-
-
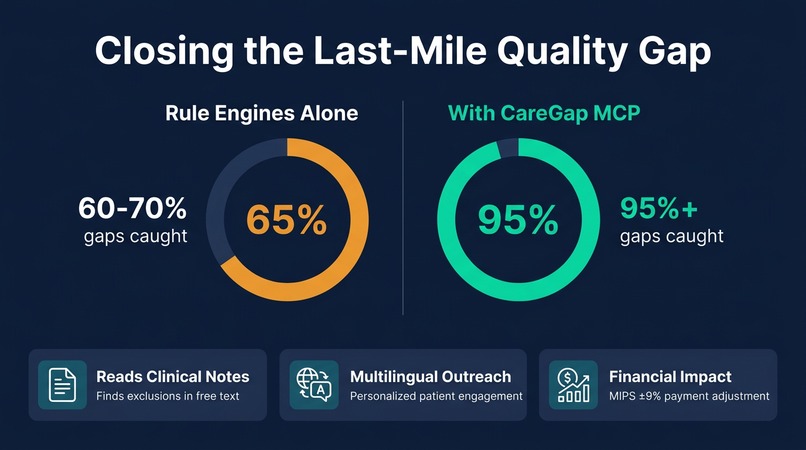
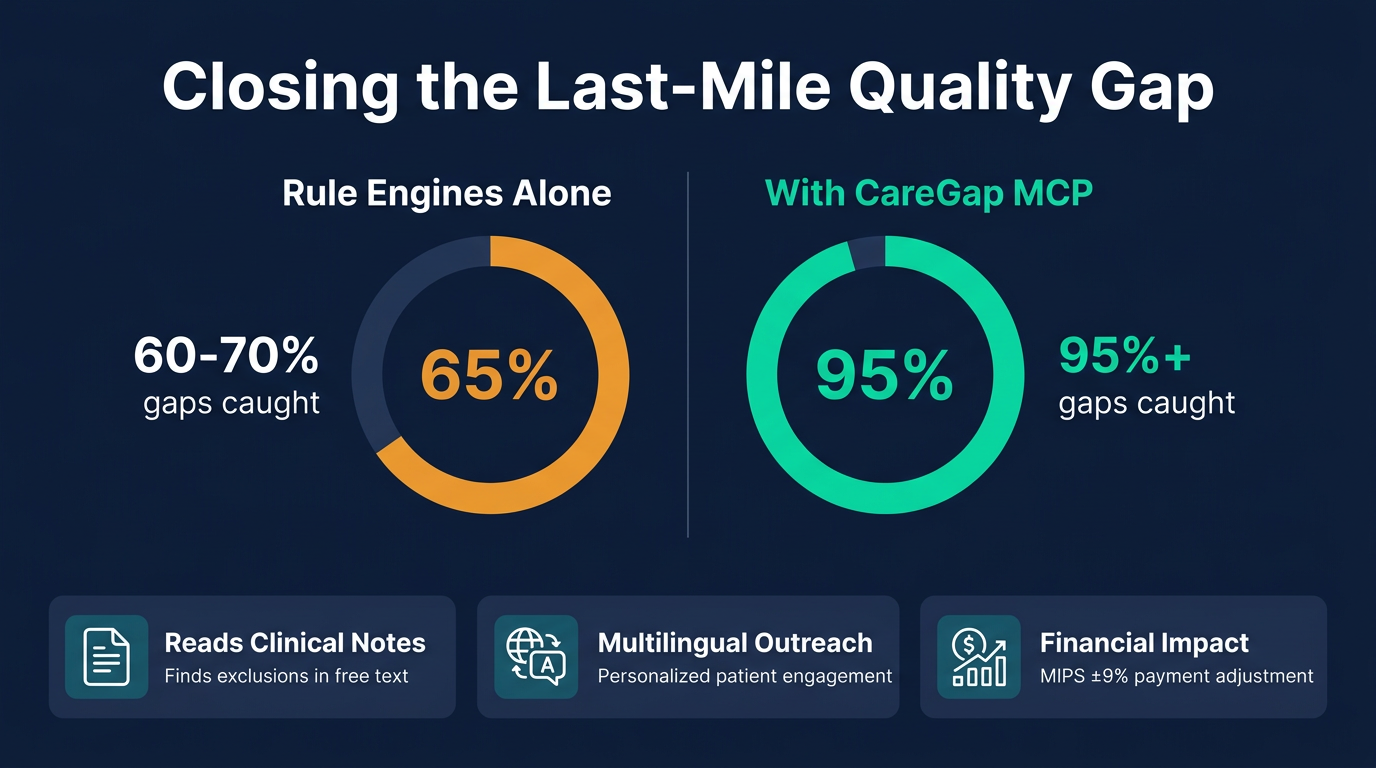
Rule engines catch 60-70% of care gaps. CareGap MCP closes the rest by reading clinical notes, drafting outreach, and ranking priorities.
-
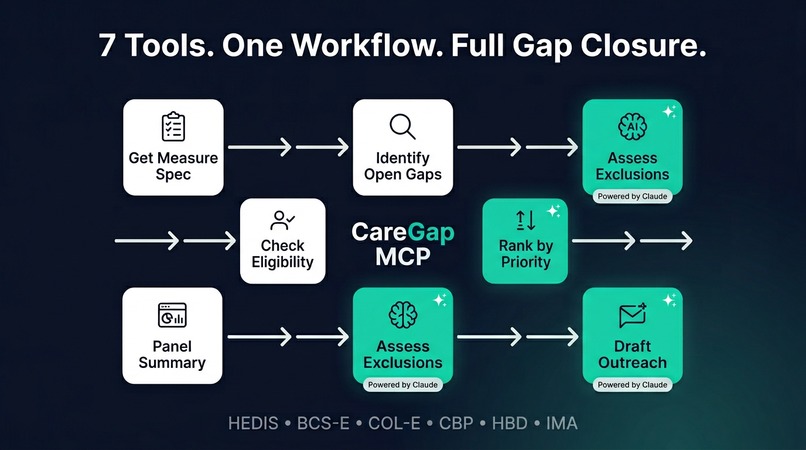
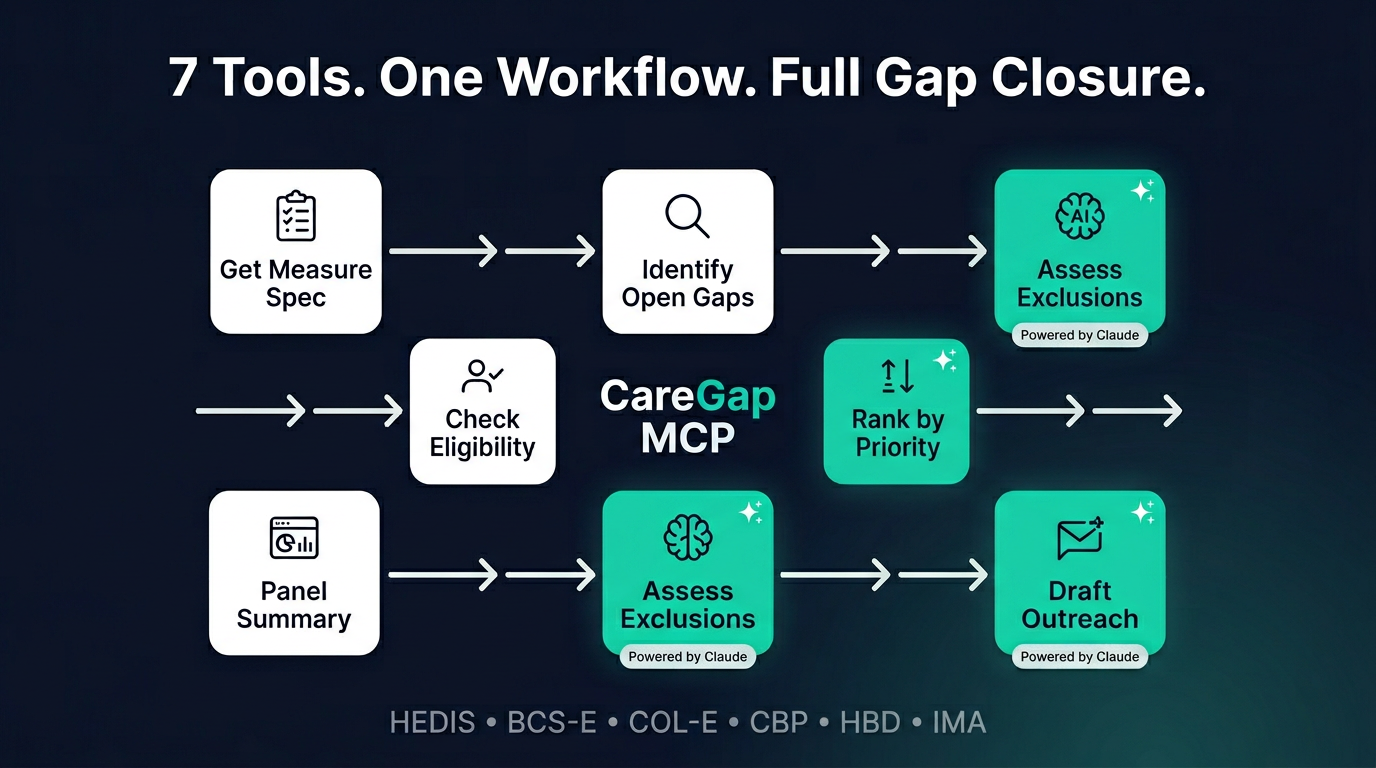
Seven MCP tools cover the full gap-closure workflow — from measure specs to AI-powered exclusion analysis and multilingual outreach.
-

Maria G. has 4 HEDIS gaps. Claude reads her clinical notes, finds an outside mammogram, and reclassifies BCS-E from OPEN to EXCLUDED.
-
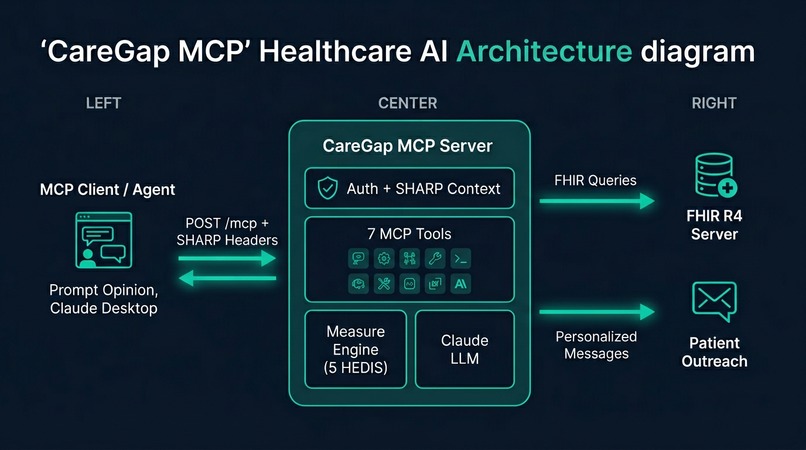
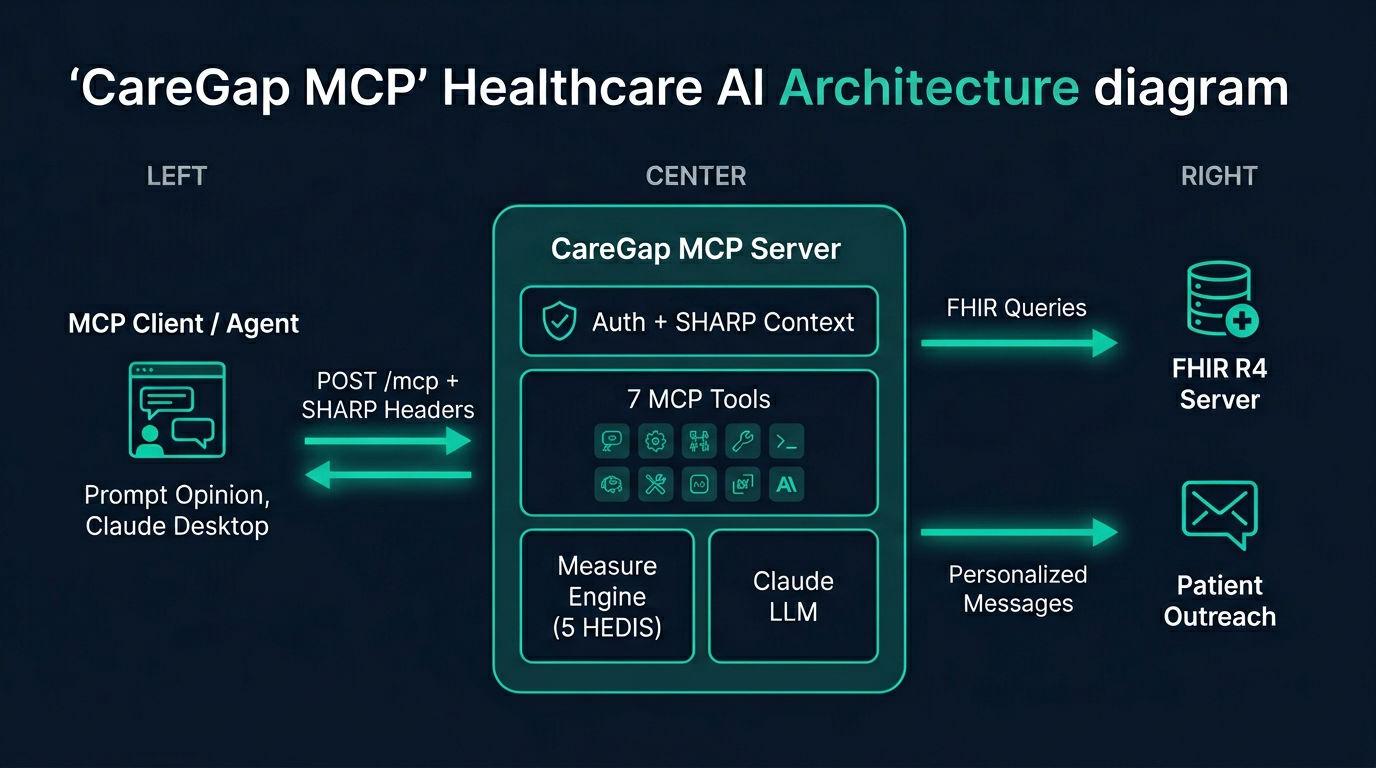
CareGap MCP architecture: MCP clients send SHARP headers, the server evaluates HEDIS measures via FHIR and uses Claude for AI tools.

Inspiration
Quality measures like HEDIS and MIPS drive billions in value-based payments across U.S. healthcare. MIPS alone adjusts ±9% of Medicare Part B reimbursement, affecting roughly $100B in annual spending. A single-star improvement in Medicare Advantage Star Ratings can mean $50M+ annually for a large health plan. These aren't abstract numbers — they determine whether care organizations can invest in better patient outcomes or face financial penalties.
Yet traditional rule engines only catch 60–70% of closable gaps. The remaining 30–40% are locked away in unstructured clinical notes, outside-facility records, and patient-reported data that structured queries simply cannot reach. A mammogram completed at an imaging center across town, documented only in a free-text note. A hospice enrollment buried in a social work assessment. A patient refusal noted in a visit summary. These are the gaps that cost health systems millions and leave patients without the follow-up they need.
We asked: what if an AI agent could read those notes, find the missing evidence, and help close the gap — not as a standalone tool, but as a composable capability any healthcare AI agent can pick up?
What It Does
CareGap MCP is a SHARP-on-MCP compliant server that gives any healthcare AI agent seven clinical tools covering the full gap-closure workflow:
- Measure specification lookup — retrieve the full HEDIS/CMS spec for any supported measure, including denominator criteria, numerator requirements, exclusion rules, and value set OIDs, giving the agent full clinical context to reason about gaps
- Identify open gaps — evaluate a patient against 5 HEDIS measures (BCS-E, COL-E, CBP, HBD, IMA) in seconds, returning open/closed/excluded/not_eligible status with evidence citations from the patient's FHIR record
- AI-powered exclusion analysis — Claude reads base64-decoded clinical notes and DocumentReferences to find exclusions rule engines structurally cannot detect: outside-facility screenings, hospice enrollment notes, bilateral mastectomy documentation, patient refusals, and contraindications — each returned as a structured finding with the exact text snippet and a confidence score
- Eligibility breakdown — detailed criterion-by-criterion analysis of why a patient does or does not qualify for a specific measure (age, sex, coverage, conditions)
- Personalized outreach — generate multilingual, literacy-appropriate, channel-specific messages (SMS, email, portal, letter) to help patients close real gaps, with tone and reading level controls
- Priority ranking — AI ranks a patient's open gaps by clinical urgency, time-to-close, engagement likelihood, and MIPS financial weight
- Panel summary — program director view aggregating gap counts across the entire patient panel, sorted by financial impact (MIPS weight x open gap count), showing exactly where to focus quality improvement efforts
How We Built It
We built a TypeScript MCP server using the official @modelcontextprotocol/sdk with Express 5 and Streamable HTTP transport. The architecture has three distinct layers:
- SHARP middleware — enforces FHIR context headers (
X-FHIR-Server-URL,X-FHIR-Access-Token,X-Patient-ID) in production mode with an HTTP 403 guard, plus optional API key authentication via Bearer tokens - Measure engine — five HEDIS evaluators implementing denominator/numerator/exclusion logic against FHIR R4 resources (Patient, Condition, Observation, Procedure, Immunization, Coverage, DocumentReference), backed by either a live FHIR client with SSRF protection or bundled Synthea fixture data
- LLM layer — Anthropic Claude for clinical note analysis, outreach drafting, and gap prioritization, with full PHI redaction before any data reaches the model and a
DRY_RUNmode that returns deterministic fixtures for zero-dependency demos
We validated with 77 automated tests (Vitest) covering SHARP conformance, all five measure engines, SSRF protection, PHI redaction patterns, and end-to-end tool invocations. Four hand-crafted Synthea-style FHIR patient bundles ship with the server, each designed to exercise specific clinical scenarios — multilingual outreach, pediatric immunization logic, pregnancy exclusions, and unstructured note analysis.
Challenges We Ran Into
- Faithful HEDIS logic: HEDIS specifications span 500+ pages. Translating them into testable evaluators required building a clean measure spec/evaluator abstraction that balances clinical accuracy with the realities of synthetic data. We marked areas needing deeper clinical review with
TODO(spec-verify)annotations. - Per-request MCP servers: The SHARP-on-MCP pattern creates a fresh
McpServerinstance per HTTP request to bind FHIR context from headers. This was counterintuitive but necessary for platform compatibility. Getting resource cleanup right (closing transport and server on response end) required careful lifecycle management. - LLM response parsing: Claude occasionally wraps JSON responses in markdown code fences. We added a
stripMarkdownFencespost-processor after discovering this in live testing — a small detail that would have broken every LLM tool in production. - DRY_RUN without shortcuts: We wanted demo mode to exercise the full tool pipeline, not just return canned responses. The dry-run layer sits at the LLM boundary, so the entire measure engine, FHIR data loading, prompt construction, and response parsing still execute — only the actual API call is stubbed.
Accomplishments That We're Proud Of
- Real Claude exclusion finding: In live testing, the AI correctly identified a hospice enrollment from a base64-encoded clinical note at 0.95 confidence — exactly the kind of evidence a rule engine cannot reach
- 114-character Spanish SMS: The outreach tool generated a grade 4-5 reading level SMS in Spanish that fits within carrier character limits, respecting the patient's language preference and the channel's constraints simultaneously
- Clinical priority ranking that works: The AI correctly prioritizes active chronic disease management (uncontrolled HbA1c, hypertension) over preventive screening, matching clinical intuition
- Zero-setup demo:
npm install && npm run devgives you a fully functional server with four synthetic patients, fixture-mode data, and dry-run LLM responses — no API keys, no FHIR server, no configuration needed - 77 automated tests covering the full stack from SHARP header enforcement to measure evaluation to end-to-end tool invocations
What We Learned
- SHARP-on-MCP fills a real gap: Propagating FHIR context via HTTP headers is simple, composable, and solves the credential-bridging problem elegantly. It's the SMART-on-FHIR equivalent for AI agents.
- LLM + rules > LLM alone: The hybrid approach — structured FHIR evaluation first, AI for the ambiguous remainder — is more trustworthy and auditable than pure LLM reasoning. The rule engine provides the guardrails; the LLM handles the nuance.
- MCP is a natural fit for CDS: The tool abstraction maps cleanly to clinical decision support workflows. An agent that can call
identify_open_measure_gapsand thendraft_patient_outreachis composing a real care management workflow, not just answering questions. - PHI redaction must be a first-class concern: It cannot be bolted on after the fact. Every log line, every LLM prompt, every error message needs to pass through redaction by default.
What's Next for CareGap MCP
- More measures — HEDIS defines 90+ measures; expanding coverage to the most impactful ones (diabetes eye exams, depression screening, medication adherence)
- Real-time FHIR subscriptions — continuous gap monitoring instead of point-in-time evaluation
- Scheduling integration — one-click appointment booking directly from outreach messages
- Fine-tuned models — specialized models for specific exclusion categories to improve accuracy and reduce cost
- Multi-tenant deployment — organization-level measure configurations and custom exclusion rules
Built With
TypeScript, Node.js, Express 5, MCP SDK, Streamable HTTP, FHIR R4, Anthropic Claude, Zod, Pino, Vitest, Docker, Fly.io
Built With
- anthropic-claude-api
- docker
- express.js
- fhir-r4
- fly
- mcp-sdk
- node.js
- pino
- typescript
- vitest
- zod

Log in or sign up for Devpost to join the conversation.