What it doesSmartAgentX: Reinforcement Learning for Case Closed
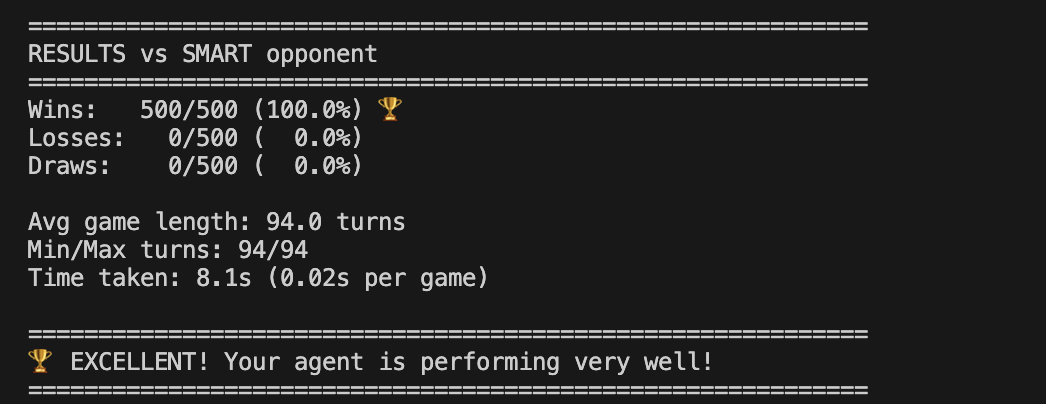
🎯 Inspiration We were tired of seeing agents that just survive. We wanted one that wins. The challenge? Build an AI that can outsmart opponents in a deadly grid where one wrong move = instant elimination. Traditional rule-based approaches fail because they're reactive. We needed something that learns, adapts, and predicts. Core Idea: What if our agent could learn to trap opponents instead of just avoiding death?
🧠 What We Learned Technical Skills
Q-Learning fundamentals - Building state-action value tables from scratch Reward shaping - Balancing immediate vs. long-term rewards Spatial analysis - Flood-fill algorithms and corridor detection Pattern recognition - Tracking and predicting opponent behavior Docker optimization - Keeping images under 5GB with CPU-only constraints
Strategic Insights
Early aggression beats passive play Territory control > survival in most cases Boost timing is critical (use early or save for emergencies) Opponent patterns repeat—exploit them Multi-phase strategies outperform single-strategy agents
Hard Lessons
Q-tables grow fast - Had to implement smart state bucketing Exploration vs exploitation - Finding the right ϵ\epsilon ϵ took 50+ test runs
Trap detection is expensive - Limited recursion depth to stay performant Learning takes time - 1000+ matches needed for solid Q-table





Log in or sign up for Devpost to join the conversation.