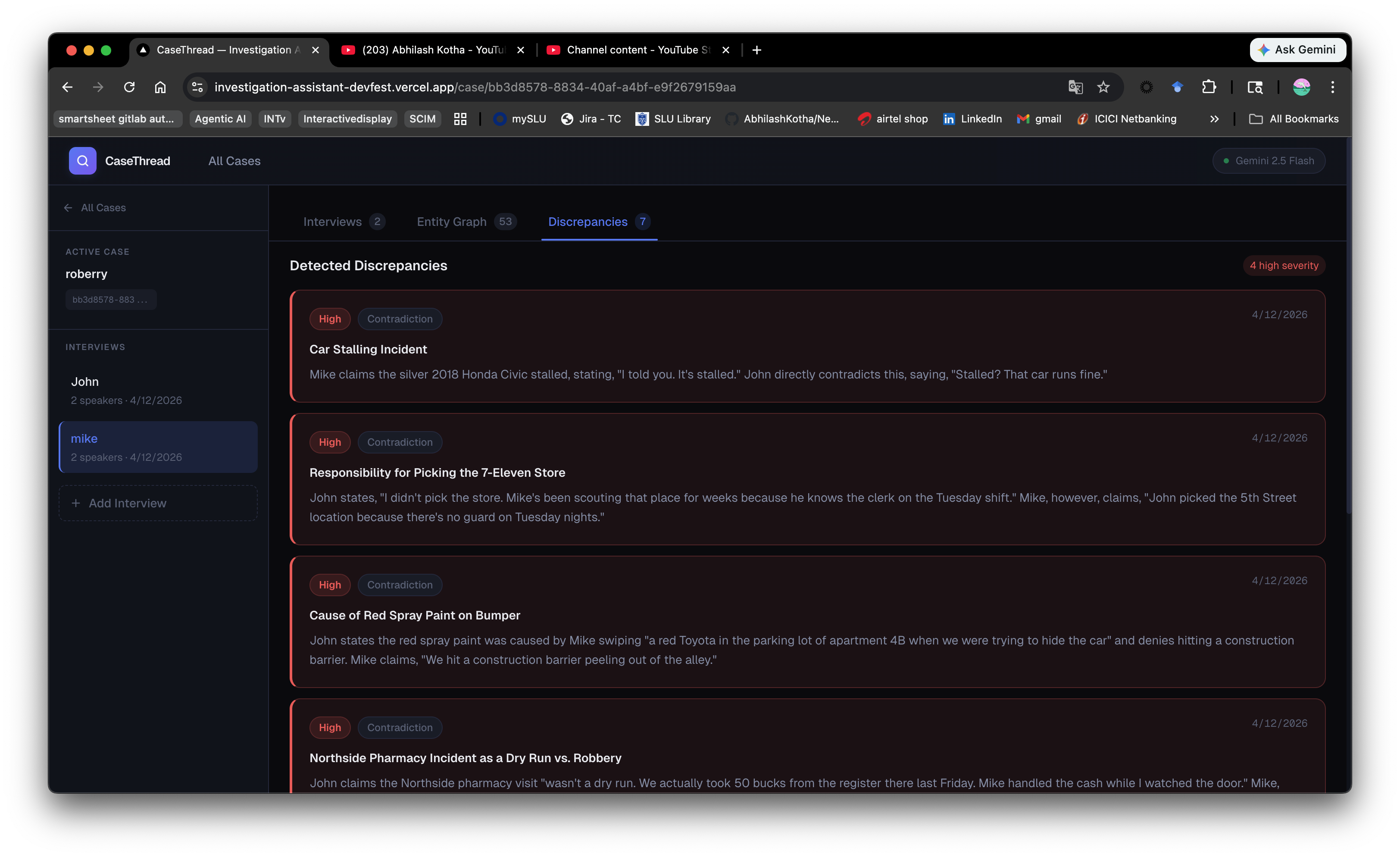
Discrepencies
Inspiration:
A real-world need - investigations rely on comparing multiple interview transcripts manually, which is time-consuming and error-prone.
What it does:
The core functionality - transcribe, identify speakers, extract entities, build graphs, detect discrepancies across 2+ interviews.
How we built it:
The tech stack and approach - Gemini 2.5 Flash for everything, Firebase Firestore, React Flow for visualization, Next.js frontend.
Challenges:
Real obstacles encountered - Gemini model availability, GCS bucket permissions, handling long audio, building incremental analysis.
Accomplishments:
Key wins - accurate transcription, smart entity extraction, visual relationship graph, only running discrepancy detection with 2+ interviews (not wasteful).
What we learned:
Technical insights - multimodal AI is powerful, Firestore transactions are tricky, entity deduplication is hard, incremental analysis requires careful state management.
What's next:
Future features - audio playback at timestamp, collaborative editing, export to PDF reports, integration with law enforcement DBs, speaker confidence scores, real-time collaboration.

Log in or sign up for Devpost to join the conversation.