
Inspiration
Prompt Opinion makes it possible for healthcare agents to assemble and collaborate through MCP, A2A, and FHIR context. But once many agents are available in a marketplace, a new hospital problem appears: who checks what those agents say before their output reaches a clinician or downstream workflow?
A medication agent may draft an unsafe recommendation. A prior authorization agent may cite missing evidence. A discharge agent may produce a handoff that sounds confident but is not grounded in the patient record.
CareOps Sentinel was built around a simple thesis:
Prompt Opinion lets healthcare agents assemble. CareOps Sentinel makes sure they assemble safely.
What it does
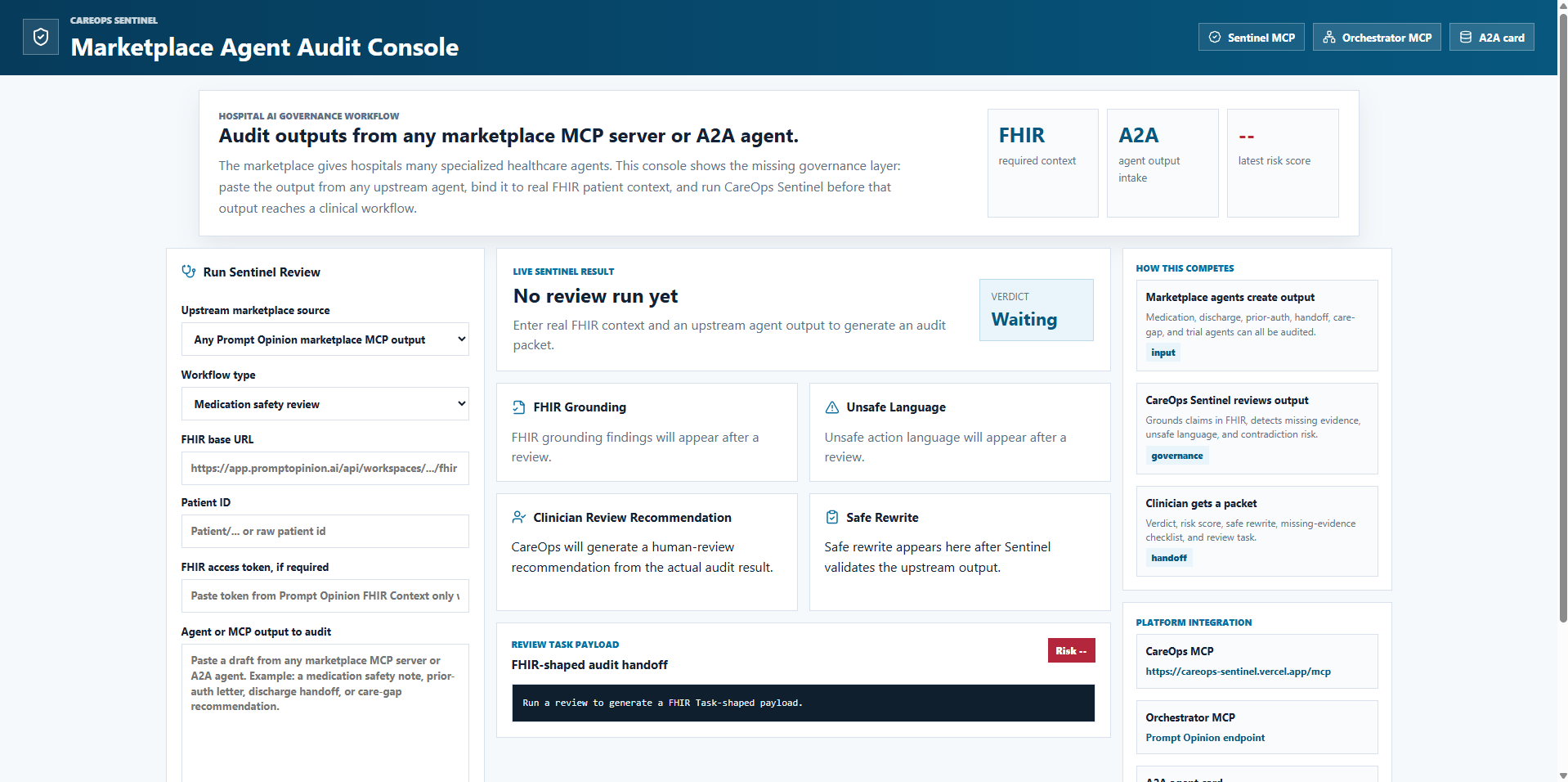
CareOps Sentinel audits outputs from healthcare agents and MCP servers before those outputs enter clinical workflows.
It takes:
- Active patient FHIR context
- An upstream agent or MCP output
- A workflow type such as medication safety, discharge review, prior authorization review, care gap review, or referral review
It returns:
- Safety verdict
- Risk score
- FHIR evidence grounding findings
- Missing evidence checklist
- Unsafe clinical-action language findings
- Contradiction findings
- Safe rewrite
- Clinician-review recommendation
- FHIR Task-shaped review payload
CareOps Sentinel is not a diagnosis engine, treatment recommender, or autonomous approval system. It is a human-in-the-loop governance layer for healthcare agents.
How we built it
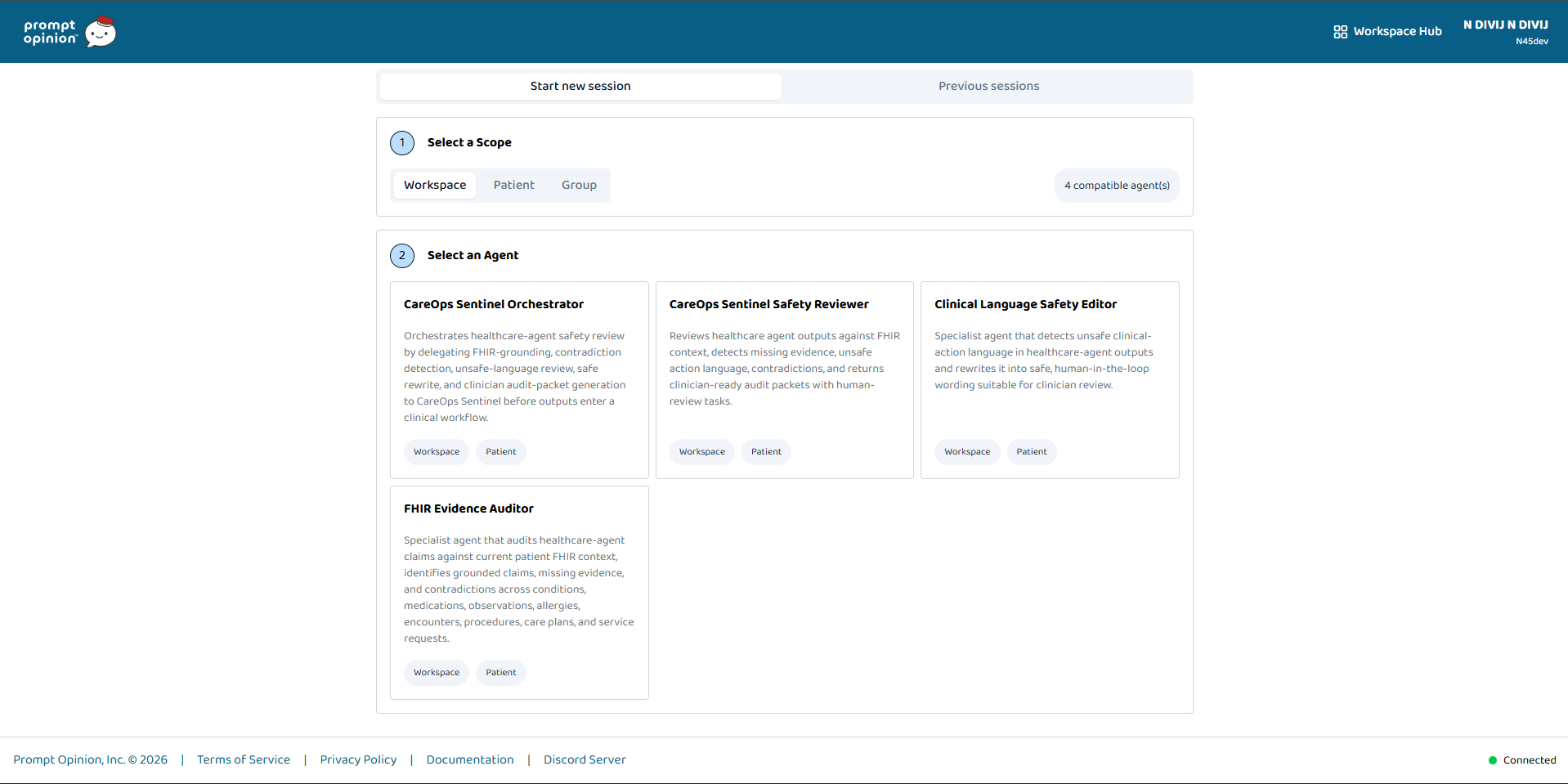
We built CareOps Sentinel as an xMCP-powered TypeScript server deployed on Vercel and integrated with Prompt Opinion.
The MCP server exposes 14 tools, including:
- validate_patient_agent_output
- check_fhir_grounding
- check_context_contradictions
- rewrite_unsafe_language
- generate_audit_packet
- create_review_task_payload
The system supports Prompt Opinion’s FHIR context extension. When invoked inside Prompt Opinion, the selected patient context is passed through FHIR headers. CareOps Sentinel fetches the patient context, normalizes the FHIR Bundle into structured evidence references, and validates the upstream agent output.
We also built a Next.js hospital-facing audit console. The console demonstrates how a care team could paste output from any marketplace MCP server or A2A agent, bind it to real FHIR context, and generate a Sentinel audit packet.
The safety engine is deterministic and tested with Vitest. It checks FHIR grounding, missing evidence, unsafe action language, agent contradictions, FHIR-context contradictions, and human-review requirements.
Challenges we ran into
The biggest challenge was avoiding a fake demo.
It would have been easy to hardcode a patient, mock the FHIR response, and make the output look good. Instead, we made the system fail closed when FHIR context is missing. The production path requires Prompt Opinion FHIR context, explicit FHIR input, or authorized sandbox configuration.
Another challenge was positioning. The marketplace already has many strong healthcare MCP servers for medication safety, prior authorization, care gaps, handoffs, and FHIR access. We realized CareOps Sentinel should not compete as another specialist clinical tool. Its value is reviewing the outputs of those tools.
We also had to balance safety and usefulness. The system must identify unsafe content without producing medical advice itself. That shaped the product boundary: audit, rewrite safely, recommend clinician review, and generate a review task, but never diagnose, prescribe, approve, or automate clinical action.
Accomplishments that we're proud of
We are proud that CareOps Sentinel works as both a Prompt Opinion-integrated MCP server and a product-facing audit console.
We successfully:
- Deployed a working MCP endpoint on Vercel
- Registered it with Prompt Opinion
- Enabled Prompt Opinion FHIR context support
- Built an A2A/orchestrator workflow
- Validated live Prompt Opinion patient context
- Generated structured safety verdicts and audit packets
- Built a frontend console for hospital-facing review
- Added deterministic tests for the safety engine, FHIR normalization, and evidence matching
Most importantly, the product has a clear role in a multi-agent healthcare ecosystem: it is the safety auditor for other agents.
What we learned
We learned that interoperability creates a second-order safety problem.
MCP and A2A make it easier for agents to work together, but healthcare systems also need a way to govern the outputs of those agents. A tool can be useful in isolation but risky when its output is composed into another workflow without review.
We also learned that FHIR grounding needs to be explicit and explainable. It is not enough to say an output is “safe” or “unsafe.” A clinician needs to see which claims were grounded, which claims were unsupported, and why review is required.
Finally, we learned that human-in-the-loop design is not a limitation. In healthcare AI, it is the product.
What's next for CareOps Sentinel
Next, we want to expand CareOps Sentinel from a review tool into a full agent-governance layer for healthcare organizations.
Planned next steps:
- Direct intake from selected Prompt Opinion marketplace agents
- Stronger multi-agent contradiction detection across several agent outputs
- Richer FHIR Task and CommunicationRequest handoff payloads
- Audit history and reviewer workflow in the console
- Configurable hospital safety policies by workflow type
- Deeper evidence matching for medications, labs, allergies, procedures, and care plans
- Role-based review queues for clinicians, pharmacists, care managers, and utilization teams
The long-term goal is to make CareOps Sentinel the safety checkpoint every healthcare agent passes through before its output reaches a clinical workflow.
Built With
- fhir-r4
- model-context-protocol
- next.js
- prompt-opinion
- typescript
- vercel
- vitest
- xmcp
- zod

Log in or sign up for Devpost to join the conversation.