-
-
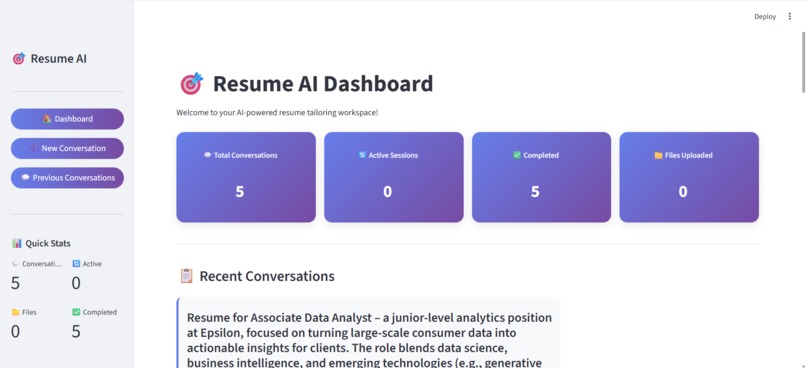
Dashboard
-
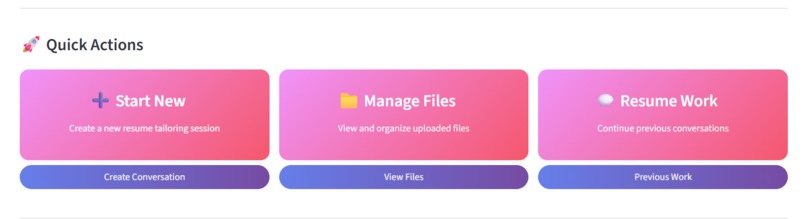
Quick Actions
-
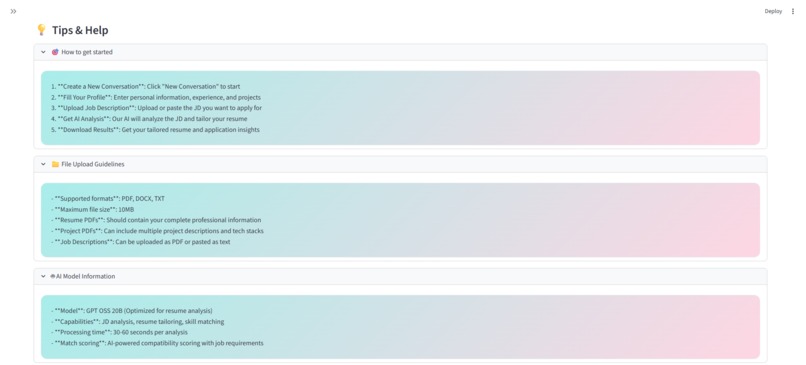
Tips and Help
-
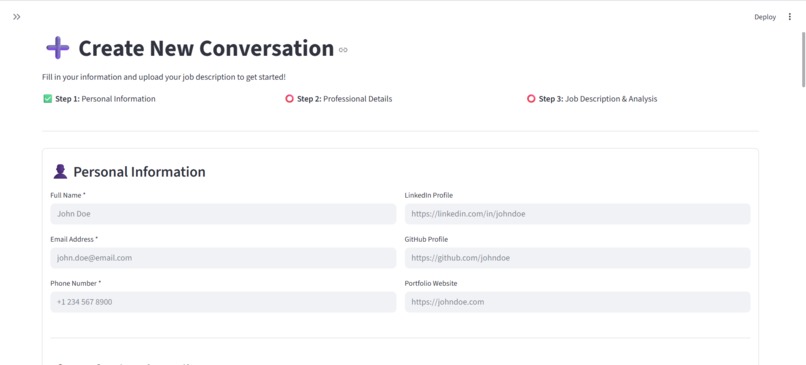
New Conversation
-
Resume and JD uploads
-
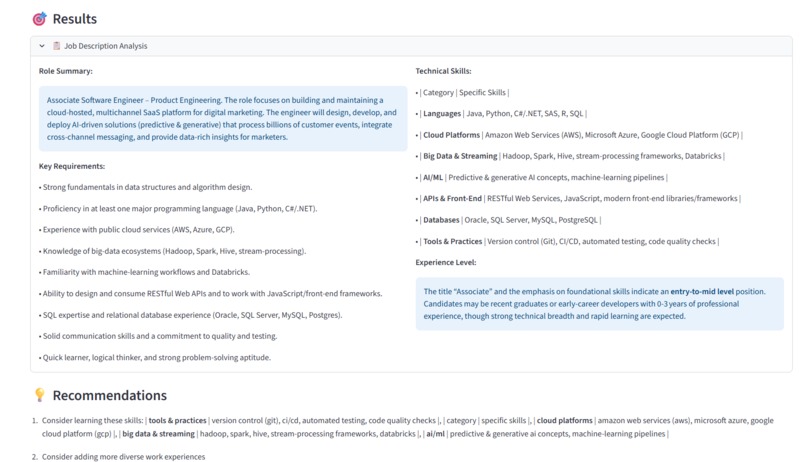
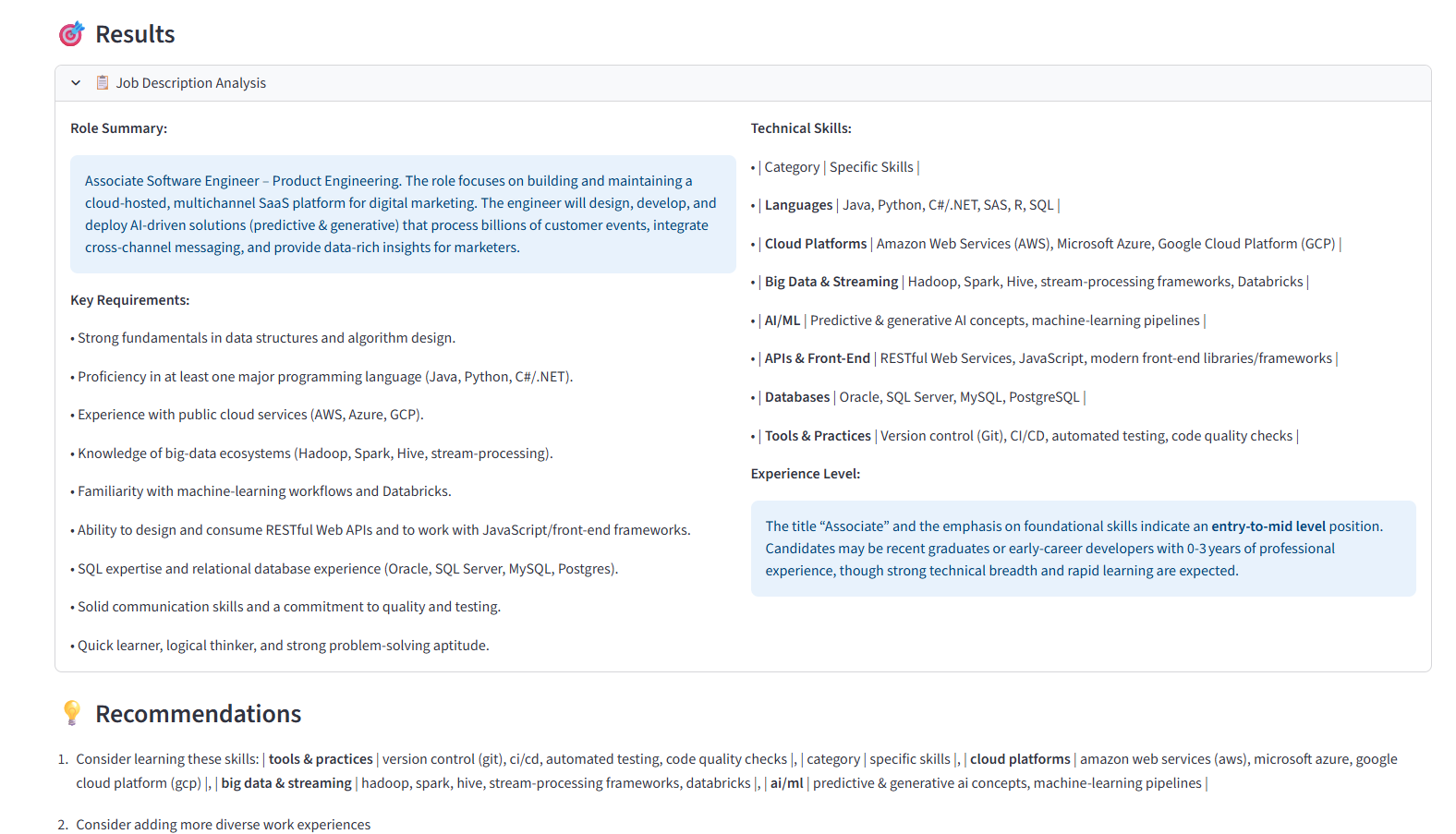
JD summary and Recommendations
-
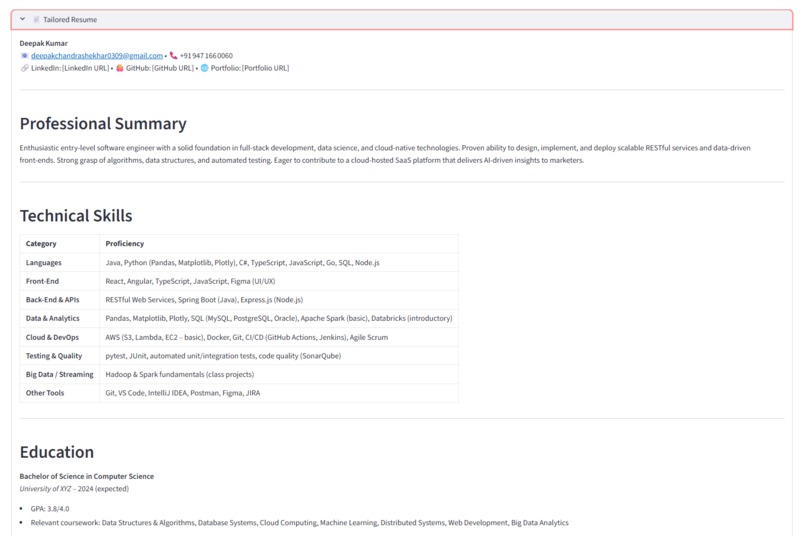
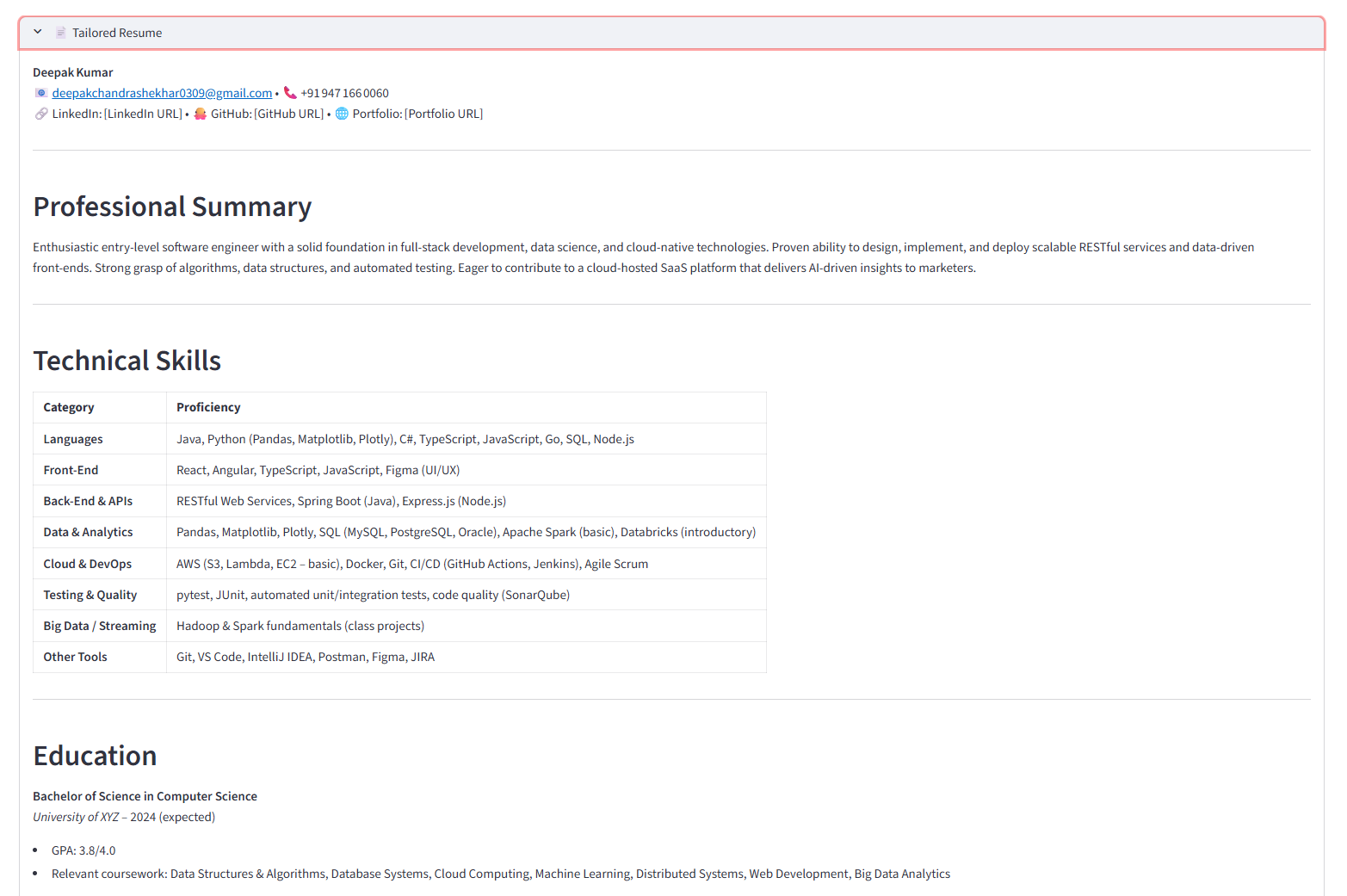
Tailored Resume For JD - part 1
-
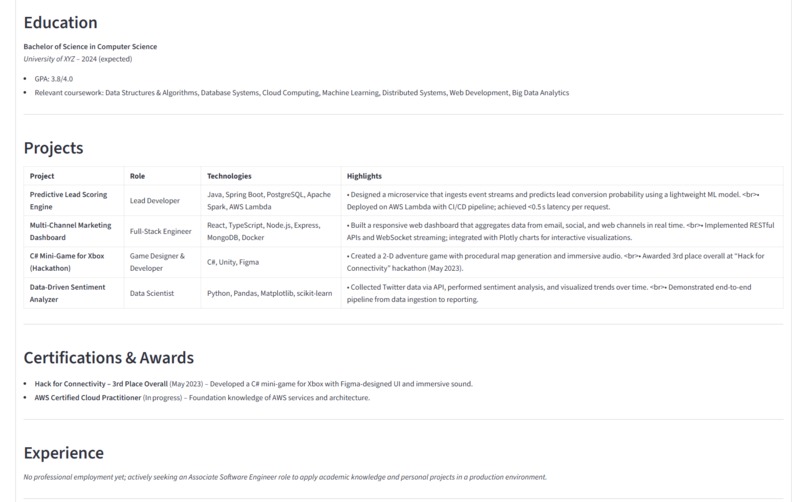
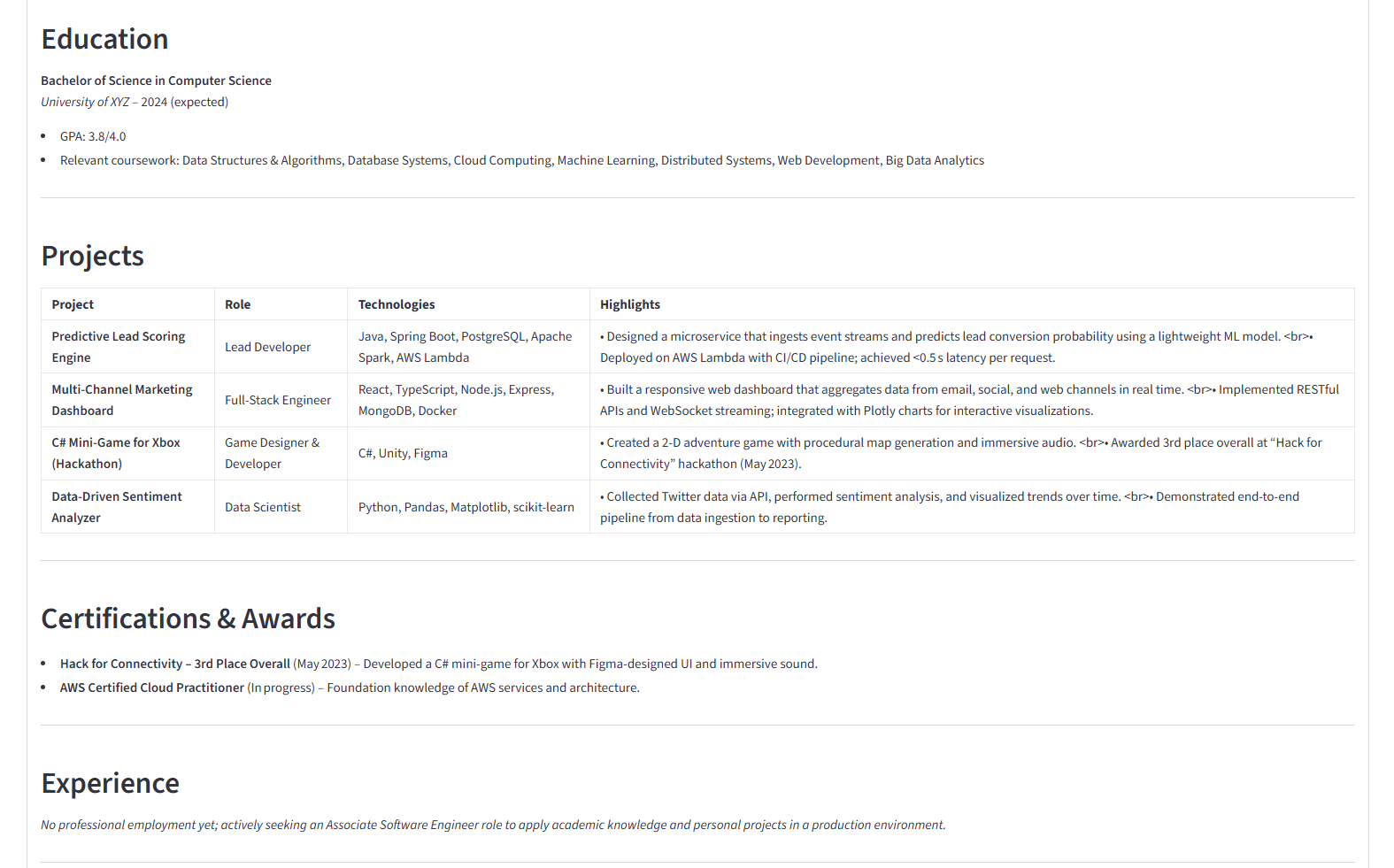
Tailored Resume For JD - part 2
-
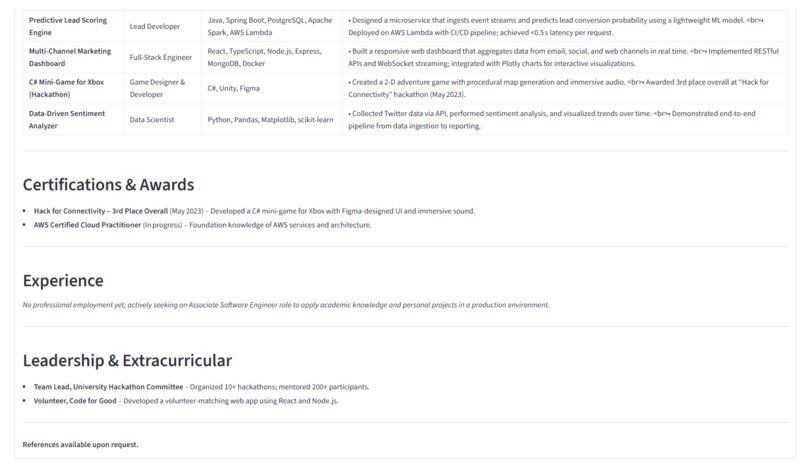
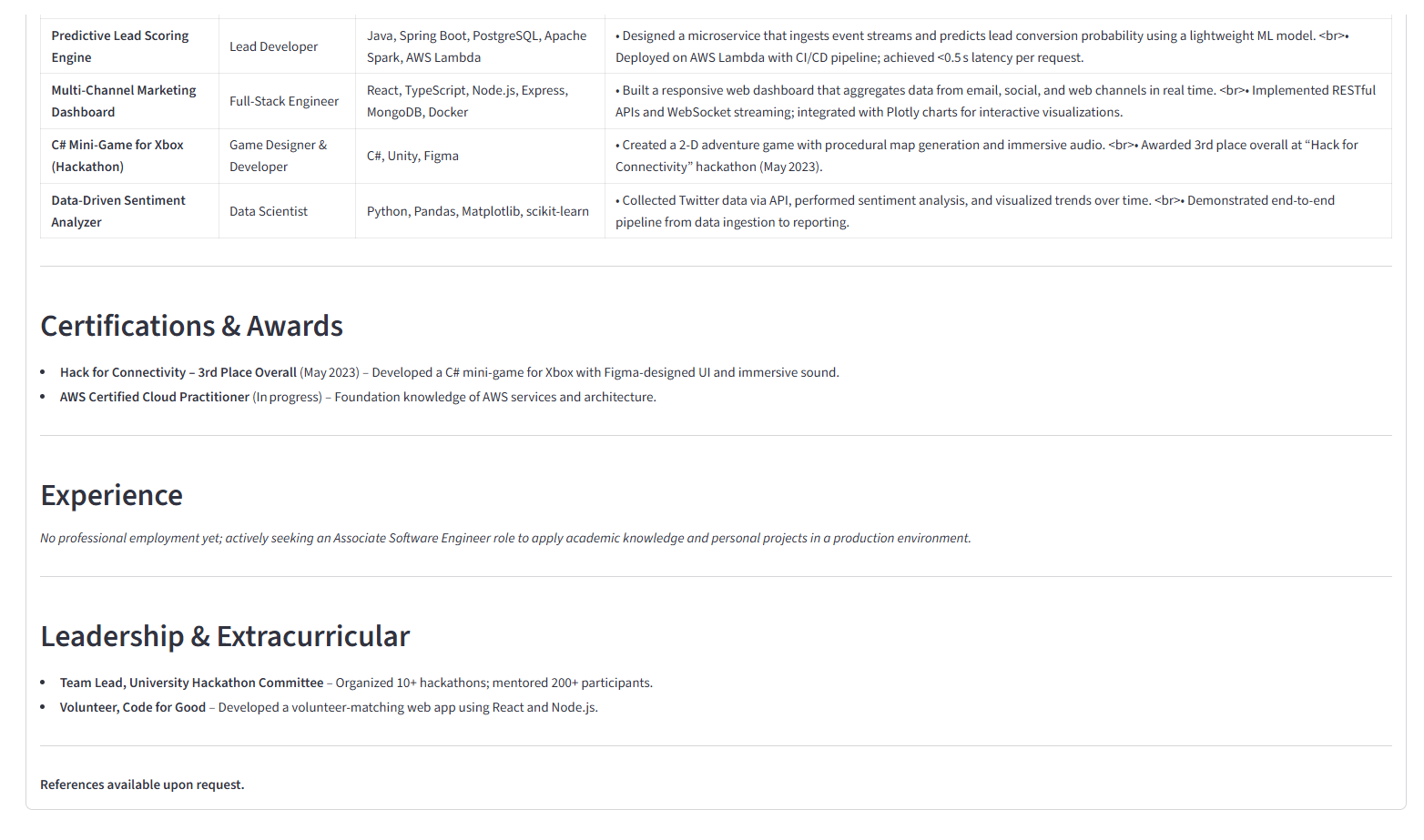
Tailored Resume For JD - part 3
-
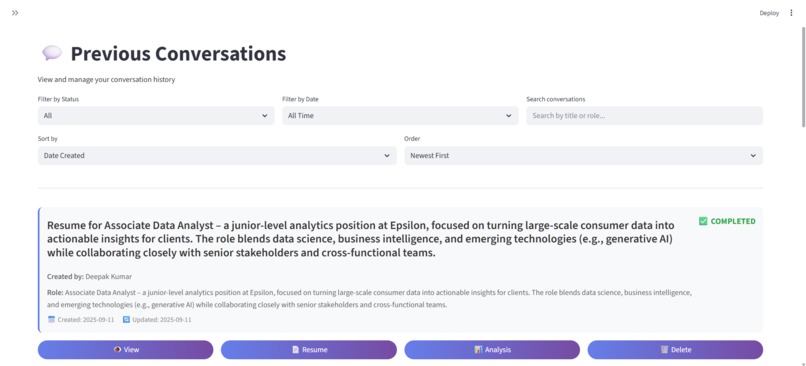
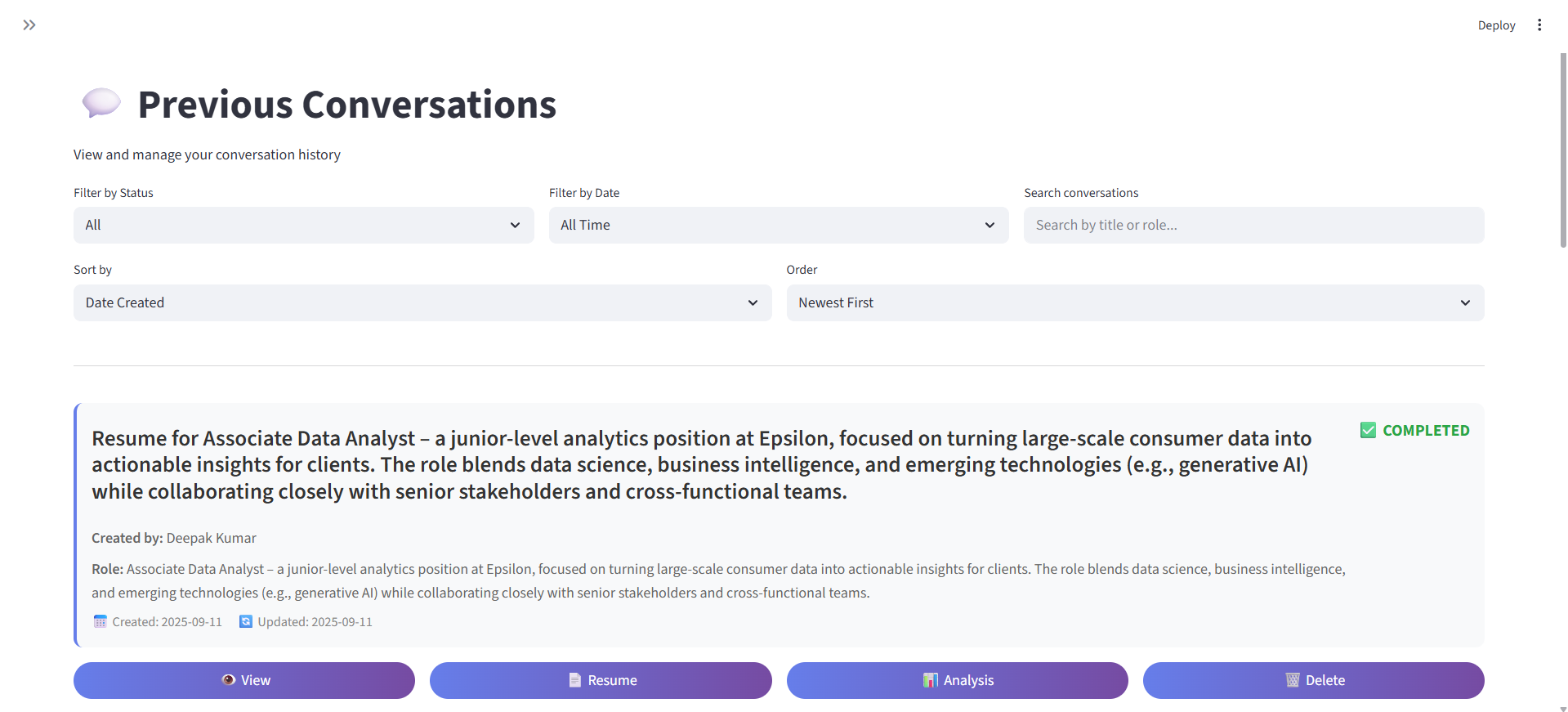
Previous Conversations
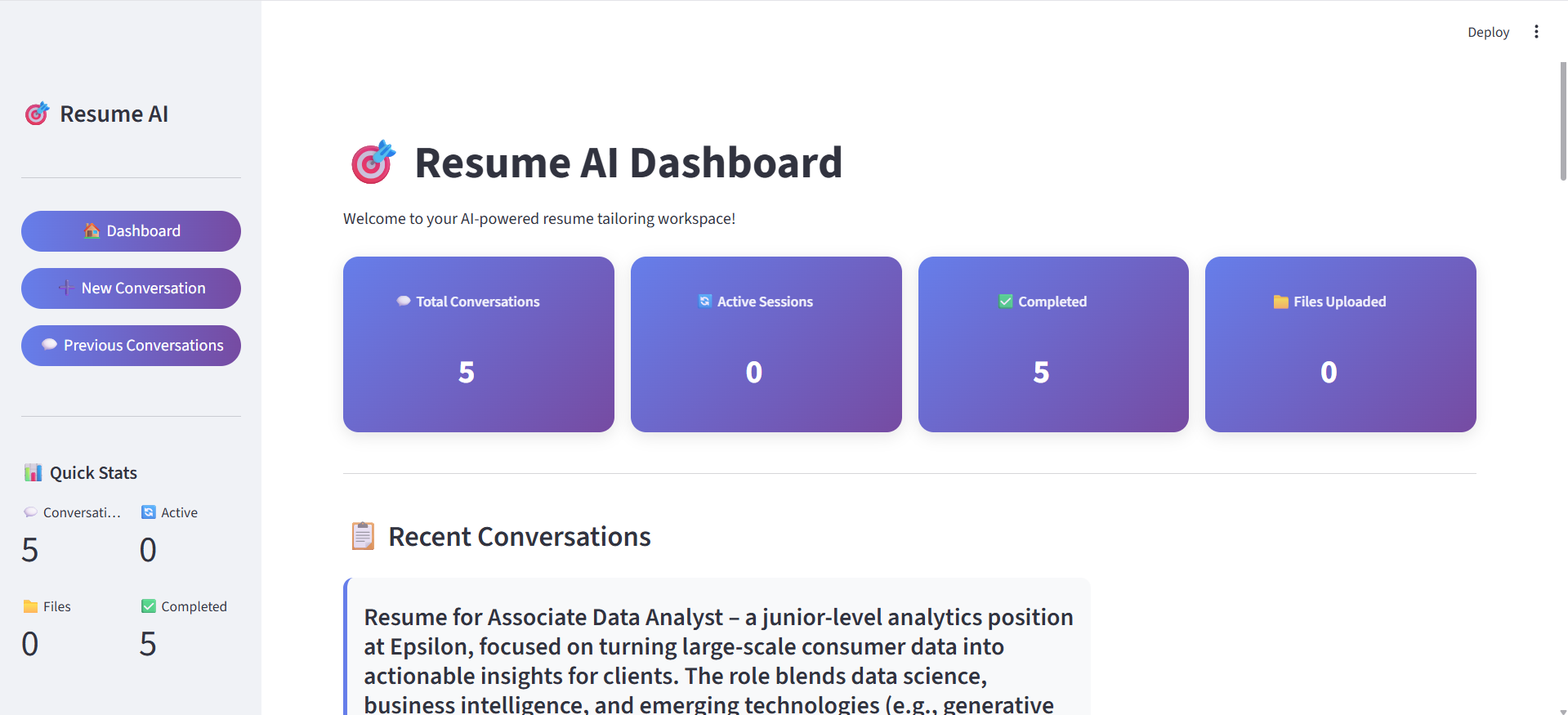
Resume AI
Inspiration
The inspiration for Resume AI came from a personal and universal pain point in the job search: the tedious, manual process of tailoring a resume for every single job application. I realized that a significant amount of time was being spent just rephrasing duties and highlighting different skills to match keywords in a job description. This repetitive work was a major bottleneck that limited the number of quality applications one could submit. I wanted to build a tool that could automate this entire process, leveraging AI to give job seekers a powerful advantage and help them land interviews more efficiently.
What it does
Resume AI is an intelligent web application that automates resume optimization. A user provides their existing resume (as a PDF) or can fill out the details manually and a job description for a role they're interested in. The application then:
- Parses and Extracts: Intelligently extracts structured data from the resume, including contact information, skills, work experience, and education, even detecting hyperlinks.
- Analyzes the Job: Uses an AI model to analyze the job description, identifying the key requirements, technical skills, and responsibilities the employer is looking for.
- Tailors the Resume: Generates a newly tailored resume that emphasizes the user's most relevant qualifications and rephrases content to align perfectly with the job description.
- Provides Insights: Offers a match score and highlights areas for improvement, helping the user understand their fit for the role.
The result is a perfectly customized resume, ready for submission, created in a fraction of the time it would take manually.
How we built it
The application was built using a full-stack Python approach, with a focus on modularity and a robust backend.
- Frontend: Built with Streamlit, allowing rapid development of an interactive and responsive web application. Plotly was used for data visualizations on the dashboard.
- Backend & AI: Powered by Python, integrating AI capabilities via the OpenRouter API with carefully engineered prompts for job analysis and resume generation.
- Data Processing: Used PyMuPDF (fitz) for PDF processing, which outperformed alternatives in accurately extracting text, structured data, and hyperlinks.
- Database: MongoDB (via pymongo) was integrated for persistence, with a fallback to local JSON storage to ensure functionality even without database access.
How GPT-OSS-20B is used
The GPT-OSS-20B model plays a central role in Resume AI, powering the intelligence behind resume tailoring and job analysis:
- Job Analysis: The model processes raw job descriptions to extract and summarize the role’s responsibilities, technical requirements, and soft skills.
- Resume Tailoring: Using carefully designed prompts, GPT-OSS-20B rewrites and restructures resume content to align with the identified keywords and expectations in the job description.
- Skill Gap Detection: By comparing the candidate’s profile against the parsed job requirements, the model highlights missing or underrepresented skills and suggests improvements.
- Language Quality: The model ensures that the generated resume content is polished, professional, and ATS-friendly, improving readability while maintaining accuracy.
This integration makes Resume AI much more than a keyword matcher—it becomes a true AI-powered assistant that understands both job postings and candidate profiles at a semantic level.
Challenges we ran into
Throughout development, we faced several technical challenges:
- Streamlit's Execution Model: Resolved errors like
StreamlitAPIExceptionandStreamlitDuplicateElementIdby learning the execution flow and assigning unique keys to widgets. - Accurate PDF Parsing: Initial methods failed, leading us to adopt PyMuPDF and build sophisticated parsing logic for varied resume formats.
- State Management: Solved issues like
UnboundLocalErrorby restructuring data loading logic for both database and local file scenarios. - Dependency Management: Learned the importance of maintaining
requirements.txtto prevent issues likeModuleNotFoundError.
Accomplishments that we're proud of
Key achievements include:
- Intelligent PDF Processor: Accurately parsing resumes, extracting structured data, and preserving hyperlinks.
- Robust Fallback System: Seamlessly working with or without a database connection.
- Effective AI Prompt Engineering: Designing prompts that consistently generate high-quality resume content.
- Polished User Experience: Built an intuitive Streamlit interface despite the complexity behind the scenes.
What we learned
This project provided immense learning opportunities in:
- Full-Stack Development with Python: Connecting Streamlit (frontend), backend logic, and MongoDB database.
- Layered Architecture: Abstracting persistence into a
SessionManagerto decouple UI from storage and enable fallback. - Advanced Data Extraction: Structured data extraction from unstructured PDFs.
- Iterative Problem Solving: Turning every bug and error into a chance to refactor and improve.
What's next for Resume AI
Future plans include:
- Cover Letter Generation: AI-powered tailored cover letters based on resume and job description.
- Application Tracker: Dashboard for tracking job applications, statuses, and reminders.
- AI-Powered Interview Prep: Generate potential interview questions with answering tips.
- Enhanced Analytics: Provide insights into missing skills and suggest professional development areas.


Log in or sign up for Devpost to join the conversation.