-
-
Hero Section
-
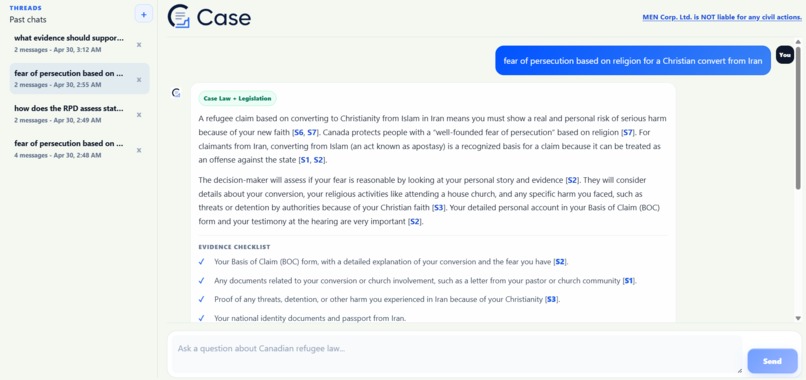
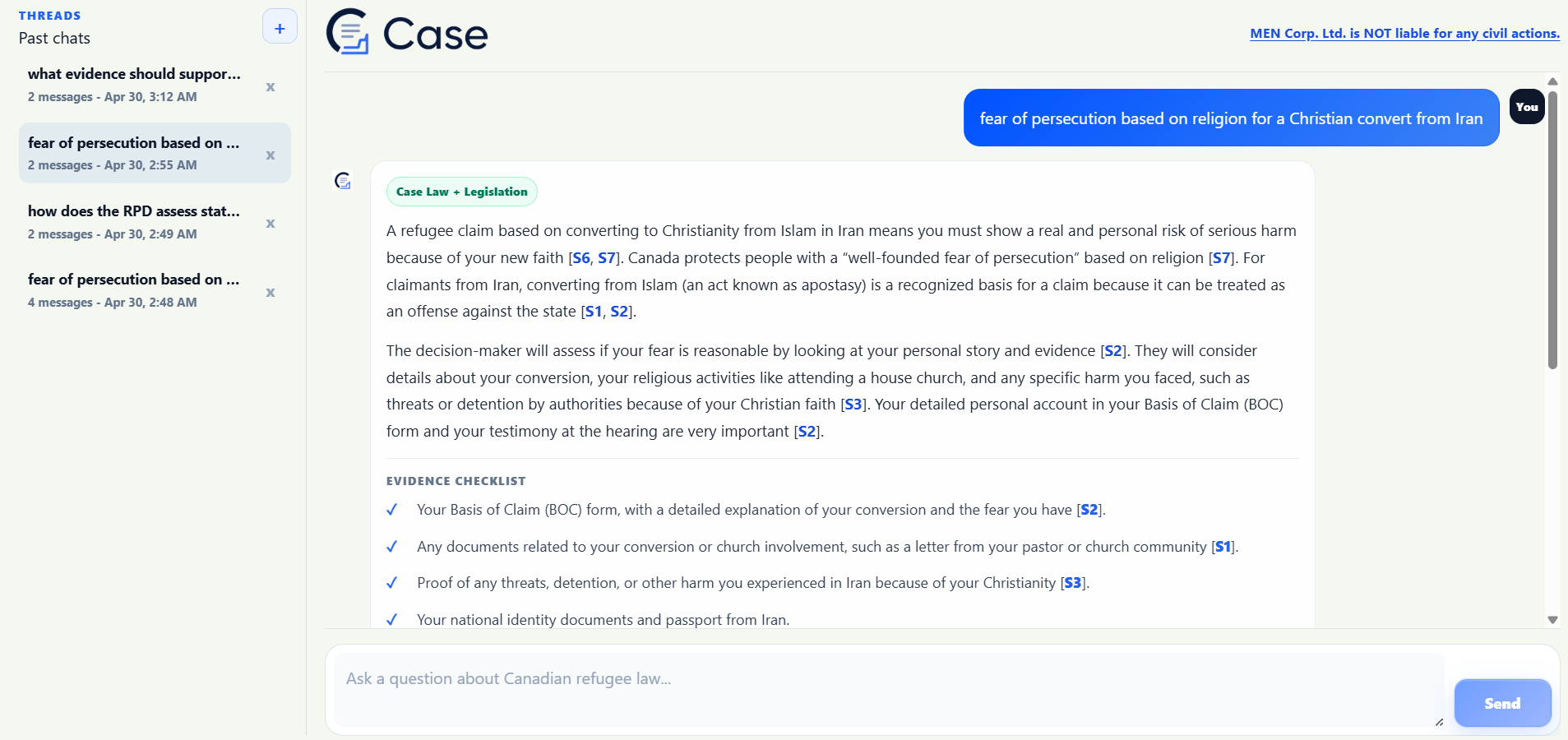
Chat Interface
-
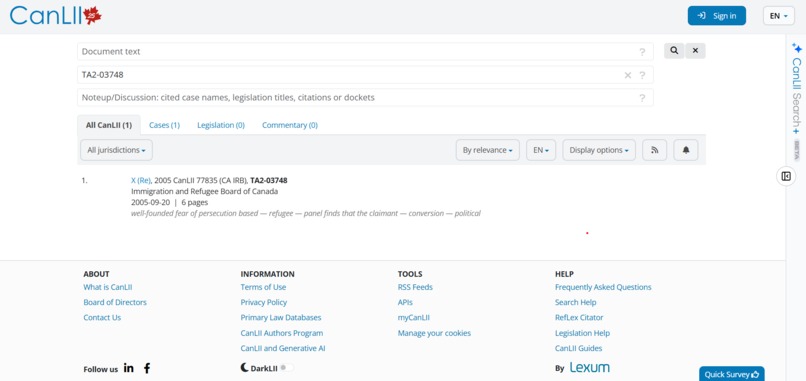
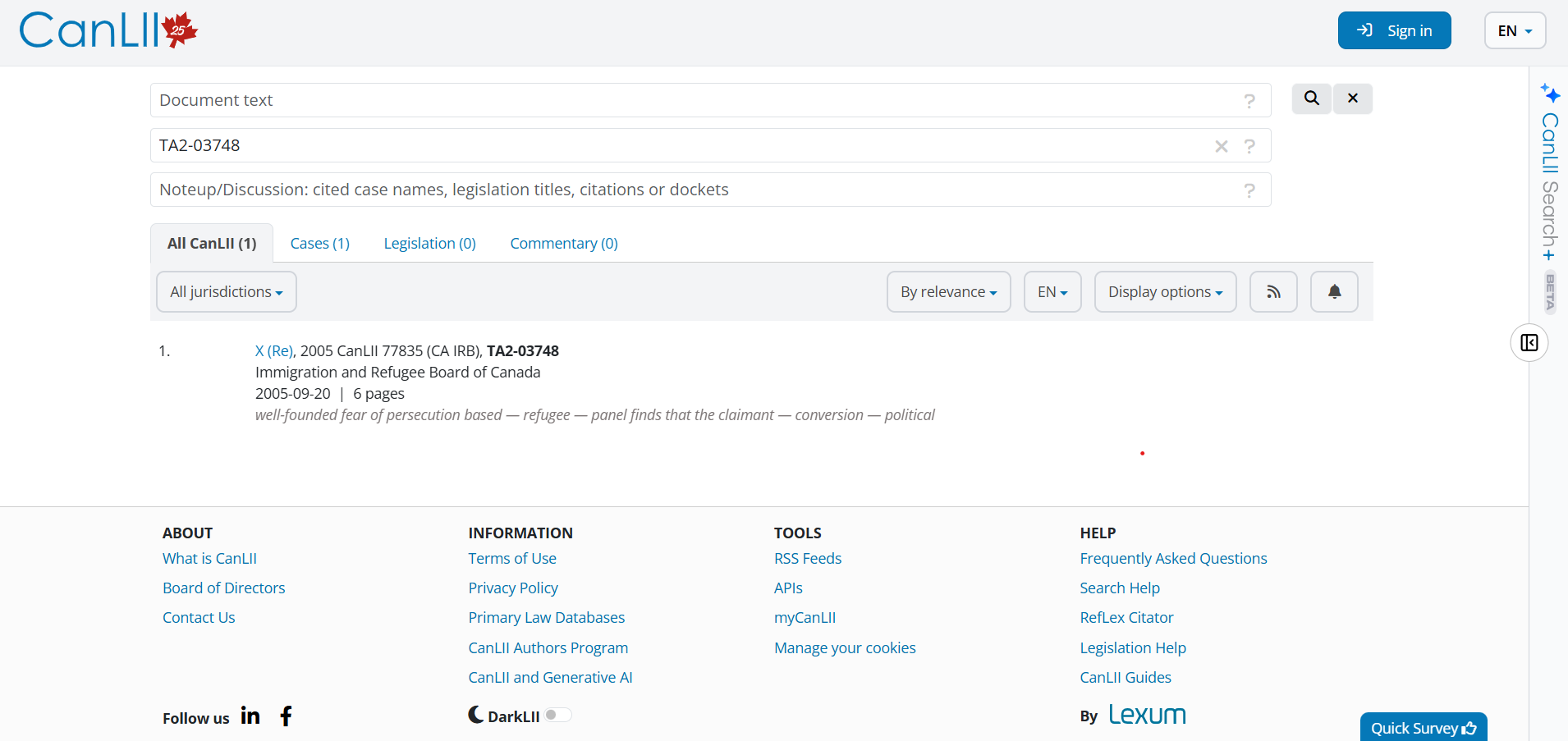
Links redirect to CanLii, official Legal Documentation
Inspiration
Imagine fleeing your home country, only to be handed a dense, 50-page legal decision dictating your future. Case came from a simple problem: refugee claimants and their supporters often face legal jargon that is impossible to decode quickly. We wanted to make Canadian refugee law accessible by turning complex RPD/RAD case law into clear, structured guidance that people can actually use.
What it does
Case is a RAG-powered legal assistant for Canadian refugee law. A user describes their situation in plain language, and Case returns:
- A plain-language explanation of the legal issue
- Relevant case law pulled directly from the dataset
- An evidence checklist to help prepare their claim
- Source citations for every claim to ensure transparency
- A clear disclaimer stating "This is not legal advice"
How we built it
We built Case as a full-stack system:
- Frontend: Next.js + TypeScript + Tailwind for a clean, intuitive user experience.
- Backend: FastAPI endpoint (/ask) for smooth orchestration.
- Retrieval pipeline: LangChain + Snowflake Cortex Search for highly accurate semantic document retrieval.
- Data: Filtered the A2AJ Canadian case law dataset to only RPD/RAD decisions, processing [Insert Number] records.
- Preparation flow: Cleaned the data, chunked it into overlapping text segments, loaded it into Snowflake, and indexed it in a Cortex Search service.
- Generation: Gemini is prompted to produce a structured JSON response grounded only in the retrieved documents.
Challenges we ran into
- Grounding vs. fluency: Keeping responses helpful while strictly preventing uncited or hallucinated claims, which we managed through rigid system prompting.
- Data quality: Cleaning, filtering, and shaping raw legal decisions into retrieval-friendly chunks required iterative testing to get the segment overlap just right.
- Schema consistency: Enforcing one reliable response format across varied user questions, a hurdle we cleared by strictly enforcing JSON schema generation in Gemini.
- End-to-end integration: Connecting frontend, backend, retrieval, and generation reliably under hackathon time constraints meant we had to test modularly before our final merge.
Accomplishments that we're proud of
We didn't just build a generic chatbot, we built a trustworthy legal information tool with strict safety constraints for a high-impact domain. Processing a raw legal corpus into production-style retrieval data was a massive hurdle, and successfully setting up Snowflake Cortex Search to validate semantic retrieval proves this architecture can work in the real world. Designing a citation-first response format establishes a strong base for genuine utility.
What we learned
- Domain-specific RAG quality depends heavily on data prep and chunking strategy.
- Strong prompt constraints and output schemas are critical for trust in legal contexts.
- Retrieval quality and metadata design directly influence user confidence.
- “Not legal advice” isn’t enough alone, you need transparent citations and clear boundaries in every response.
What’s next for Case
- Finish and harden the /ask flow end-to-end (frontend ↔ backend ↔ retrieval ↔ generation).
- Add stronger citation validation and fallback handling for low-retrieval-confidence queries.
- Improve UX for follow-up questions and document/evidence organization.
- Expand beyond RPD/RAD over time while preserving strict grounding guarantees.
- Add evaluation/benchmarking (accuracy, citation coverage, hallucination rate, and usefulness with real user scenarios).

Log in or sign up for Devpost to join the conversation.