-
-
Search
-
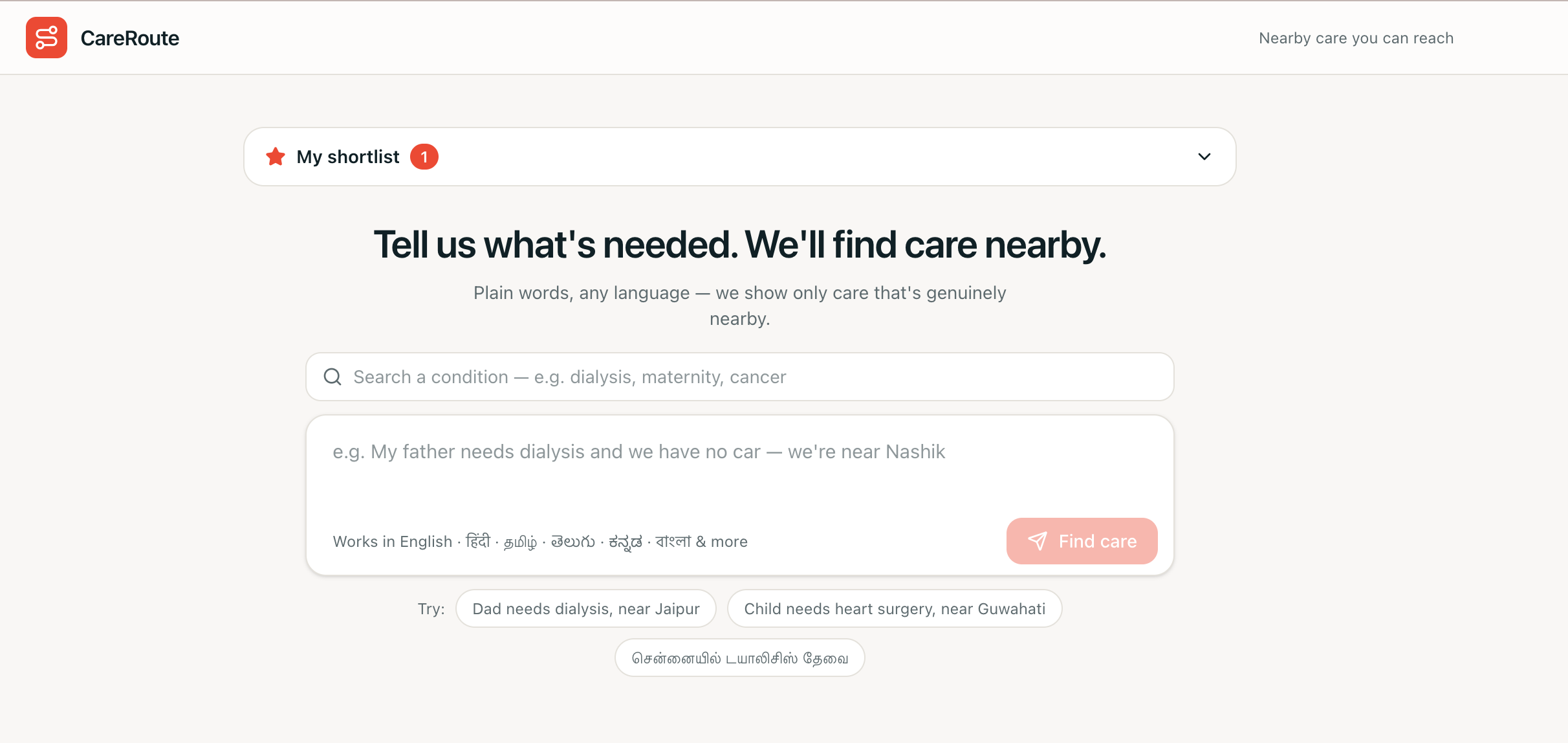
CareRoute Landing Page
-
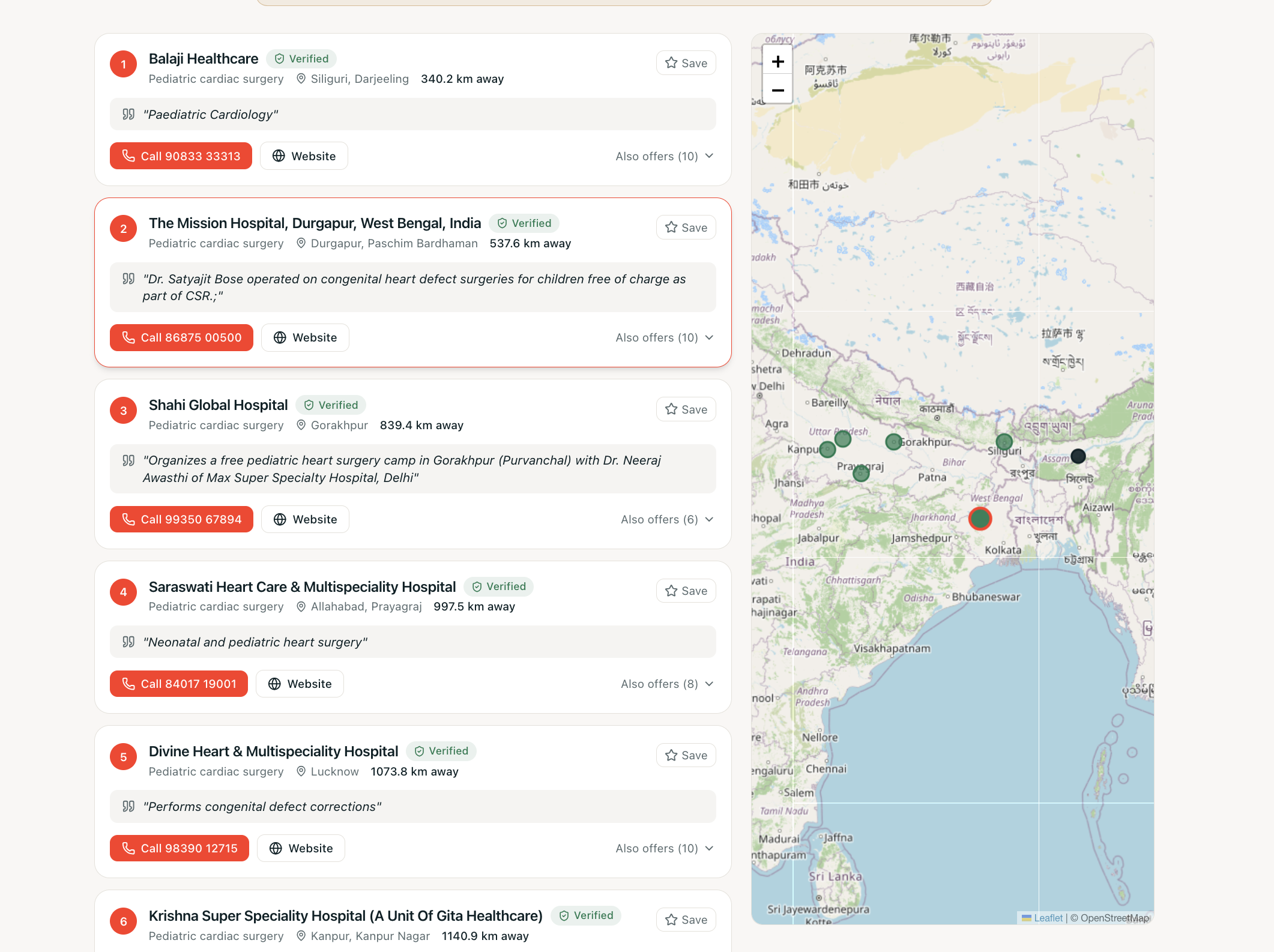
Results
💡 Inspiration
In India, a family trying to find care for a sick parent has no reliable way to know which nearby facility can actually do what's needed. Public directories are stale and list specialties, not capabilities; phone-tag wastes days while a time-critical patient — needing dialysis, a high-risk delivery, or cardiac care — waits. The cost of a wrong referral is brutal: a family sent hours away to a hospital that can't help. We wanted a tool that is honest first — one that would rather say "the nearest option is far, call before you travel" than fake a convenient answer.
🩺 What it does
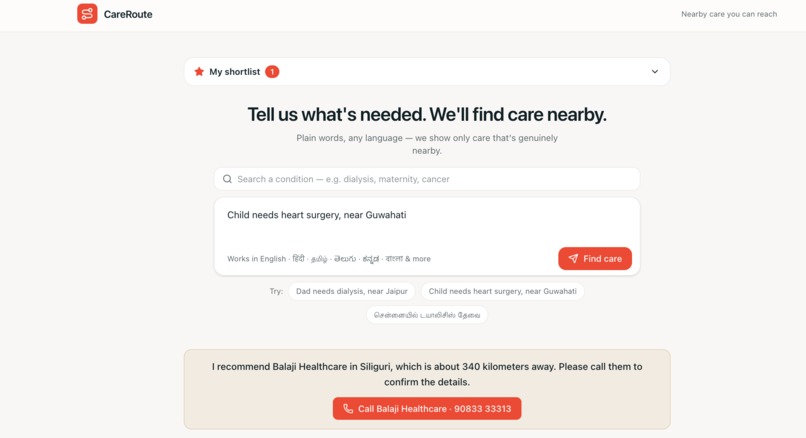
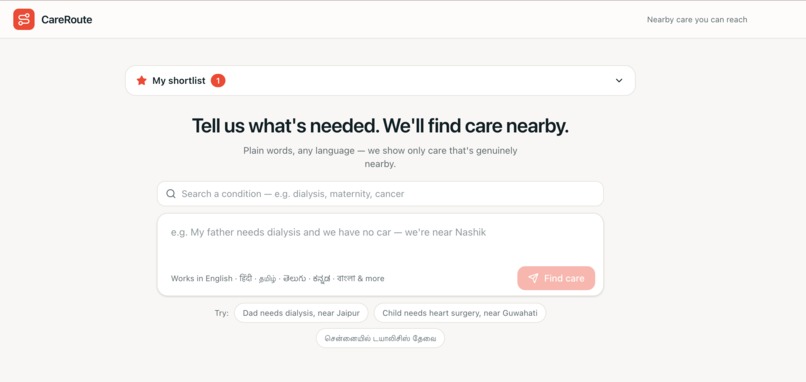
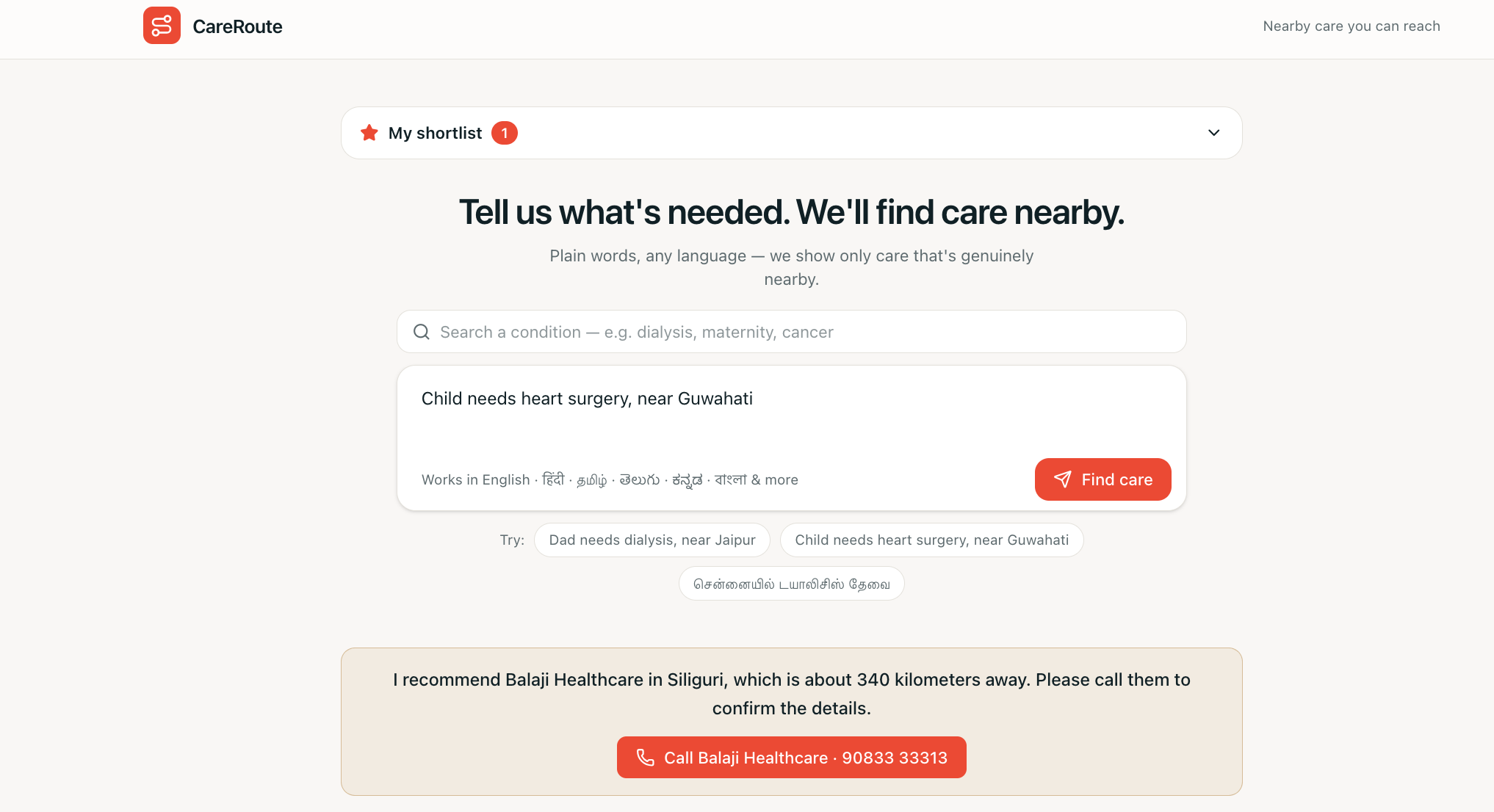
Anyone — a family member, a patient, a community health worker — types the situation in plain language, in any major Indian language ("68-year-old man needs dialysis, near Jaipur" / "ಹುಬ್ಬಳ್ಳಿಯಲ್ಲಿ ಡಯಾಲಿಸಿಸ್ ಬೇಕು" / "my father has chest pain and swollen legs, near Kargil"). CareRoute:
- Maps the need to a clinical capability from a 32-item controlled vocabulary — or honestly declines if nothing fits. It never guesses.
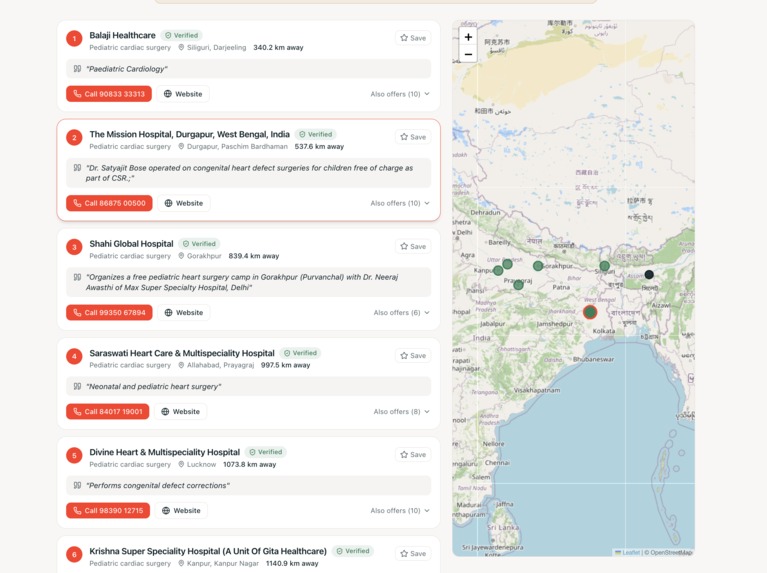
- Finds facilities that explicitly provide it, ranked by real distance, and leads with one clear recommendation and a tap-to-call number, in the user's own language.
- Shows the proof — the verbatim text from each facility's own listing ("On-site dialysis facility") — plus a trust badge: Verified (free-text evidence) vs call to confirm (specialty-listed only).
- Stays honest about distance — for a rare need in a remote district it says "the nearest is ~159 km away, call before you travel" instead of overclaiming.
- Lets users save a shortlist, add notes, and track each decision (shortlisted → called → confirmed → referred), persisted in Lakebase.
🛠️ How we built it
- Messy data → grounded capabilities. ~10,000 raw facility records across all of India run through a medallion pipeline (Unity Catalog) and three extraction passes: a clean specialty taxonomy, a lay/clinical keyword index, and OpenAI
gpt-5-miniexplicit-only extraction that copies the exact grounding quote. A second LLM verification pass adjudicates keyword-only claims (12,096 of them → 1,105 promoted to Verified, 10,991 over-claims deleted). Result: 85,897 (facility, capability) referrals · 9,952 facilities · 549 districts · 32 capabilities · 53% evidence-Verified. - All three provided datasets. facilities → the capability table; india_post pincode directory → the district/city geocoder; NFHS-5 → per-facility public-health context.
- Geo at serving speed. Databricks Spatial SQL (
ST_DistanceSphere,ST_DWithin) + H3 cells assign every facility to a district and power fast nearest-facility ranking. - Served from Lakebase. Gold tables are reverse-ETL'd into Lakebase (autoscale Postgres) and read by a Databricks App (AppKit — TypeScript + React + Express) for sub-100ms lookups. Realtime case parsing and the localized summary use OpenAI
gpt-4o-mini. - UI. shadcn/Tailwind on the Databricks brand palette with a Leaflet/OSM map, and honest, plain-language copy for non-technical users.
✅ How it meets the requirements
- Databricks App on Free Edition — yes (serverless-only workspace).
- Uses the provided facility dataset — all three Virtue Foundation tables.
- Non-technical workflow — one plain-language box (any language) → recommendation + ranked cards.
- Cites the underlying text — every card shows the verbatim capability quote; the badge separates evidenced from merely listed.
- Communicates uncertainty — a call-to-confirm tier, honest "nearest is far" verdicts, and a flat refusal when the need is outside coverage.
- Persists user actions — per-user shortlist + notes + decision status in Lakebase.
🧗 Challenges we ran into
- Free text over-claims (a keyword regex maps "cosmetic dentistry" → plastic surgery). Solved with the LLM verification pass, which pruned ~9% false positives no taxonomy/LLM row corroborated.
- Scaling to all of India hit Databricks' 25 MiB inline-result cap — we paged every large read.
- Autoscale Lakebase has no Delta synced-table API, so we built a snapshot reverse-ETL loader (psycopg COPY, schema-introspecting, idempotent TRUNCATE+COPY).
- Messy source data (coordinates/JSON leaked into columns; bare-domain websites) — handled defensively.
🏆 Accomplishments we're proud of
A differentiated take on "AI for good": honest, evidence-grounded referral with explicit refusal. Not a directory search — every recommendation is backed by the facility's own words, the trust tier replaces a fake "last updated" date, and the agent visibly refuses to overclaim. Plus genuine all-India, multilingual coverage.
📚 What we learned
Grounding beats fluency. The value isn't the model writing a nice paragraph — it's the system refusing to assert what the data doesn't support. A cheap realtime path (one fast parse call + deterministic ranking) over a carefully built offline dataset is both honest and fast.
🚀 What's next
Travel-time-aware routing, scheme/insurance filters, facility-reported freshness, and the Track-1 (facility trust audit) and Track-4 (data-readiness) views over the same grounded dataset.
Built With
- claude
- codex
- databricks
- databricks-apps
- databricks-sql
- express.js
- gpt-4o-mini
- gpt-5-mini
- h3
- lakebase
- leaflet.js
- mlflow
- openai
- postgresql
- python
- react
- shadcn-ui
- spatial-sql
- tailwindcss
- typescript
- unity-catalog



Log in or sign up for Devpost to join the conversation.