-

Outline for CARL Data Analysis
-

Enter in any article you'd like
-
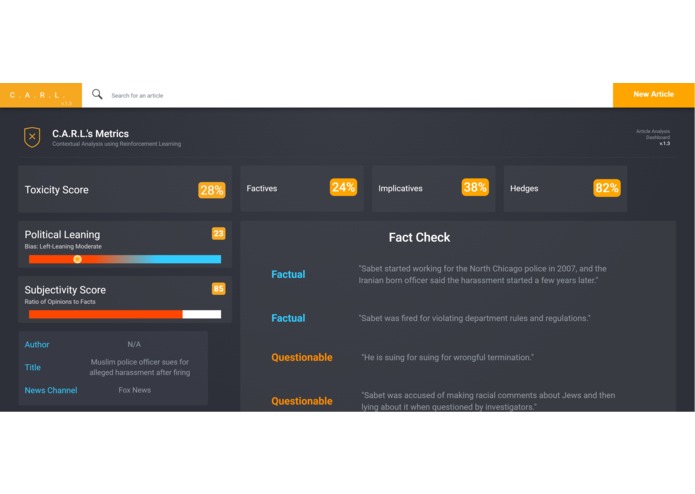
Analysis Page with all the article information


Inspiration
Recently, fake news has been major problem in our daily lives. News about Hillary Clinton running a underground and possibly satanic child sex trafficking ring. In fact, a couple individuals broke open the ping pong shop with guns to "relieve the children". Post truth is Merriam Webster's word of the year. Post Truth is defined as the feelings or emphasize behind a "fact" make it true. Post truth is a major problem in our society. However, Donald Trump has been accusing the most credible news sources, like CNN and NBC, of "fake" news. This has begun to erode consumer confidence in the media. CARL wishes to solve that by creating a quantitative value for how fake an article is, its "bias" or political leanings, and how toxic it is to society.
What it does
Analysis of toxicity of article, subjectivity of article, bias within the article, and fake news "facts".
How we built it
Backend: Django, R server running R and Python. The system was built with reinforcement learning and a lexicon classifier, trained with a proprietary data set. Frontend: HTML, bootstrap theme
Challenges we ran into
Connecting the backend and frontend servers, programming dynamically in R: R is a very statistically analytic and static language and making it dynamic proved to be difficult.
Accomplishments that we're proud of
The backend aspect. We wrote the data processing and data science aspect form scratch and are able to have the accuracy of the bias at the level of research papers.
What we learned
Deploying Linode servers and configuring them for RStudio, rebalancing and weighting lexicon criteria, and implementing a Support Vector Machine in R.
What's next for CARL:Contextual Analysis Using Reinforcement Learning
Implement it into daily research practices and develop a "derived" site which organizes news based on our specific analytics. Continue algorithm analysis for using these scores combined with sentiment to trade and generate alpha.



Log in or sign up for Devpost to join the conversation.