En aquest projecte hem provat diferents models que permeten: 1) Classificar els pacients en alt risc (HR) o baix risc (LR) - definit com haver patit una recidiva als 3 anys (models de RF, logistic regression,svm, XGBoost i un ensembl dels tres primers); 2) Determinar un valor de risc de les pacients tenint en compte tant la possibilitat d'haver tingut la recidiva com el temps al esdeveniment utilitzant models de supervivència (random survival forest i cox proportional hazard).
1) Preprocessing
Hem escollit de forma manual unes 100 variables que hem considerat d'interès clinic que després han estat filtrades segons el nº de NAs (>15%) per a l'entrada en el model. Hem fet un hot-encoding de totes les variables categòriques i un scaling de les continues.
Hem creat una categoria de risc ("risk status" per a fer classificació que definim com el estat del pacient als 3 anys (recidiva, si o no). Els pacients perduts (últim seguiments) abans dels 3 anys és consideren sense informació: NA. Així evitem considera els pacients sense informació com a sense events.
Dins dels CV hem realitzat un FCBF (fast correlation based filtering) per a seleccionar les millors variables, no correlacionades durant el training.
També hem creat un script que realitza aquest pre-processament al introduir un nou pacient.
2) Entrenament
Hem entrenat 3 models de classificació (models de RF, logistic regression,svm, XGBoost) i un ensembl dels tres primers per a classificar els pacients en alt risc (HR) o baix risc (LR) - definit com haver patit una recidiva als 3 anys.
Hem entrenat dos models que realitzen regressió utilitzant models de supervivència (random survival forest i cox proportional hazard).
3) Metriques i test
El millor performance l'hem obtingut amb el model de stacking de classificació, amb un 0.97 en AUC en el CV. Les mètriques són molt bones en el entrenament i validació, però han dissminuit en el test (13 pacients).
4) Interpretabilitat
També hem fet una ullada a les variables que tenen més pes per a fer les prediccions per a que el model a més de predir un risc o determinar els grups dels pacients, sapiguen quins són els grups de risc mirant a les dades clíniques. Aquest variables més importants inclòuen la infiltració al cèrvix i valor de CA125, però a més que alguns tipus histològics concrets tenen un risc més alt.
5) Resultats i visualització
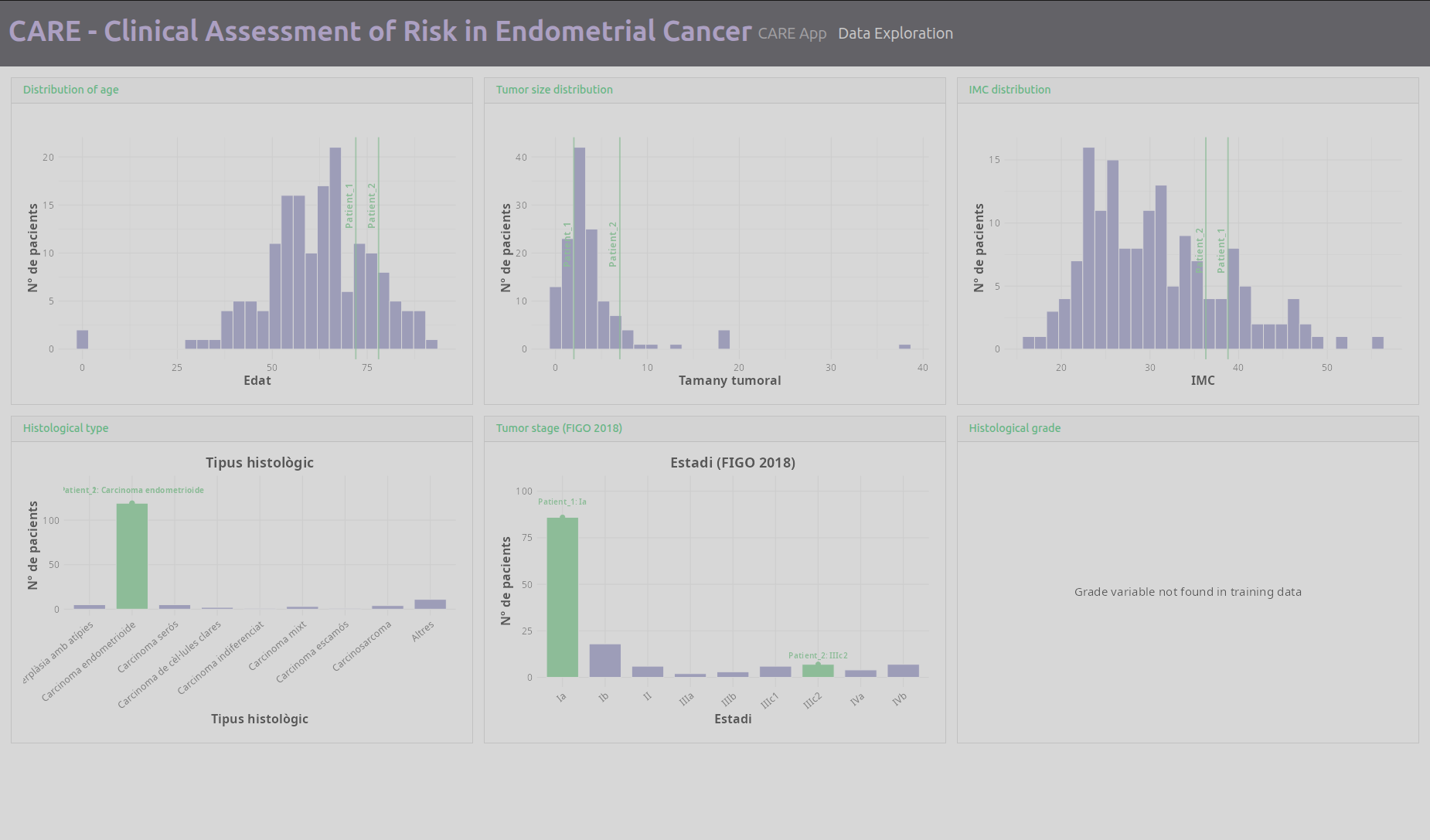
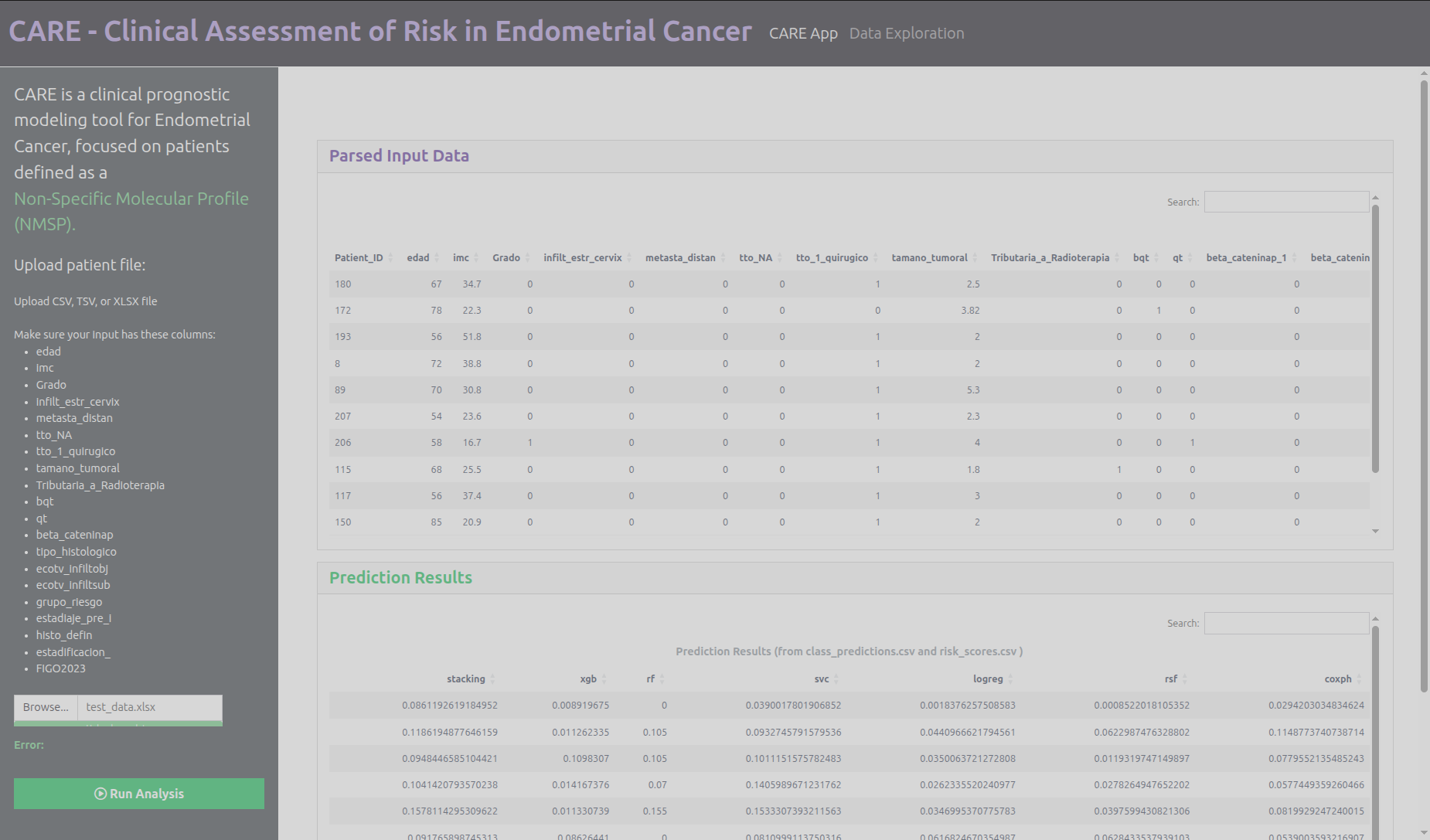
Finalment hem creat una aplicació (Shiny) on apareixen les dades del pàcient en una taula que introduïm nou comparades amb la distribució dels pacients d'entrenament. Amb la introducció d'aquests pacients també és realitza un pre-processament i posteriorment hauria d'enviar aquestes dades al model d'inferència per a que aparegui en l'aplicació la predicció
Aquest punt no l'hem pogut completar: tenim el model d'inferència que hem probat amb uns pacients test, però no hem pogut conectar a la introducció del nou pacient en l'aplicació durant el temps de la hackaton.

Log in or sign up for Devpost to join the conversation.