-
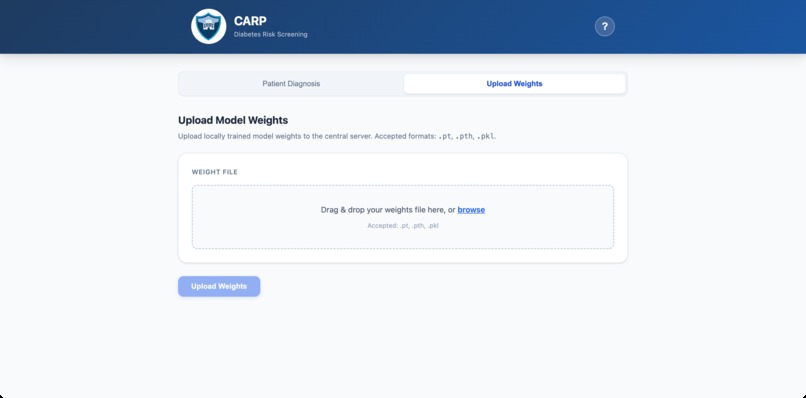
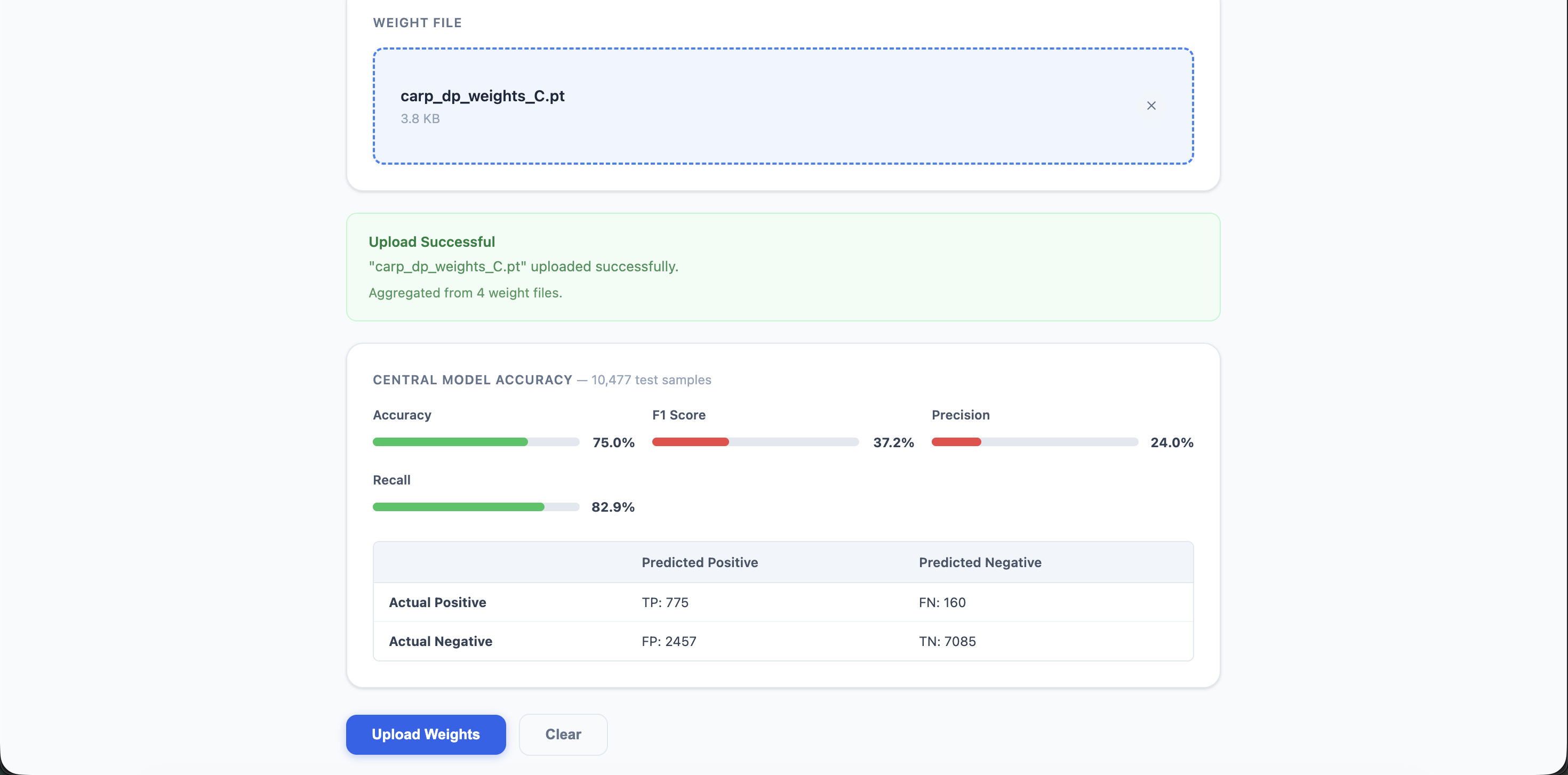
Central Server Weights Upload
-
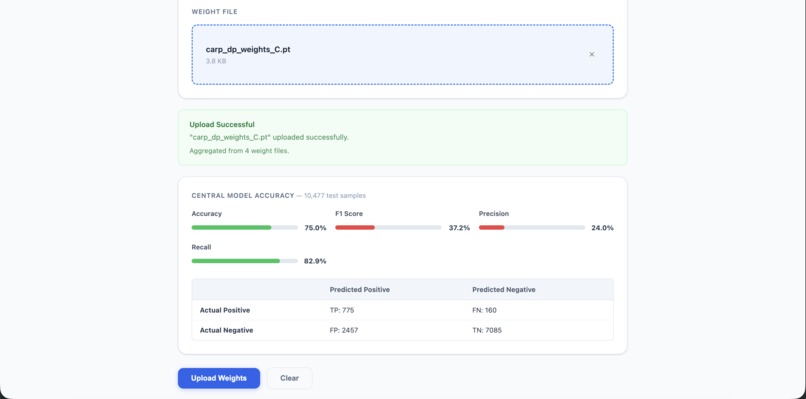
Central Server AI Analysis Example
-
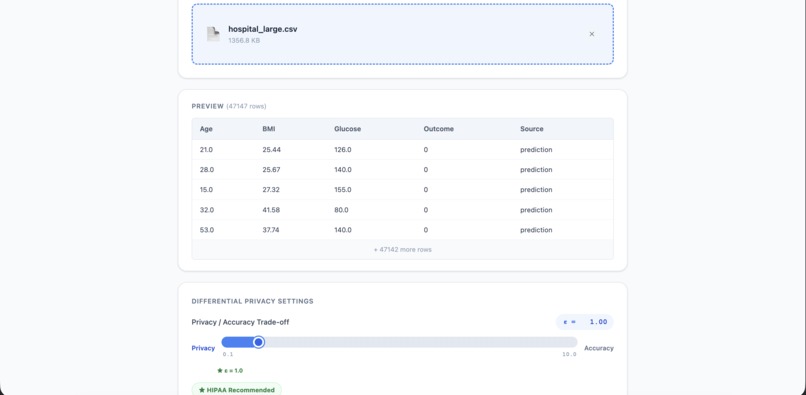
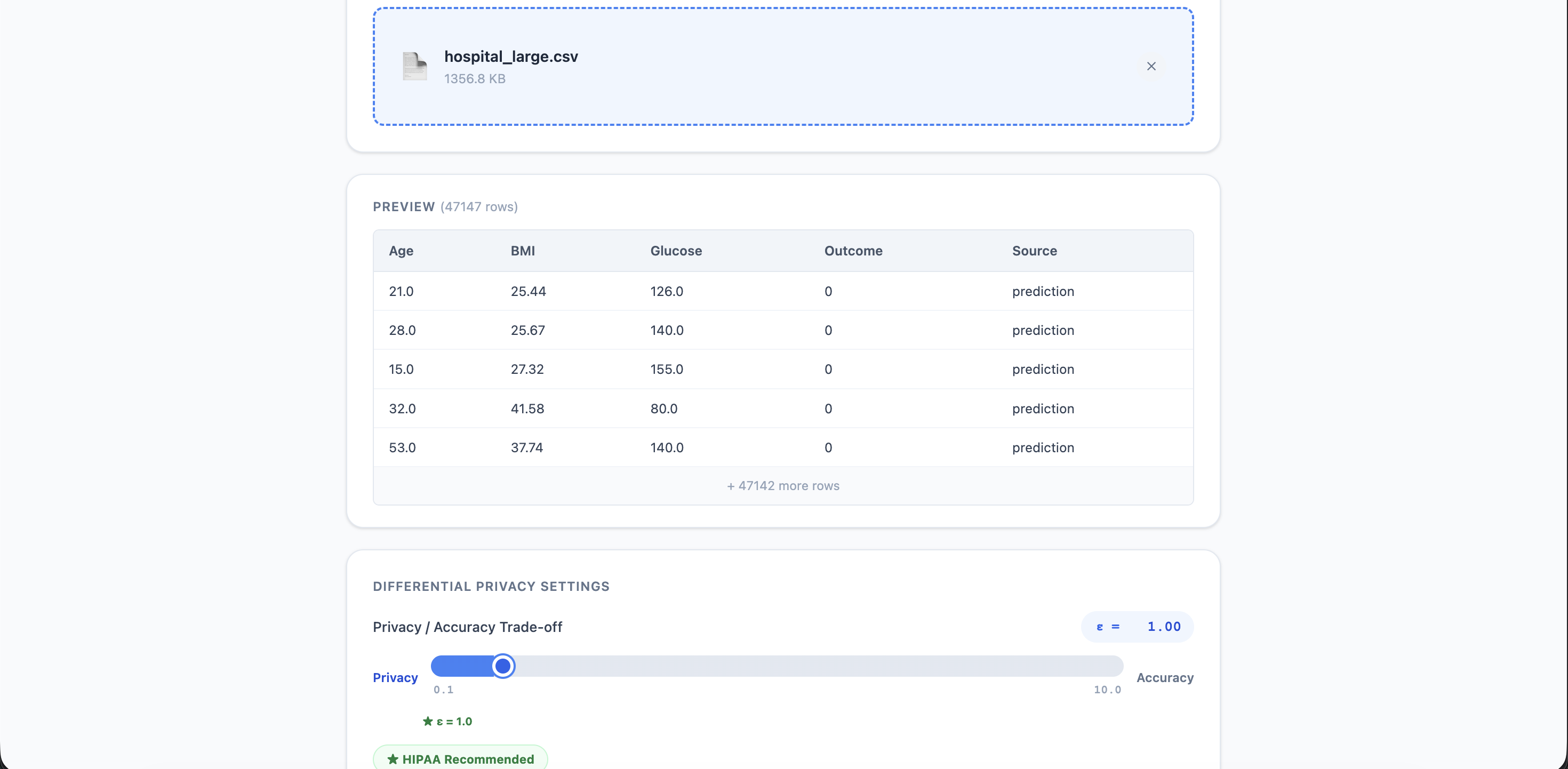
Hospital Client CSV Uploaded
-
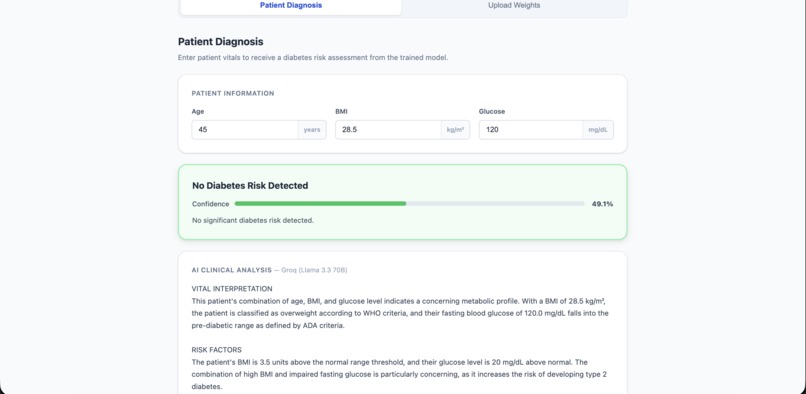
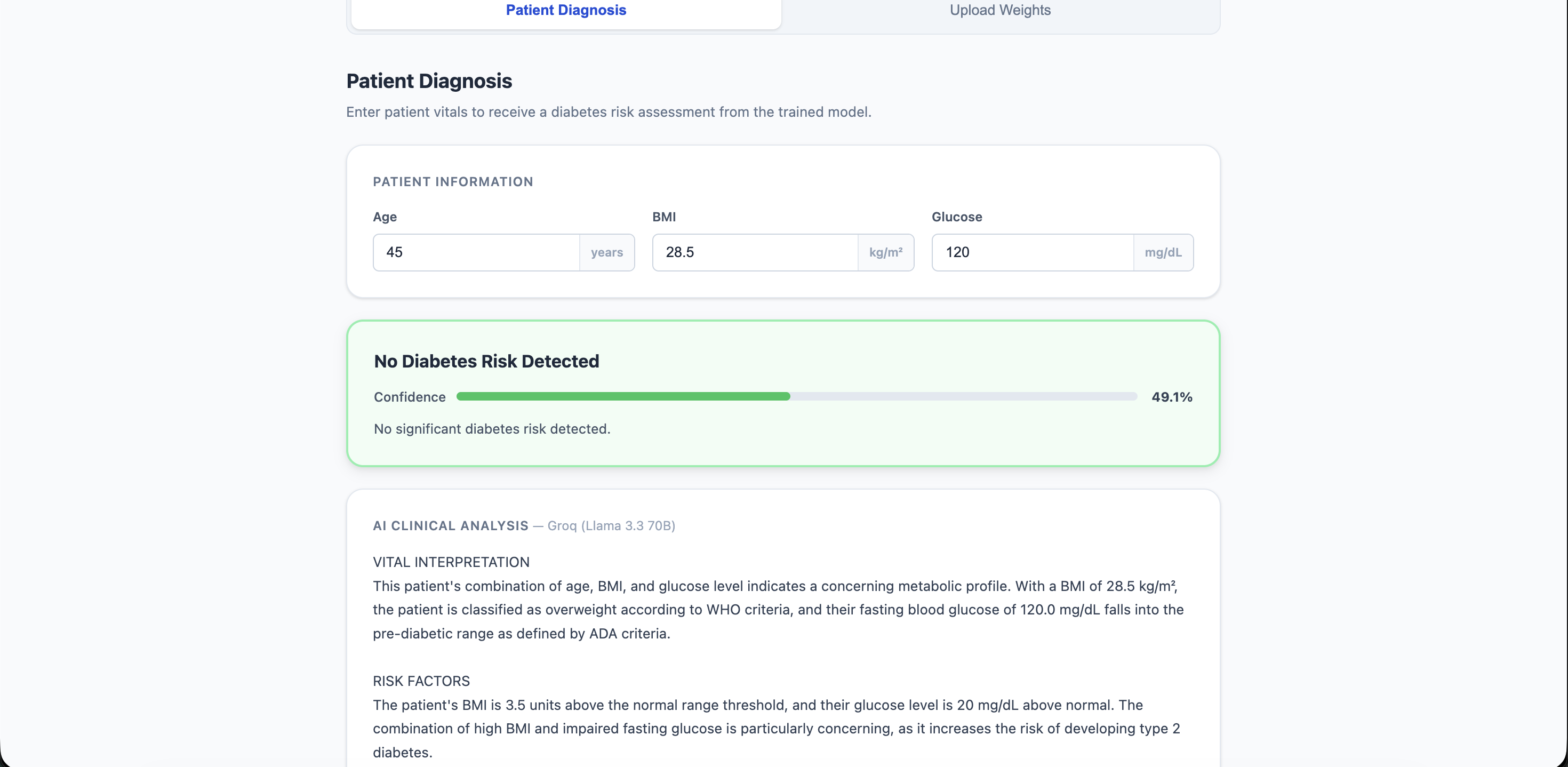
Central Server Model Query with AI Analysis
Inspiration
Many corporations in fields like healthcare, finance, and more hold sensitive data. Although open-source artificial intelligence on such data could advance research, raise millions, delight customers and save lives, it is misconceived that private data means no public AI. CARP challenges this misconception with a specific example of predicting diabetes with AI in the healthcare setting, demonstrating the powerful applications of differential privacy. It is more than a reinvention of classical disease prediction and hospital guidance AIs, it's a challenge to organization and corporations to leverage privacy-preserving computation for greater good.
What it does
CARP, standing for the authors of the program Charles, Alex, Russell, and Peter, is an infrastructure that enables a smooth pipeline from hospitals to open-source AI. It consists of two main components:
Hospital Client (local) The hospital client is a clean frontend which enables data upload through CSVs. Meant to be run locally by the hospital, the client is a pipeline from sensitive data to meaningful weights which can be relocated to contribute to the public AI model, all while revealing virtually no individual information about patients. The client analyzes data size (classifying into small, medium, and large), and runs a differential privacy artificial intelligence model with custom configurations optimized to suit the data. A privacy slider enables the hospital to toggle the differential privacy noise, with $\epsilon = 1$ being a HIPAA recommended standard, whereas a larger $\epsilon = 10$ meaning they are willing to contribute the data more freely without security concerns. After uploading the data and configuring the noise, hospitals can run "Train Weights" and download the outputted weights, which they can manually move to the upload of the public AI model on the central server when ready. Beyond just the weights, a version of the AI model trained on just their dataset is supplied, where hospitals can enter mock data and experiment with it. To ensure not just individual privacy through differential privacy, but also hospital privacy, a mask is supplied. Through adding shared randomness to the weights as a mask, hospital data is only contributed to the central server every three hospitals, mitigating attacks attempting to analyze trends of a specific hospital.
Central Server with Public AI (global) The central server is a clean frontend which enables hospitals to upload weights through .pt files. It offers a open-source exportable AI model which is trained on weights from all uploaded hospitals with randomness decoded. This allows users to enter personal data like Age, BMI, and Glucose Levels to get a diabetes risk percentage, along with a Gemini/Groq AI in-depth guidance summary. All uploaded hospital weights are stored in a PostgreSQL database. The public model aggregates these weights through federated training, averaging the model parameters per hospital. A clear log of aggregation history is also supplied.
Both the hospital client and central server are Dockerized, enabling smooth deployment in a real-life setting.
How we built it
We envisioned this project when realizing that many finance and healthcare corporations that we talked to don't think open-source artificial intelligence applied to them, since they had sensitive data. We came across the powerful notion of differential privacy, and immediately began envisioning a system to streamline the process, particularly to appeal to those who were unfamiliar.
Our team started with a rudimentary scaffold of a extremely poorly trained and basic PyTorch model running on diabetes prediction data (a common dataset). We implemented differential privacy on this model with Opacus and set up the frontend (React) and backend (Flask) frameworks for the hospital client and central server, constructing a strong baseline to improve. Realizing our dataset was vastly too small for differential privacy due to inherent loss from the noise which ensures the privacy in the first place, we consolidated multiple datasets and vastly decreased our parameters. We decided this was a reasonable sacrifice for a hackathon product, as in practice hospitals would have much larger and more comprehensive datasets, and our parameter size is easily scalable when moving to production.
We split up our team, with Peter and Russell tackling the hospital client and central server front-end respectively, while Alex and Charles worked on improving and tuning the base model and differential privacy model. When both frontend and backend were finished, they were cohesively combined.
Next, we began brainstorming next-step improvements. We decided to make it easier for hospitals to use that we would Dockerize both the hospital client and central server, which Alex tackled. We cleaned up the front end further and added Gemini/Groq insights, a help snippet, PostgreSQL database weights storage and more. We also decided to add a mask functionality to further improve privacy, protecting hospitals themselves as a whole. Realizing that different dataset sizes might train differently on the hospital client side as our configurations were designed for half the 100k dataset, we decided to split it into a small, medium, and large dataset for the demo and make the configurations match the dataset size for a stronger model.
Challenges we ran into
Our development journey was nothing short of challenges. Less fluent on the front of artificial intelligence, let alone differential privacy, tuning solid artificial intelligence models was a cat and mouse game that required a lot of researching, learning, and collaborating. While the pieces of the puzzles were set, gluing them together cohesively and considering further advancements was a long, difficult process. Resource limitations in API keys and more required collaborative efforts to find alternatives of workarounds.
Accomplishments that we're proud of
We're super proud to deliver this working pipeline which showcases some of our effort, grid, creativity, and ingenuity. Most importantly, we're excited to show that differential privacy is a powerful tool which can produce profound impact in the real-world. Our project showcases its strengths and weakness, the privacy preservation and the hardships and flaws. It embodies a collaborative spirit of engineering solutions, leveraging tools, and analyzing problems. We are more than excited to showcase our project to the world through judging and beyond.
What we learned
Over 24 hours, we learned more than we could've ever imagined about artificial intelligence, python libraries, differential privacy, and web development. But beyond the technical skills, we learned that collaboration, planning, delegation, and hard work can culminate in projects and milestones that even we are shocked to have achieved.
What's next for CARP
CARP is an awesome project that has so much potential for improvement. With so much theoretical and applied work on differential privacy, we can apply even more concepts to improve privacy and increase model strength. We currently train the base model with PyTorch and DP model with Opacus ourselves with our own parameters, but many open-source models are out there which would be great to try as a base model, like Llamas and Gemma. Although we deployed the hospital client and central server through Docker, deploying the central server on AWS could be even more realistic for a hospital setting. Given the scope of the hackathon, we made many sacrifices and chose not to go in these directions, opting for a stronger prototype in contrast to more exploration. This project could also be turned into a template in the future for any CSV dataset, not just healthcare.



Log in or sign up for Devpost to join the conversation.