Inspiration
India has over 10,000 registered healthcare facilities — but knowing which ones to trust, and where people need them most, is nearly impossible. District-level health burden data from NFHS-5 has never been joined to the facility supply side in a single interactive tool. Health planners, NGO workers, and clinicians are making referral and investment decisions blind.
We also realized that for millions of patients in India, a dashboard isn't the right interface — they need to talk to something, in their own language, and get a direct answer. That's how Aayu was born.
The "delta" in CareDelta is the gap between where care exists and where it's needed. Making that gap visible — and actionable — is the entire mission.
What it does
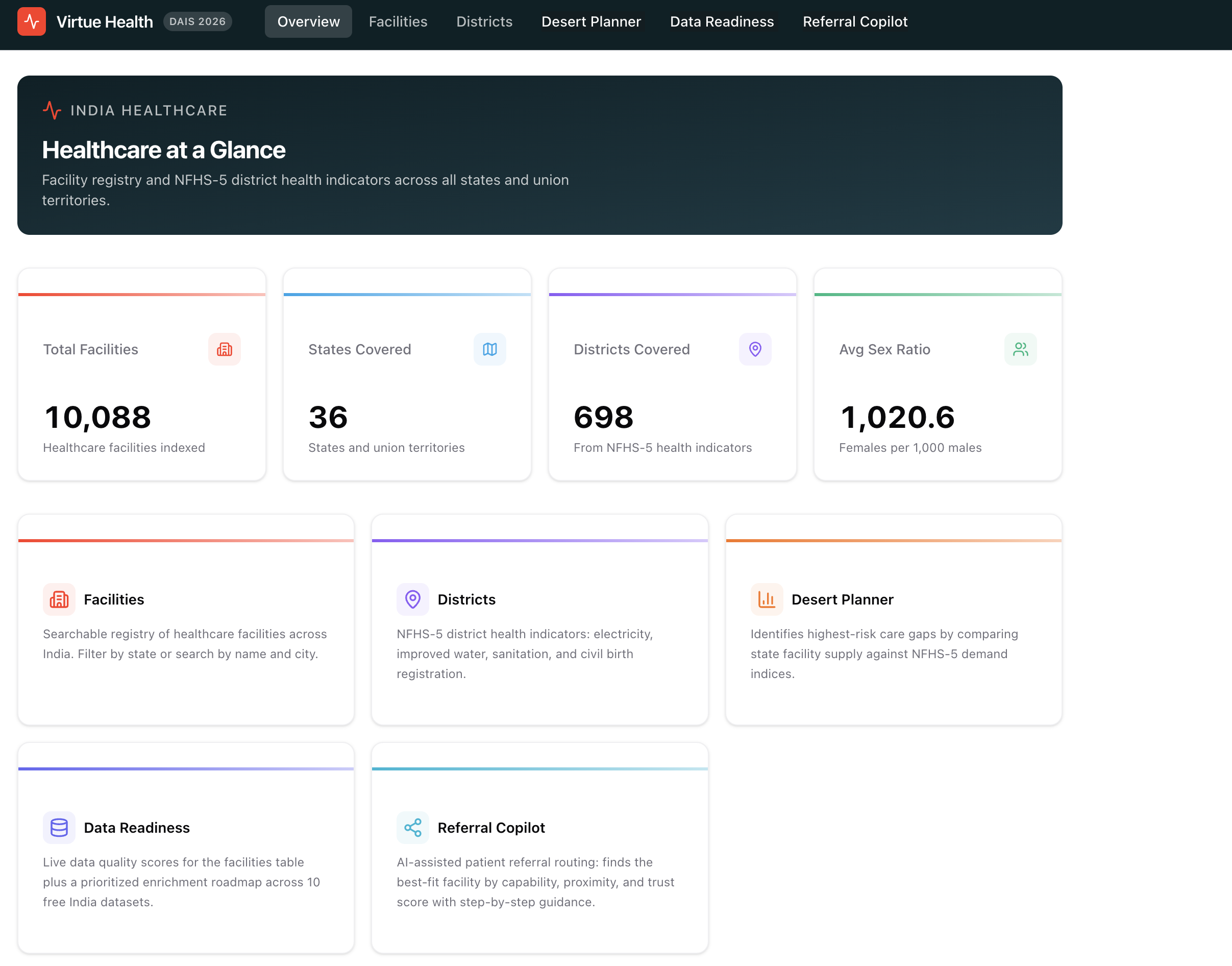
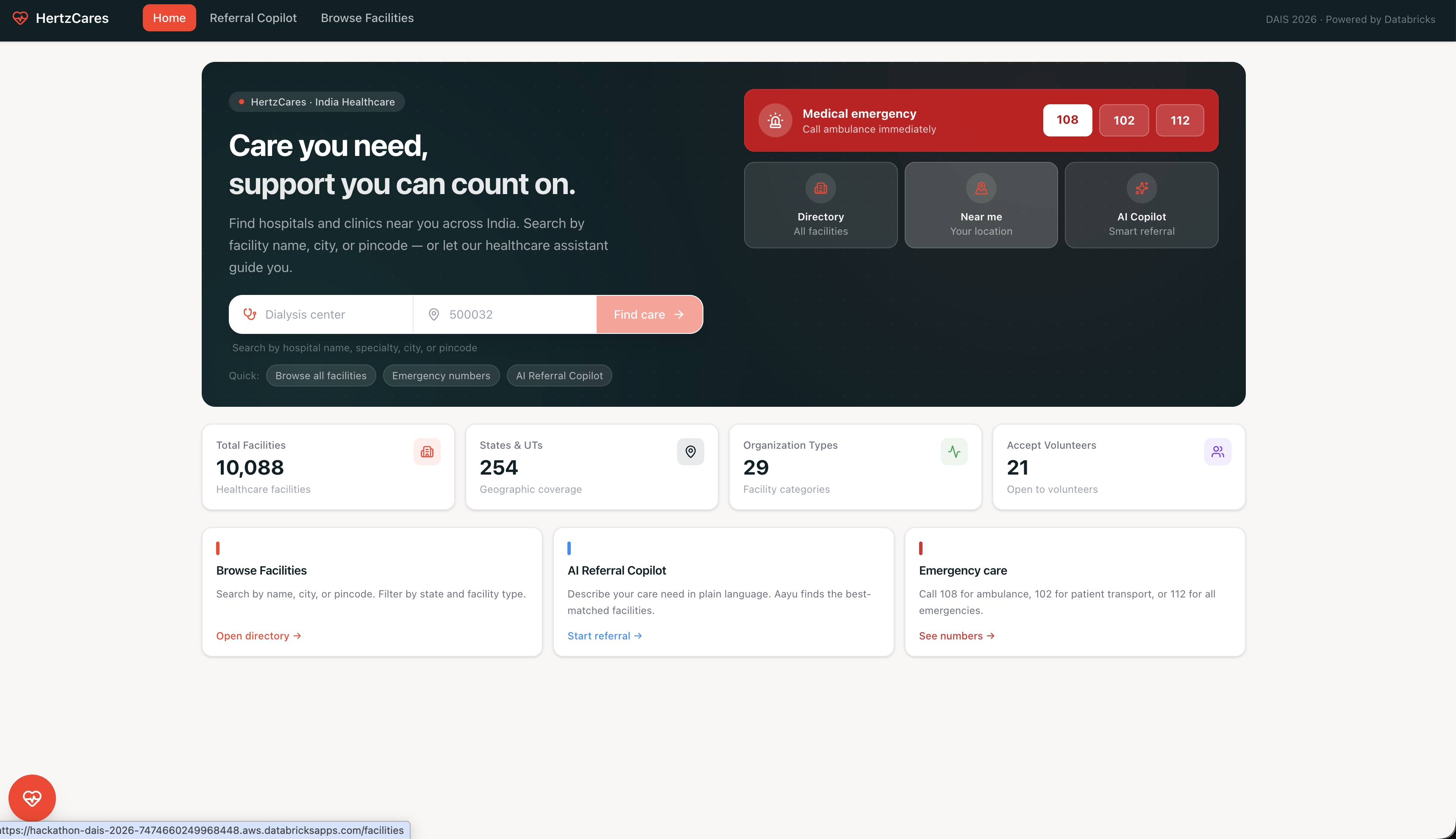
CareDelta is an India healthcare intelligence platform deployed as a Databricks App. It joins a 10,088-facility registry (sourced from HMIS, Wikidata, OSM, and Overture Maps) with NFHS-5 district health indicators across 706 districts across five tracks:
🗺️ Medical Desert Planner — an interactive heatmap + choropleth that scores every Indian state by a gap index: deprivation-weighted demand (electricity, water, sanitation, child registration) divided by trust-weighted facility supply. States with the highest gap scores are your medical deserts.
🤖 Aayu — AI Healthcare Assistant — a multilingual voice + chat assistant (English, Hindi, Telugu, Tamil) that helps patients and field workers find the right care. Aayu is grounded in the live facility database: every response cites real facility names, cities, and phone numbers. An emergency protocol surfaces 108/112 numbers instantly when life-threatening symptoms are detected. Voice is powered by ElevenLabs via a custom OpenAI-compatible LLM endpoint.
🔍 Referral Copilot — a full RAG search pipeline: GPT-4o-mini extracts location and care need from natural language, OpenAI embeddings + pgvector in Lakebase Postgres find the most relevant facilities, and GPT-4o re-ranks the shortlist with evidence quotes and confidence scores. Results can be saved to a persistent shortlist and sent via WhatsApp.
🏥 Facility Trust Desk — every facility gets a trust badge (Strong / Partial / Weak) based on how many independent source registries corroborate it across HMIS, Wikidata, OSM, and Overture Maps.
📊 Data Readiness Desk — completeness profiling, duplicate PK detection, and null-byte anomaly reports across the live facility table.
How we built it
Data pipeline: We ingested from six sources (HMIS, Wikidata, OSM Overpass, Overture Maps, GeoNames, India Post pincode directory) into Delta Lake on Unity Catalog. A PySpark enrichment job ran LLM-based column alignment (LLaMA 3.3 70B via Databricks Foundation Model APIs) to detect and fix CSV-shifted rows, then backfilled coordinates using a priority chain: original → Wikidata → OSM → Overture → GeoNames. All tables are CDF-enabled and synced to Lakebase Postgres.
App: React 19 + TypeScript frontend served by an AppKit Express backend, deployed as a Databricks App via DABs. The Medical Desert Planner uses MapLibre GL for the heatmap and choropleth. Analytics queries hit a Databricks SQL Warehouse with a 5-minute in-memory cache.
Referral Copilot: GPT-4o-mini extracts structured search terms from free text, Nominatim geocodes the location, OpenAI text-embedding-3-small embeds the query against a pgvector index in Lakebase, and GPT-4o synthesizes the final ranked shortlist with evidence, uncertainty notes, and patient-facing recommendations.
Aayu: A custom OpenAI-compatible SSE endpoint (POST /v1/chat/completions) acts as the LLM backend for ElevenLabs' voice agent. Every message — text or voice — is grounded by a live Lakebase query that injects real facility data into the GPT-4o system prompt before responding. Chat history is persisted to Lakebase.
Challenges we ran into
- Data fragmentation at scale: The facility registry had duplicate primary keys, null bytes in name/description fields, CSV-shifted columns, and coordinates outside India — all requiring multi-stage cleaning before any analysis was possible. The LLM alignment pass alone processed thousands of suspicious rows.
- State name mismatches: NFHS-5 uses
state_utnames ("NCT of Delhi", "Odisha") that don't match facilityaddress_stateorregionvalues ("New Delhi", "Orissa"). A gap-score join on raw strings silently fails for ~30% of states — we built a canonical alias map to fix this. - Lakebase quota limits: The workspace allowed only one concurrent synced-table pipeline, blocking multiple Lakebase syncs in parallel. We sequenced them carefully and worked around a duplicate-PK block on the facilities table.
- Trust score edge case: Spark SQL's
SIZE(SPLIT(NULL, ','))returns-1, not NULL, causing trust weights to go negative. Caught and fixed in the scoring formula. - ElevenLabs + custom LLM: Wiring ElevenLabs' voice agent to call our own backend as its LLM required implementing the full OpenAI streaming SSE spec at
POST /v1/chat/completions— and grounding every voice response in live DB data in under 200ms.
Accomplishments that we're proud of
- A fully deployed Databricks App that joins two previously disconnected datasets — facility supply and NFHS-5 demand — into a live gap score per Indian state, rendered on an interactive choropleth map.
- Aayu: a multilingual healthcare AI (English, Hindi, Telugu, Tamil) with an emergency protocol, live facility grounding, and ElevenLabs voice — that a patient in rural India can talk to in their own language and receive a real, verified facility recommendation.
- A full RAG referral pipeline: from a natural-language query like "dialysis near Jaipur" to a GPT-4o-ranked, evidence-backed shortlist with distance, capability scores, and a WhatsApp-sendable result — end-to-end in under 10 seconds.
- An LLM-powered data quality pipeline that automatically detected and corrected column-shifted rows across 10,000+ facility records using parallel Databricks Foundation Model API calls.
What we learned
- Joining messy real-world government datasets requires far more normalization work than the analytics itself — state name aliases, coordinate validation, null-byte cleaning, and PK deduplication took as much effort as building the UI.
- Databricks Foundation Model APIs made it practical to run LLM-based data quality checks at scale without standing up any external infrastructure.
- For healthcare in India, the interface is the product. A choropleth map serves a health planner; a voice assistant that speaks Hindi serves a patient. You need both.
- pgvector in Lakebase Postgres is a natural fit for RAG when your source data is already in Delta Lake — the synced-table pipeline gives you a live semantic search index with minimal extra infrastructure.
What's next for CareDelta
- District-level gap scoring: the current gap score is state-level; drilling to district level with NFHS-5's 706 districts would unlock much more targeted intervention planning.
- Resolve Lakebase sync blockers: deduplicate facility PKs and free up the quota slot to bring the full facilities synced-table online for OLTP reads.
- Aayu on WhatsApp: expose Aayu as a WhatsApp chatbot so patients can get facility recommendations without installing anything.
- Persistent caching + parameterized queries: harden the backend for production use beyond the hackathon demo.
- Expand Aayu languages: Bengali, Marathi, Kannada, and Malayalam to reach more of India's linguistic diversity.
Built With
- databricks-apps
- databricks-asset-bundles-(dabs)
- databricks-foundation-model-apis-(llama-3.3-70b)
- databricks-sql-warehouse
- delta-lake
- elevenlabs
- express.js
- geonames
- hmis
- india-post-pincode-directory
- lakebase-postgres
- maplibre-gl
- nominatim-(openstreetmap-geocoding)
- openai-gpt-4o
- openai-gpt-4o-mini
- openai-text-embedding-3-small
- osm-overpass
- overture-maps
- pgvector
- pyspark
- python
- react-19
- typescript
- unity-catalog
- vite
- whatsapp-business-api
- wikidata

Log in or sign up for Devpost to join the conversation.