-
-

Team
-

AI Patient Conversation Platform
-

Problem Part 1
-

Problem Part 2
-

Solution
-
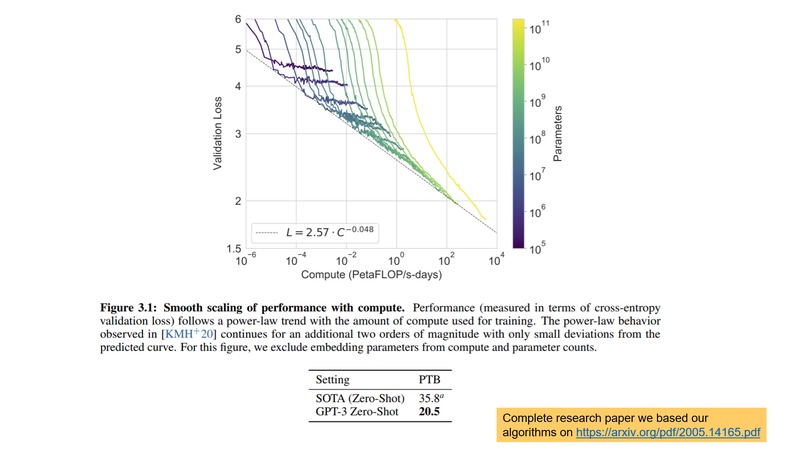
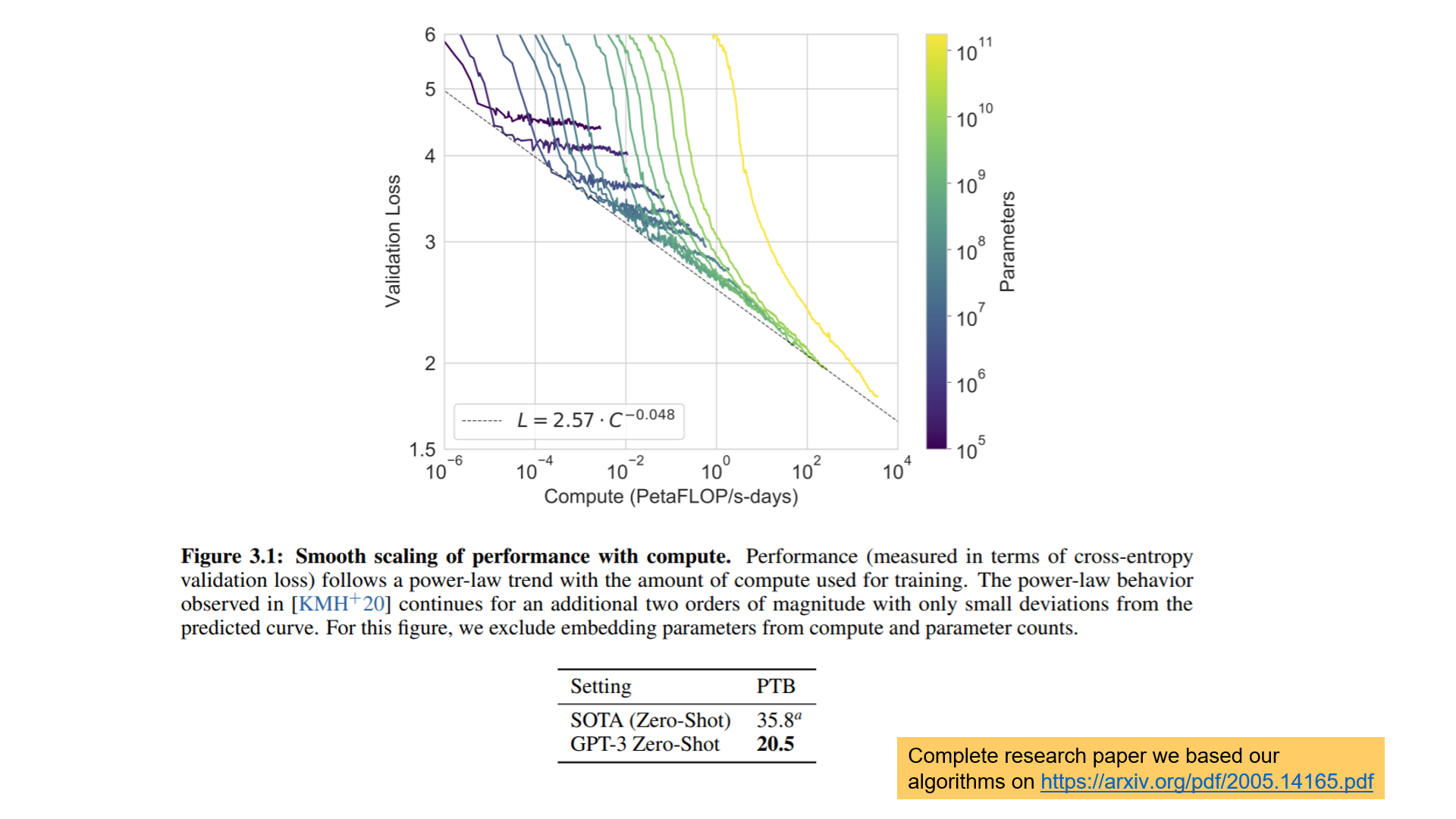
GPT-3 research paper our algorithms are based from
-
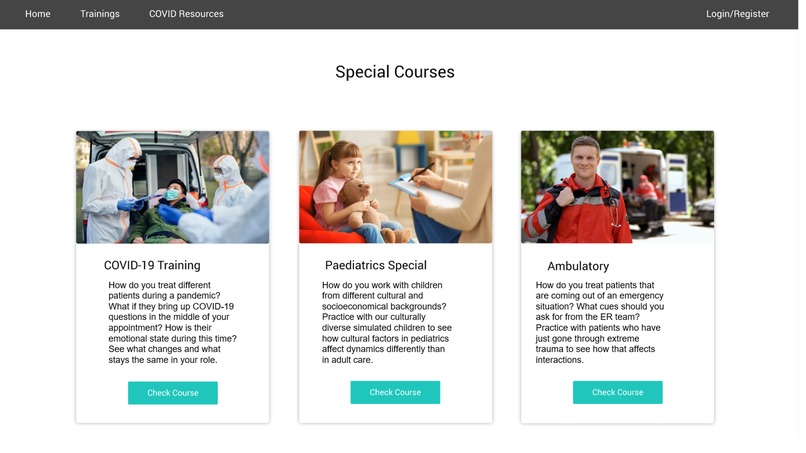
Examples of different training modules for healthcare professionals
-

-

Market Size
-

Alignment With Judging Criteria









Inspiration
COVID-19 has changed the way we treat patients (i.e. telehealth). It's also changed the way we TALK to patients. We have no good way to train that. The US spends $15 billion a year on training doctors. In 2011 med schools mandated cultural competency training, as only 8% have an official course on it. This costs $55 billion through malpractice expenses, 2.4% of total healthcare costs in the US. Our team leader has been a clinician at multiple hospitals and has personally seen these difficulties.
What it does
Care Coach is a cultural competency training platform for medical professionals to improve their bedside manners across a variety of dynamic settings using GPT-3. We provide medical practitioners to instantly create patient profiles for specific settings (i.e. COVID-19, Black Lives Matter) repeatedly, and get feedback on.
Note this platform can become a cross-industry AI training platform for cultural competency. For example, Facedrive and HiRide can use this platform to train drivers on how to deal with certain customers (i.e. drunk, sexual harrassment, confrontational, etc.)
How I built it
Carecoach uses automated conversation generation techniques with an engine driven by elements of OpenAI's GPT2 and GPT3.
The basic approach we used was to take a pretrained model (training such a model from scratch is prohibitively expensive ~5 M$) and applied a few-shot method.
GPT type models are generative, and they employ a shallow/sparse transformer approach in order to generate coherent words of phrases according to context. We use a few shot example of 10 conversations as input to the model, and thereby extract the result phrases as the response from the automated bot.
Currently this approach works decently between 3 - 4 turns of a conversation, and supplementing this with additional input data from real life interactions and classical NLP techniques shows promise.
GPT-3 for the ML model Reactjs for the web interface ffmpeg, moviepy (they're both python libraries) for video generation modified version of pydub (a python library) for silence detection Azure Speech to Text for converting trainee's speech Azure Text to Speech Neural Voice for the avatar's voice Various react libraries for recording audio, webcam, playing video, recording training session Azure cloud functions for creating endpoints AdobeXD for UI/UX prototyping Adobe Premiere for creating gifs of avatars
Challenges I ran into
Going beyond 3 turns in a conversation. Silence detection. Video is generated on the fly so there's a delay / echo so far.
Accomplishments that I'm proud of
Getting validation from multiple hospital groups that are interested in learning more about the product and potentially trialing it in their environment. What you build matters only if it solves a real problem.
Leveraging GPT-3 in a novel way that we have not currently seen in the public domain so far. The technical discoveries we made during this hackathon will be a subject of a future research paper from our team.
What I learned
How to stitch together text output and an avatar visually mouthing those words in sync. How to leverage GPT-3 for an accurate, multi-turn conversation in a medical environment. How to navigate the healthcare environment to understand the budgeting process, vendor selection, and stakeholder navigation.
What's next for Care Coach
In the middle of talks with several hospitals such as Providence Health, Kindred Care, and Inland Empire Health Plan to run a pilot. Looking to close a deal and test the platform out.
We're also looking to add further training data from conversation transcripts to train our model from a hospital partnership.
Log in or sign up for Devpost to join the conversation.