-
-
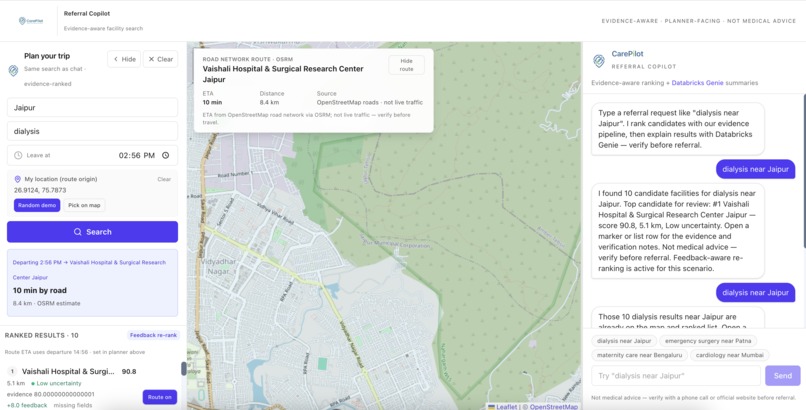
Asking & Searching
-
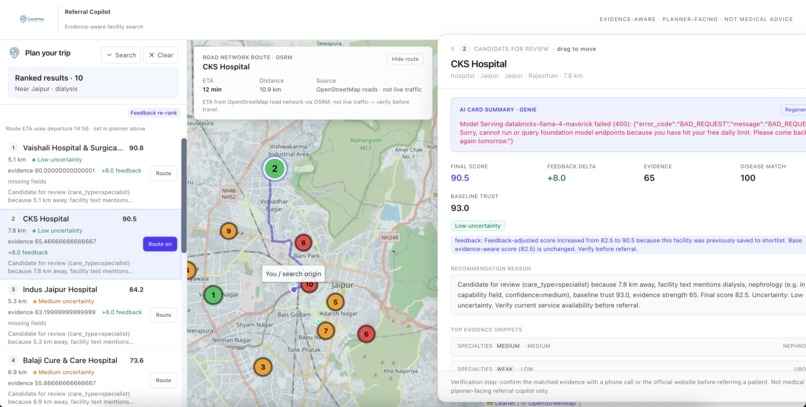
result & QnA
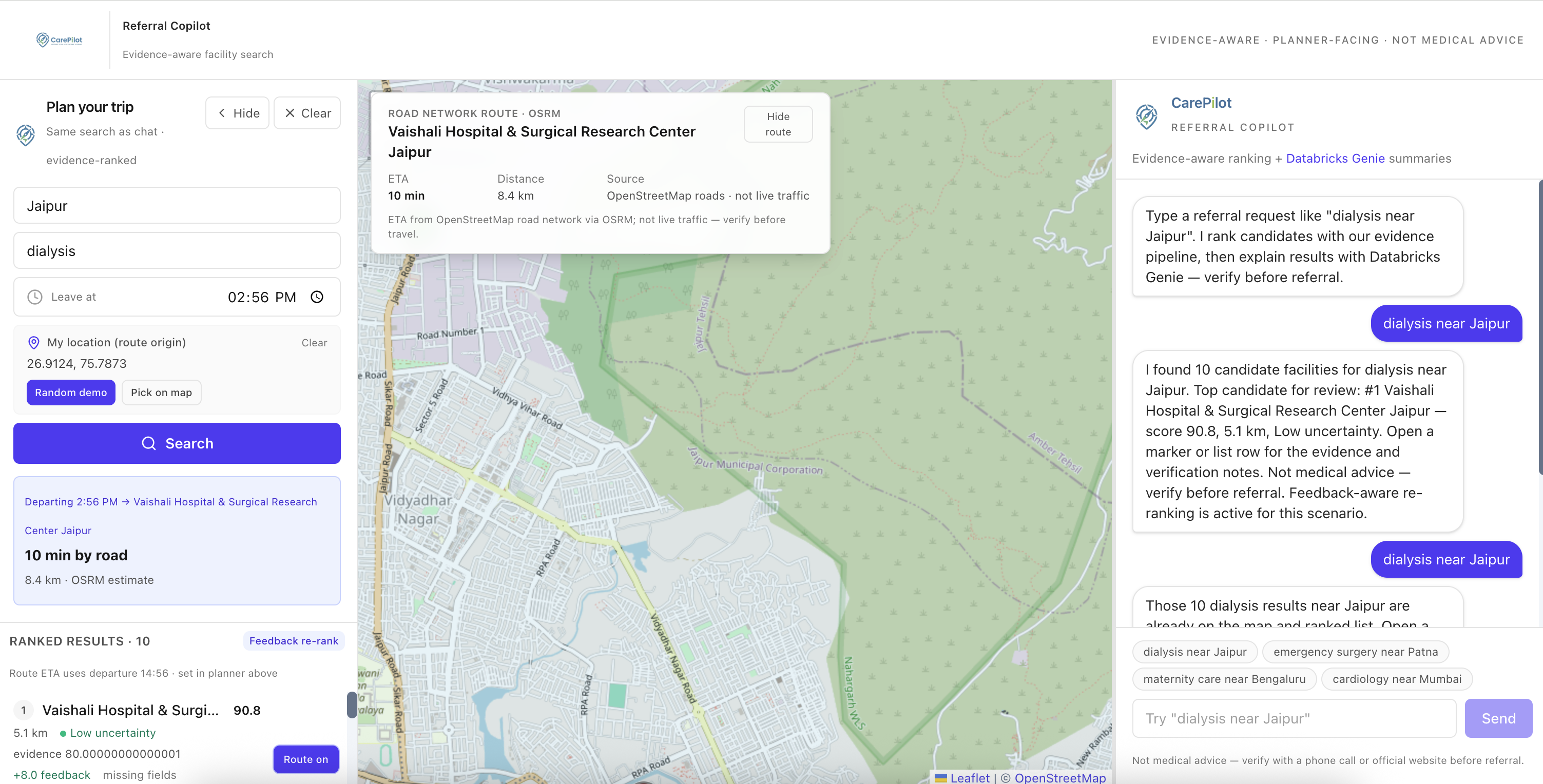
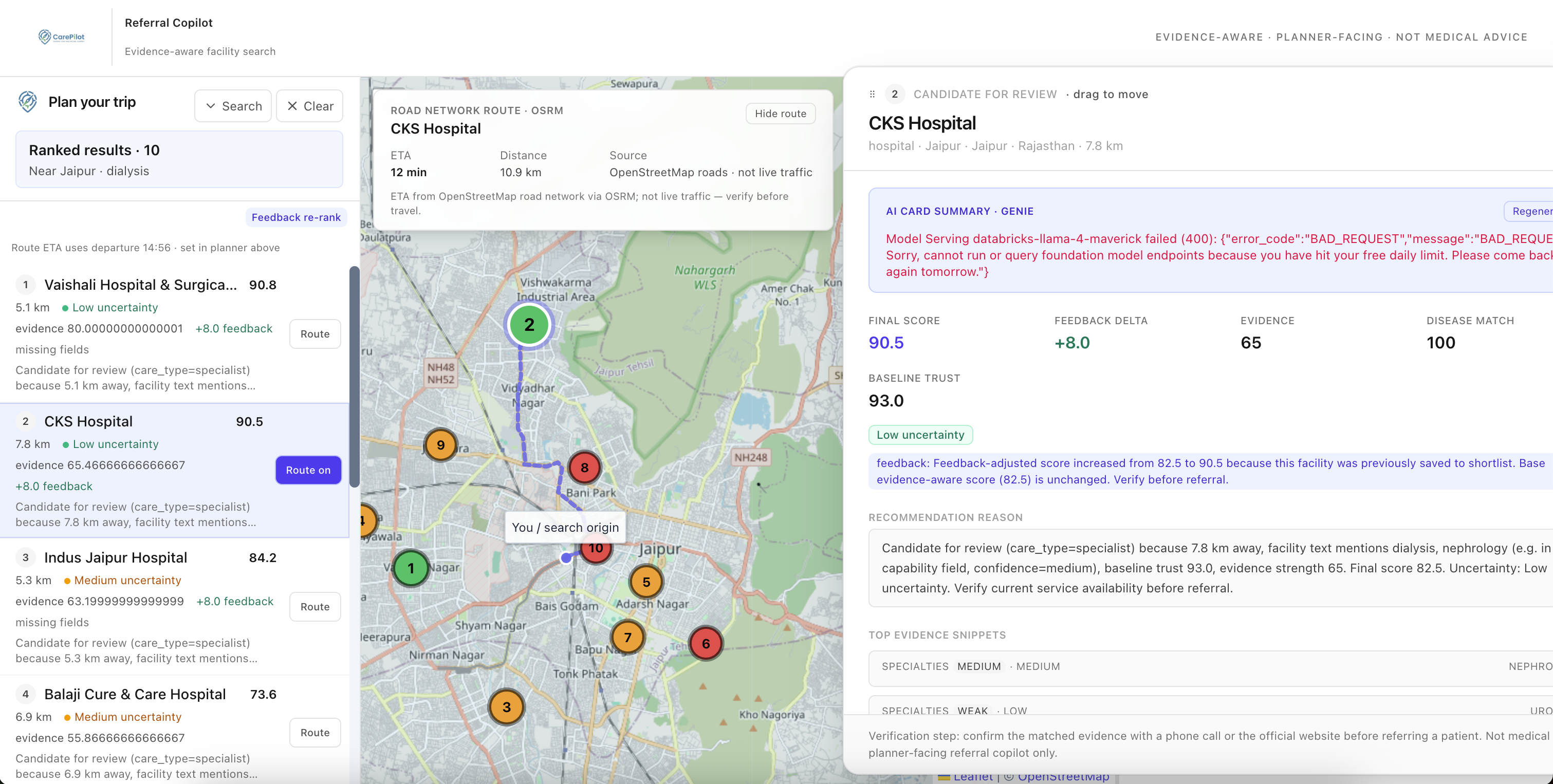
Inspiration
India has over 10,000 registered healthcare facilities, yet patients in rural districts routinely travel past closer, capable hospitals because no one knew they existed. The National Family Health Survey (NFHS-5) revealed stark disparities across India's 700+ districts: institutional birth rates ranging from $34.8\%$ to $100\%$, child stunting rates as high as $60\%$ in some regions. These numbers reflect a referral system built on word-of-mouth rather than data.
We asked: what if a frontline health worker could type "dialysis near Jaipur" and instantly get a ranked, evidence-backed shortlist? CarePilot is our answer.
What it does
CarePilot is an AI-powered referral copilot for healthcare planners. A planner types a natural-language request like "emergency surgery near Patna" or "dialysis within 50km of Jaipur", and CarePilot:
- Parses intent using regex patterns and a deterministic city coordinate table, with no LLM required for the parsing step
- Scores and ranks facilities across six signals weighted by care type and urgency
- Re-weights rankings in real time when Genie assesses the clinical urgency of a case
- Explains every recommendation with evidence snippets, source URL classifications, missing or suspicious evidence flags, and a Genie-generated summary
- Learns from planners via shortlists, notes, reviews, and manual score overrides that feed back into re-ranking
- Routes visually on an interactive India map using OSRM road-network routing, with a Dijkstra graph fallback
How we built it
Data pipeline
We fused three datasets into a single enriched table (v4.csv, 10,007 rows):
- Facilities: name, location, specialties, capabilities, equipment, and source URLs from web-scraped records
- Pincode: geographic mapping from pincode to district to state, covering all of India
- NFHS-5: 108 district-level health indicators including institutional birth rate, child stunting, anaemia prevalence, sanitation coverage, and health insurance penetration
Joining these required two-pass district name harmonisation. Pincode and NFHS use different spellings for the same district (101 mismatches across 698 districts). We applied difflib fuzzy matching within each state (cutoff $= 0.80$), then a 43-entry manual correction map for renamed districts such as Allahabad to Prayagraj and Gurgaon to Gurugram. Final NFHS match rate: $\mathbf{99.9\%}$ of districts, $\mathbf{94.2\%}$ of facilities.
Scoring pipeline
Each facility is scored across six signals, then weighted by care type:
$$S_{\text{raw}} = w_d \cdot S_d + w_c \cdot S_c + w_t \cdot S_t + w_e \cdot S_e + w_n \cdot S_n - w_u \cdot P_u$$
| Symbol | Signal |
|---|---|
| $S_d$ | Distance score (bucket table by care type) |
| $S_c$ | Disease match score (keyword tiers: strong / medium / weak) |
| $S_t$ | Baseline trust score from the v4 pipeline |
| $S_e$ | Evidence strength score (field-weighted snippet extraction) |
| $S_n$ | Local need score from NFHS district indicators |
| $P_u$ | Uncertainty penalty (Low: 5, Medium: 35, High: 70) |
Base weights differ by care type. For emergency care, distance carries $w_d = 0.35$; for specialist care, disease match and evidence dominate at $w_c = 0.30$ and $w_e = 0.25$.
Evidence safety caps prevent overconfident rankings: a facility with High uncertainty is soft-capped near 70, one with no evidence snippets near 55.
Urgency-aware quadratic distance re-weighting
The key insight behind our scoring design is that the importance of distance scales non-linearly with clinical urgency. A trauma patient cannot afford an hour-long drive; a chronic disease follow-up can tolerate one.
When Genie assesses a case and returns an urgency score $u \in [1, 10]$, we re-compute the distance weight with a quadratic formula:
$$w_{\text{distance}}(u) = \min!\left(0.88,\; \frac{u^2 + 2u + 13}{140}\right)$$
At $u = 2$ (routine), $w_{\text{distance}} \approx 0.15$. At $u = 9$ (severe), $w_{\text{distance}} \approx 0.80$. At $u = 10$, the weight is capped at $0.88$ to preserve a small contribution from clinical evidence. The remaining weight is distributed across disease match, trust, evidence strength, and local need proportionally. The result is that high-urgency searches rank the nearest capable facility first, even if a farther facility has stronger evidence.
Feedback re-ranking
Planner actions persist to SQLite and adjust scores for the same search scenario:
| Action | Score delta |
|---|---|
| Saved to shortlist | $+8$ |
| Accepted | $+5$ |
| Needs verification | $+2$ |
| Has notes | $+1$ |
| Rejected | $-30$ |
| Manual override | Sets score directly |
final_recommendation_score is never overwritten. Only feedback_adjusted_score changes, so the base evidence ranking is always auditable.
App stack
React 19 + Vite + Tailwind + react-leaflet
| JSON / HTTP
Express + Databricks AppKit (Lakebase + Genie + Server plugins)
| Lakebase Postgres (facilities, feedback state)
| Genie space (summarization + intent assessment)
| stdin/stdout JSON via child_process.spawn (local fallback)
Python bridge (facility_scoring_pipeline.py + persistence.py)
The scoring engine is implemented in both TypeScript (production, runs against Lakebase) and Python (local fallback via referral_cli.py). Genie is the default summarizer; a Llama 4 Maverick option is available via a runtime toggle.
Challenges we ran into
Evidence noise removal. Web-scraped capability lists contained duplicates, meta-sentences like "as listed on the website", and entries as short as two characters. We built a multi-pass filter combining deduplication (case-insensitive, order-preserving), length bounds, and pattern matching against known noise phrases. This removed $\sim 13\%$ of items without losing real clinical signals.
NaN serialisation across the Python-Node boundary. pandas and numpy NaN and Inf values are not valid JSON. Every numeric field had to pass through a recursive _safe_value() coercion before the subprocess wrote its response to stdout. Any single uncaught NaN caused silent JSON parse failures on the Node side.
Python stdout contract. The scoring pipeline emits human-readable progress via print() to stdout. We had to redirect all such output to stderr inside referral_cli.py, keeping stdout clean for the single JSON response. The Node bridge then reads only the last line of stdout to be defensive against any straggler output.
Urgency formula calibration. We needed the quadratic $w_{\text{distance}}(u)$ to hit specific anchor points: $\approx 0.15$ at $u = 2$ and $\approx 0.80$ at $u = 9$, with a cap below 1.0 so evidence always contributes. We derived the $(u^2 + 2u + 13)/140$ polynomial by solving a two-point system and verified it with unit tests covering all anchor values.
Accomplishments that we're proud of
- A scoring pipeline that is fully explainable: every candidate card shows a six-component breakdown, evidence snippets with source URLs, and a plain-language recommendation reason
- The urgency quadratic formula that dynamically re-weights distance based on how critical the case is, making the ranking behaviour clinically intuitive
- A feedback loop that actually changes rankings: planner decisions from past searches carry forward into re-ranking for the same scenario
- Dual-engine architecture: the same scoring logic runs in TypeScript against Lakebase in production and in Python locally, with a clean JSON contract between them
- Achieving $99.9\%$ district match rate across datasets with very different geographic naming conventions
What we learned
- Real healthcare data is messier than any benchmark. District names, pincode formats, and facility names each required separate normalisation strategies.
- Transparency matters more than raw accuracy in healthcare AI. Planners need to understand and trust a recommendation before acting on it, which means surfacing evidence, flagging uncertainty, and allowing overrides.
- NFHS-5 district indicators add meaningful signal. Facilities in high-unmet-need districts score higher for certain care types, naturally directing referrals where they have the most impact.
- The quadratic urgency formula is easy to reason about and easy to test. Simple polynomial forms with closed-form anchor points are easier to validate than learned weights.
What's next for CarePilot
- Broader city coverage: extend the location parser beyond the current 35-city table using Lakebase geocoding against the full facilities dataset
- Multilingual NL parsing: support Hindi and regional language queries via the Genie or Llama model layer
- Live facility data: a periodic re-crawl and re-score pipeline so evidence stays current
- Outcome feedback: record whether referred patients received care and feed real outcomes back into the trust score
- District-level gap maps: visualise underserved districts overlaid on NFHS indicators to surface referral deserts proactively
- Offline PWA: a lightweight progressive web app for frontline workers in low-connectivity areas
Built With
- aigateway
- databricks
- genie
- lakebase
- osrm
- particle
- python
- react
- sql
- typescript

Log in or sign up for Devpost to join the conversation.