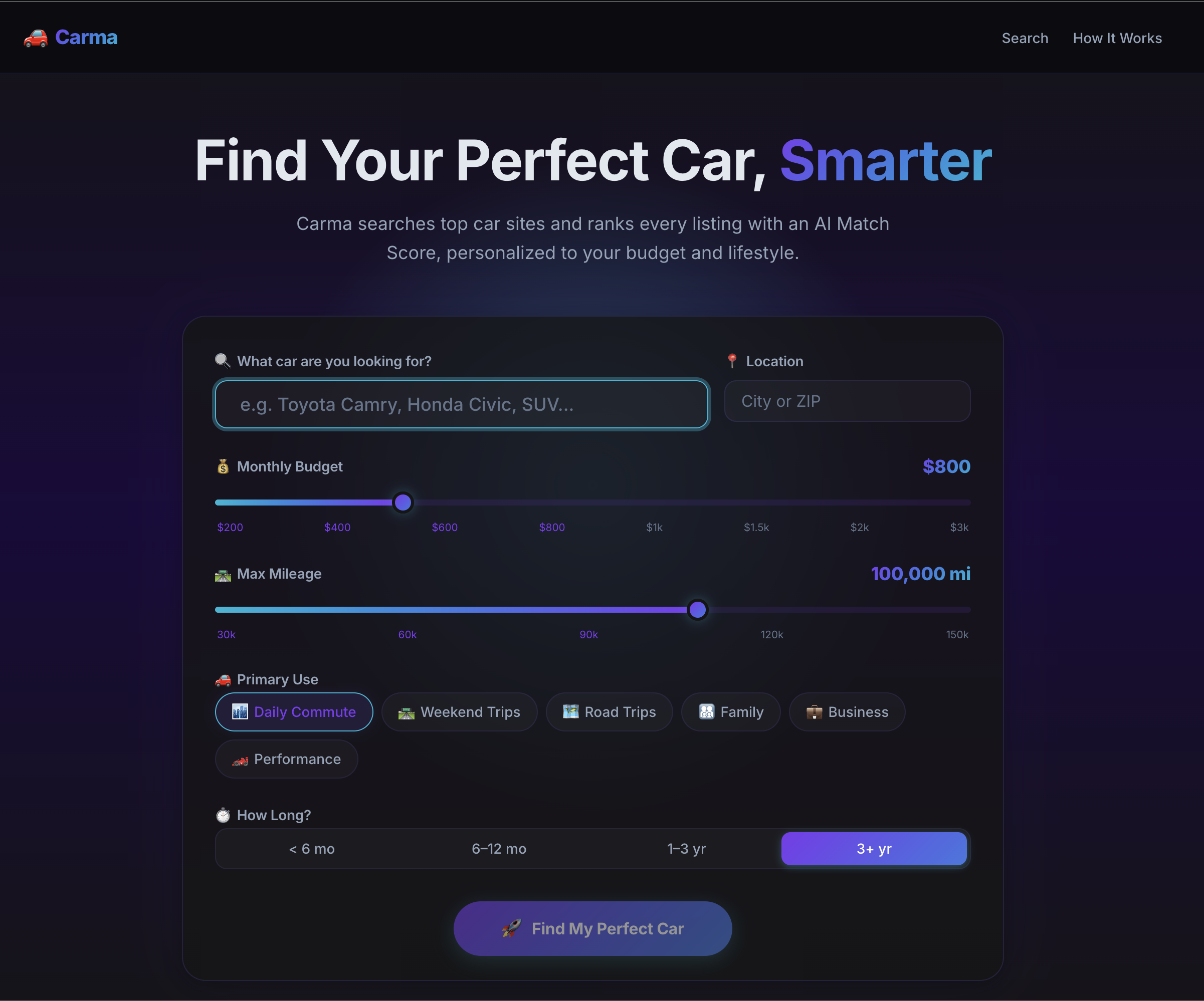
Inspiration
Buying a used car is miserable. You spend hours on Craigslist sifting through mostly irrelevant car listings, opening 40 tabs, maybe even googling reliability issues, and still have no idea if the price is fair. We wanted an agent that does all that for you. We wanted to be more than just a smarter search, but something that actually researches, reasons, and keeps watching.
What it does
CARMA searches Craigslist across the majority of the NorCal region, extracting and structuring every listing, showing you only the make and model you searched for. With Tavily, it then researches each car against real Reddit owner discussions to score reliability, flag unknown problems, and assess price fairness. If results are thin, an expansion agent autonomously reasons about alternative vehicles that fit your intent and searches those too. Once you have results, you can enable a Yutori Scout that monitors your exact search on the web 24/7 and alerts you when a better deal appears.
How we built it
A 6-stage Python pipeline: ABeautifulSoup and Tavily help extract Craigslist search pages and individual listings, a customer parser structures 25+ fields per listing, and a Reddit research agent using Tavily extract fires targeted searches against several subreddits that may be r/MechanicAdvice, r/whatcarsshouldIbuy, and r/honda to generate per-listing scores. Stage 6 is a true agentic loop using OpenAI function calling: the model decides which tools to call, observes results, and iterates until it's satisfied. Ongoing monitoring is powered by the Yutori Scouting API. The frontend is Next.js.
Challenges we ran into
Parsing structured fields from wildly inconsistent listing formats (private sellers vs dealers using markdown and SEO garbage) required a lot of slow and manual inspection. We ran out of time connecting the Stage 6 pipeline to the front end, where the page automatically refreshes to show the new similar listings the agent fetched. The agent works and fetches similar results, but it isn't yet refreshing and displaying on our website yet.
Accomplishments that we're proud of
We're proud of turning our project into a genuine agentic workflow, not just a scripted pipeline to scrape. The model observes results, makes a judgement call, decides what similar cars to search next, and loops until done. The Reddit research system surfaces real owner opinions at scale in a way that feels like having a knowledgable friend review every listing. The Yutori Scout integration means CARMA doesn't stop working when you close the tab. Furthermore, we were able to reduce thousands of listings of irrelevant cars (makes and models) to just a few hundreds of cars that actually match. And for less popular cars, we reduced several hundreds of listings to the few dozen or so that actually exist.
What we learned
The line between "smart pipeline" and "real agent" is autonomy over the action sequence. Most LLM pipelines are just scripted steps with a model in the middle - a real agent decides its own next step based on what it observes.
What's next for Carma autonomous agent
We wish we had more time to continue truly turning the rest of our "smart pipeline" to a "real agent". We want to let users describe their needs conversationally ("I need something reliable for a long commute, under $400 a month") and have the agent interpret intent rather than just key words. We want to expand coverage to more websites and add VIN look up.
Built With
- beautifulsoup4
- dotenv
- javascript
- next.js
- nextjs
- openai
- python
- react
- render
- tavily
- yutori

Log in or sign up for Devpost to join the conversation.