-
-
Project in VS code
-
Project in VS code
-
Project in VS code
-
Project in VS code
-
Project in VS code
-
Project in VS code
-
Project website
-
Project website
-
Project website
-
Project website
-
Coder workspace
-
Coder workspace
Inspiration
I lost my father to cardiac arrest back in 2022. I am an AI enthusiast and have deep interest in human anatomy. Saw this hackathon and instantly hit to work and contribute something meaningful in this space!
What it does
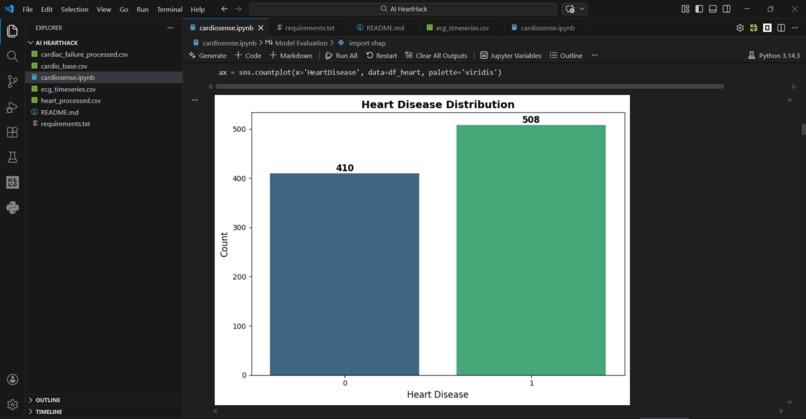
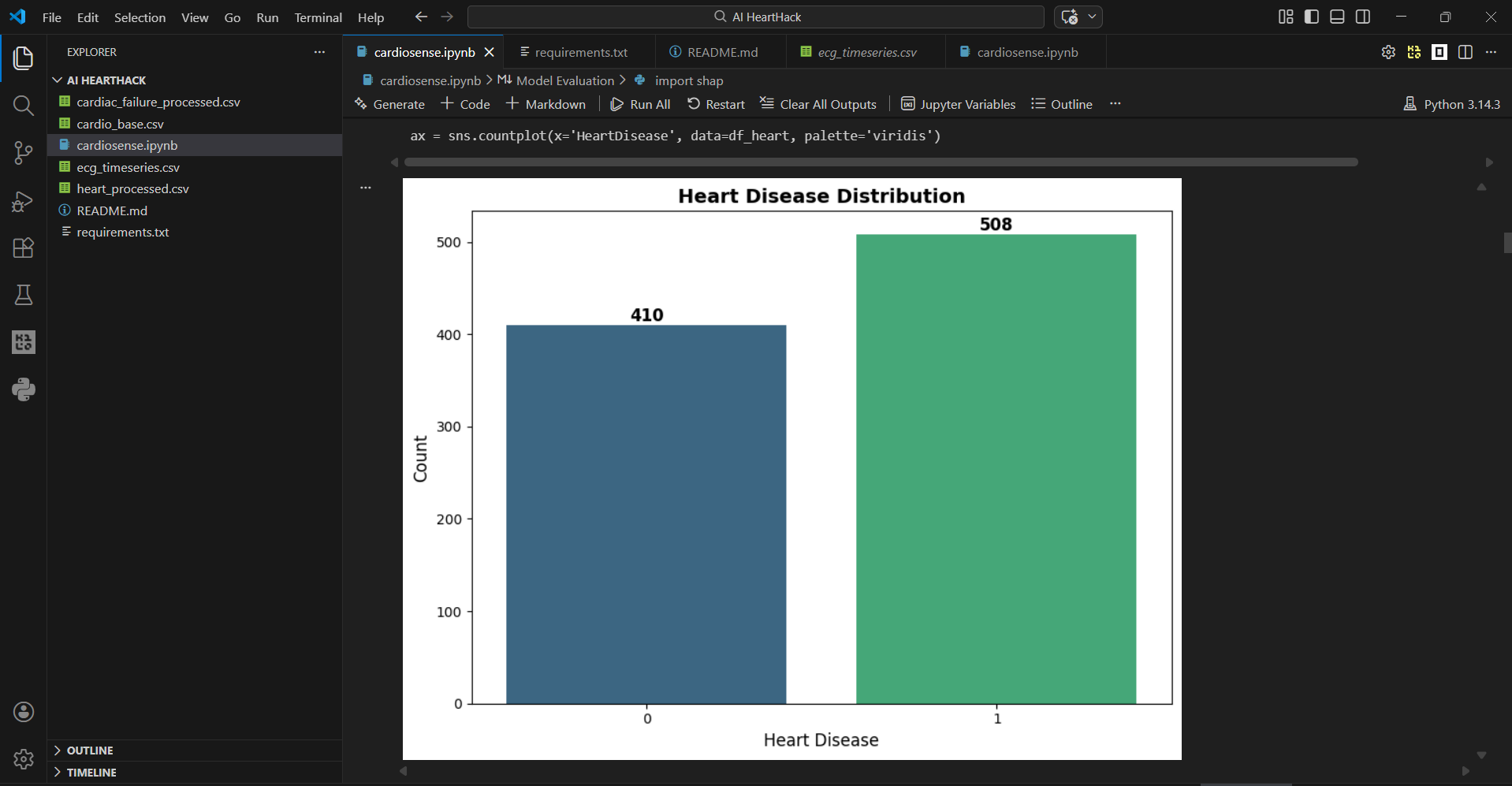
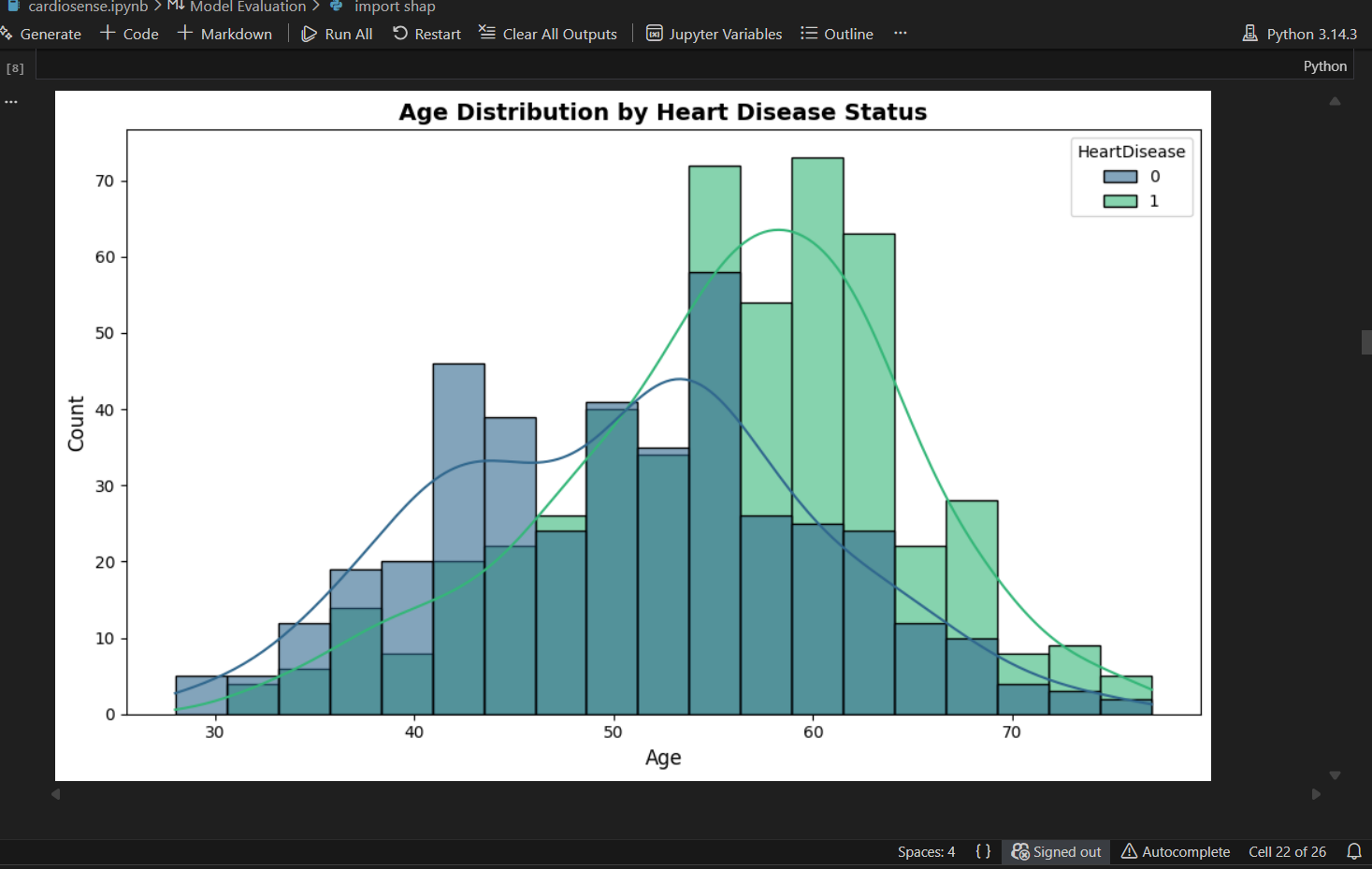
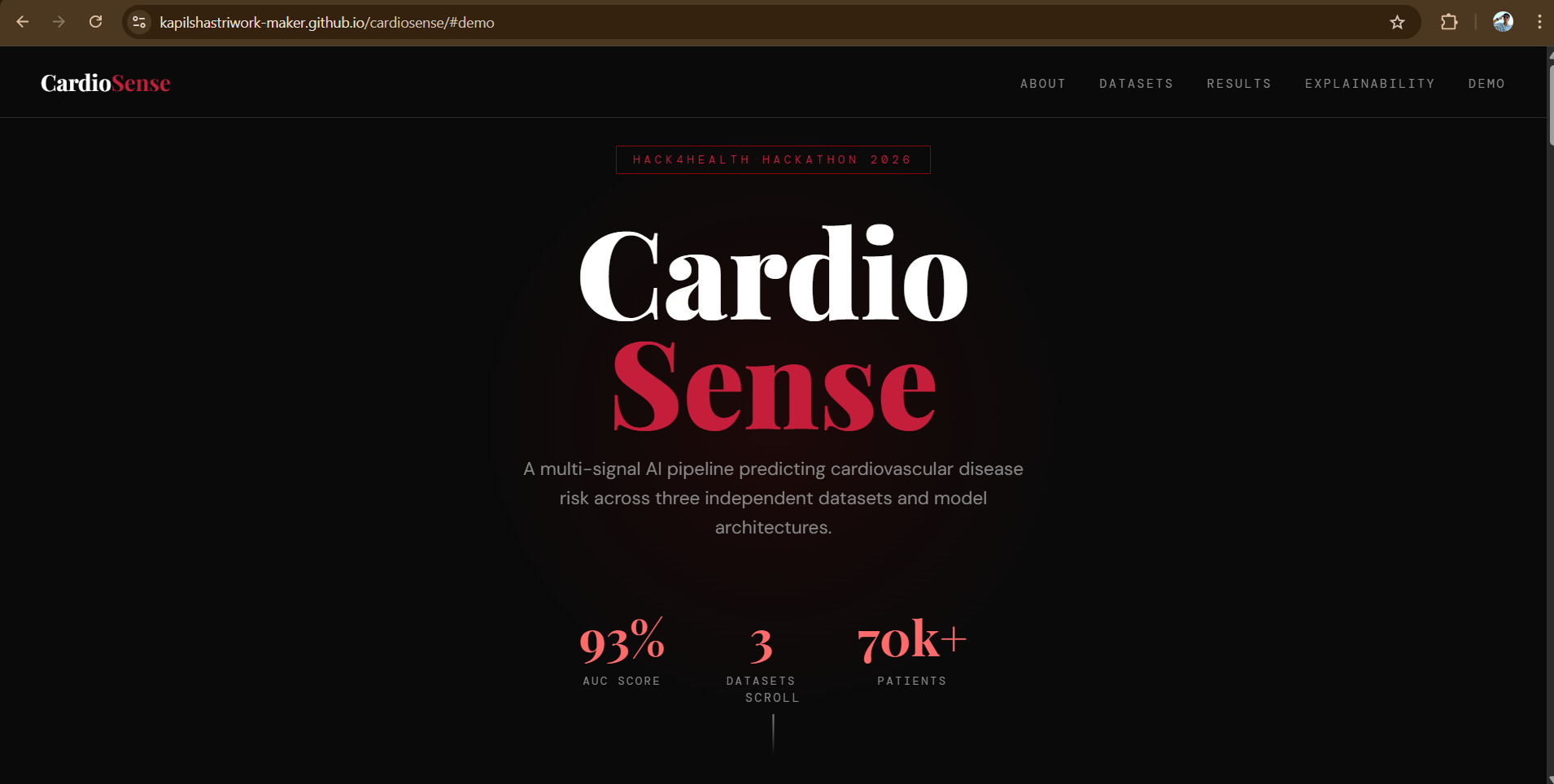
CardioSense is a multi-signal cardiovascular risk prediction pipeline that analyses three different types of medical data to assess a patient's heart disease risk.
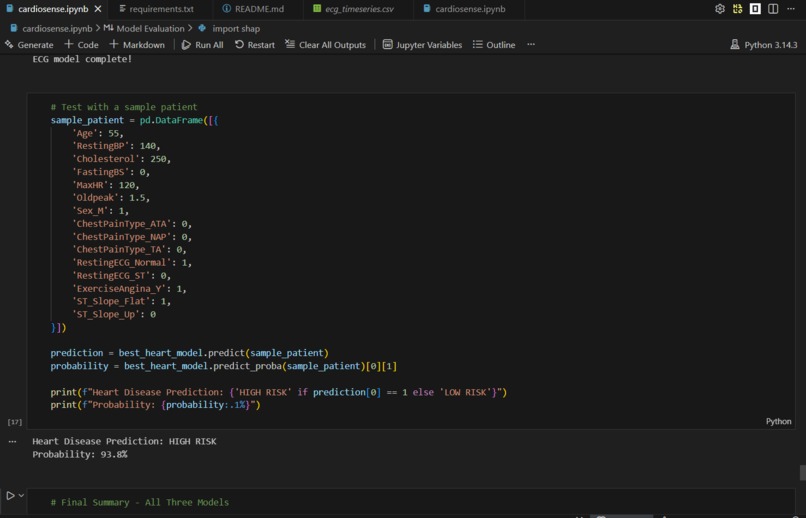
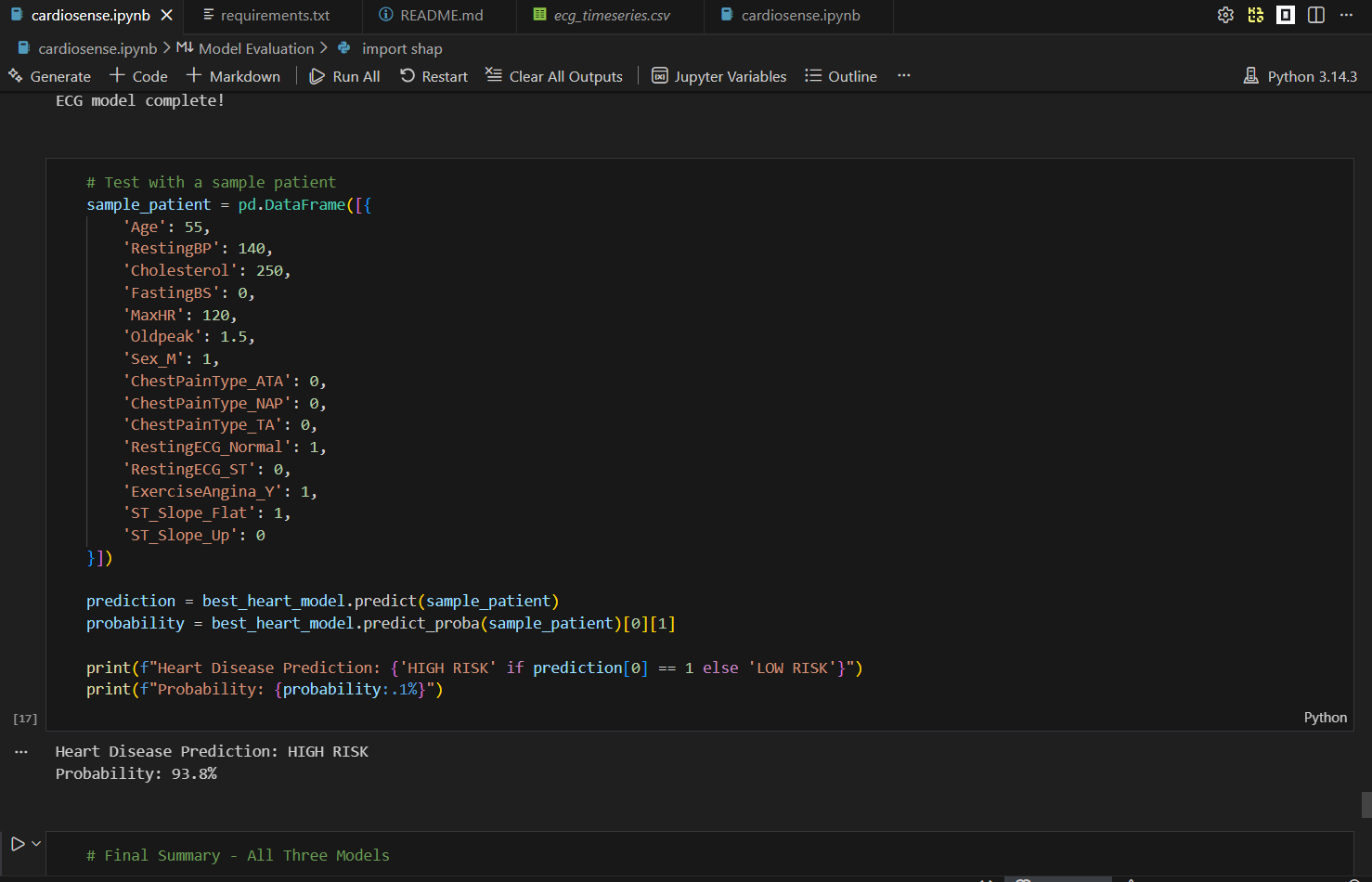
It takes clinical measurements, lifestyle factors, and ECG signal data as inputs and predicts whether a patient is at high or low risk of cardiovascular disease, along with a probability score. For example, a 55-year-old male with elevated cholesterol, high blood pressure, and exercise-induced chest pain returns a HIGH RISK prediction with 93.8% confidence in under one second.
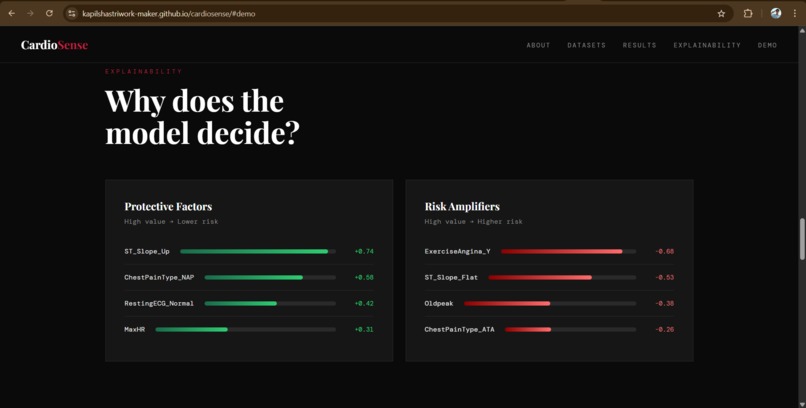
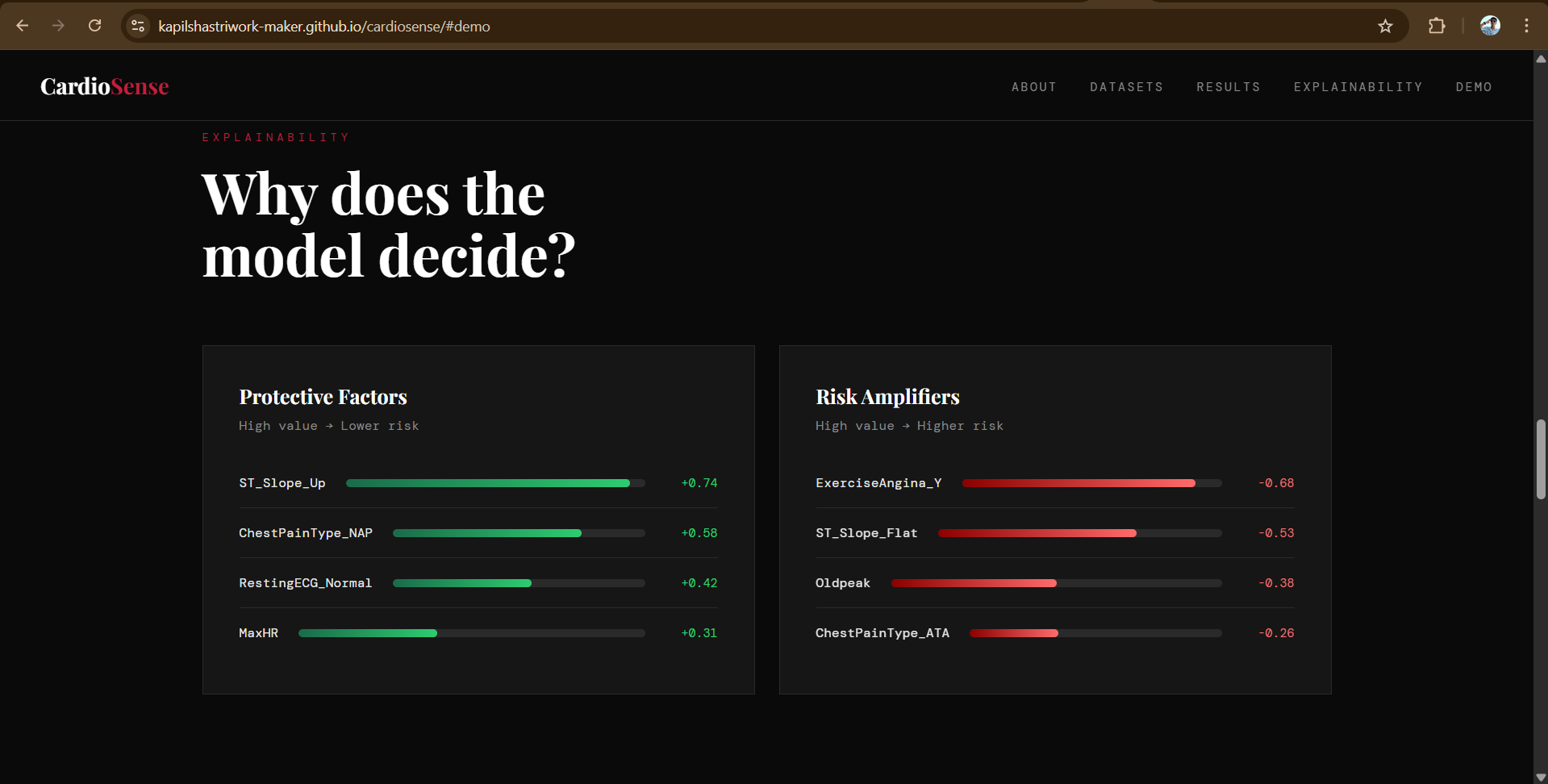
Beyond prediction, CardioSense explains its reasoning using SHAP analysis, showing doctors and patients exactly which factors drove the risk assessment. This makes it not just a prediction tool, but a clinically actionable one.
How we built it
CardioSense was built entirely in Python using a Jupyter Notebook environment.
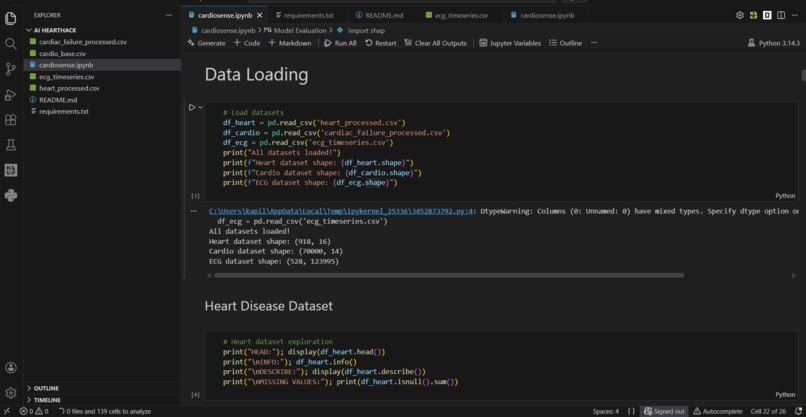
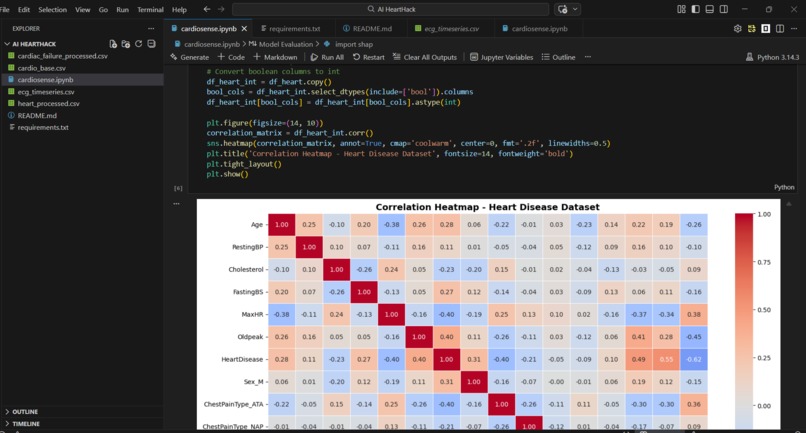
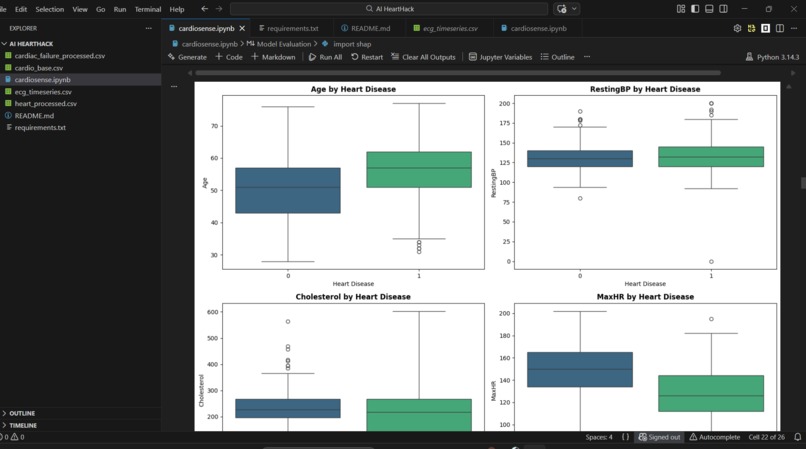
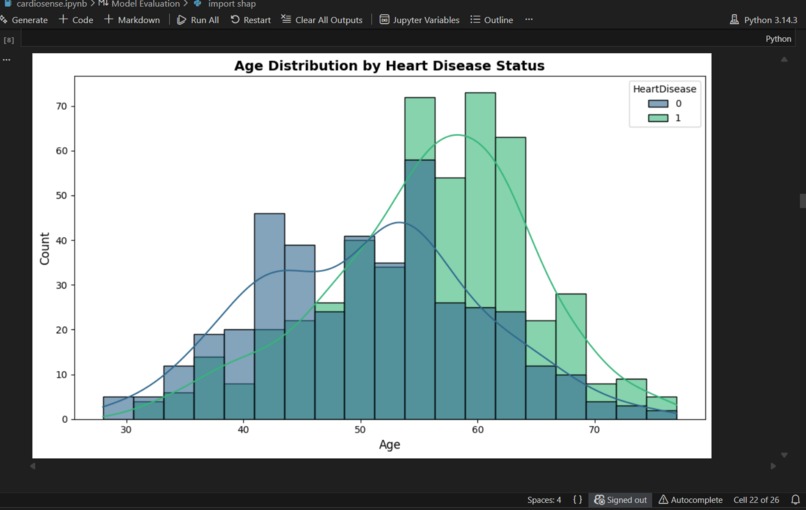
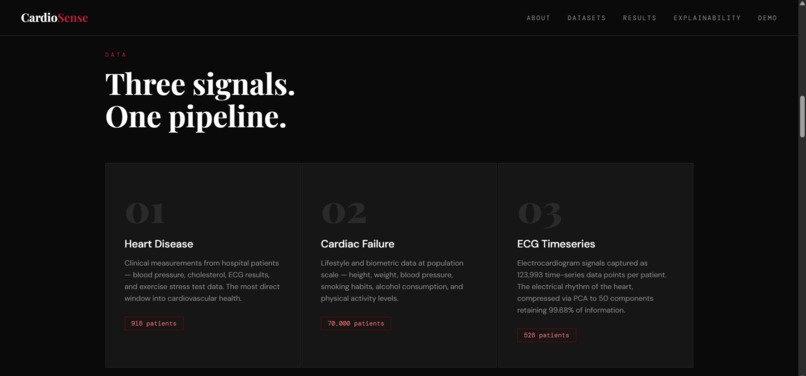
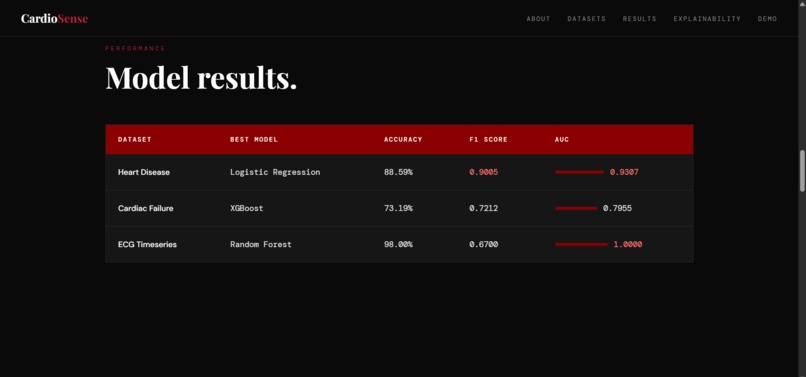
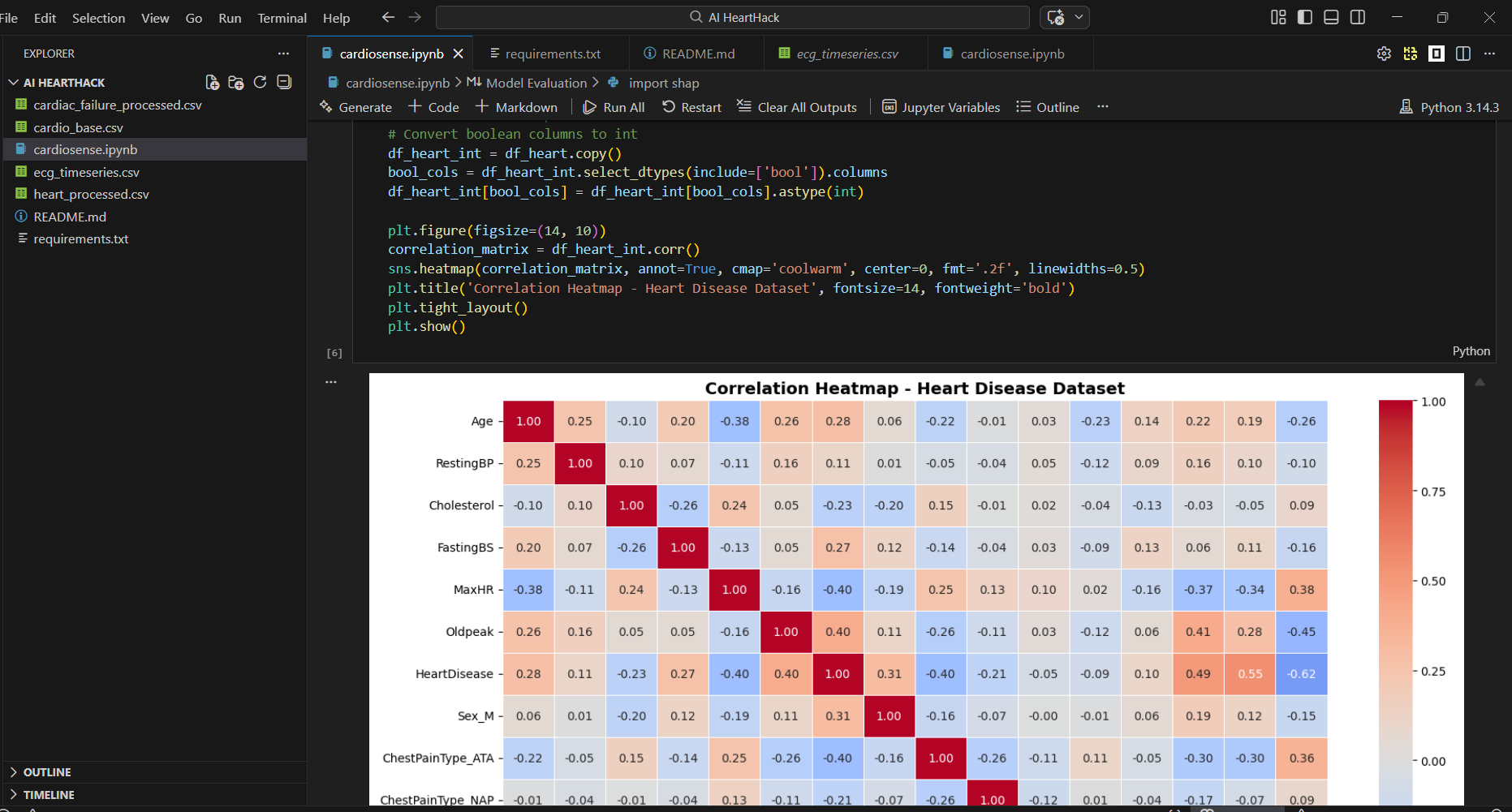
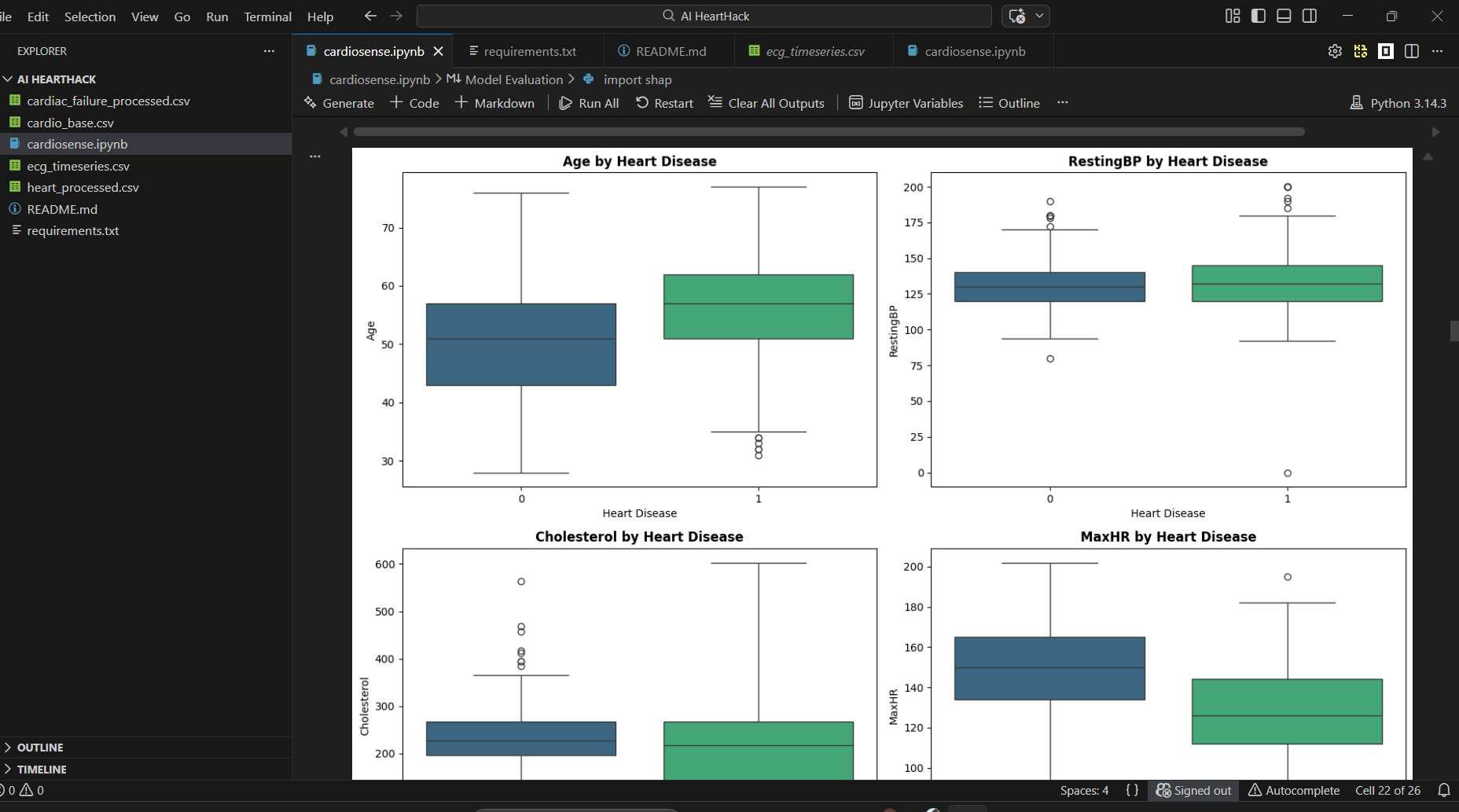
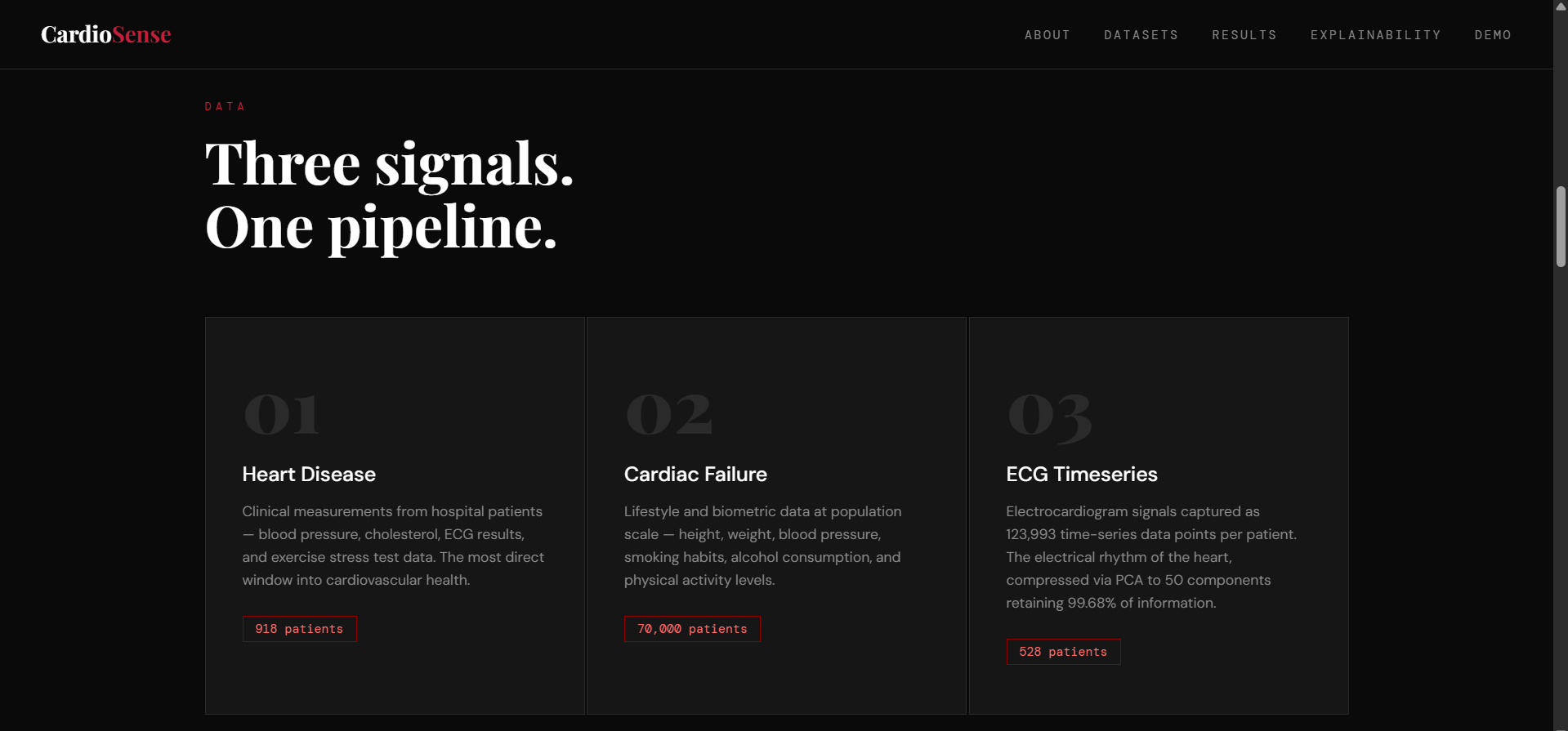
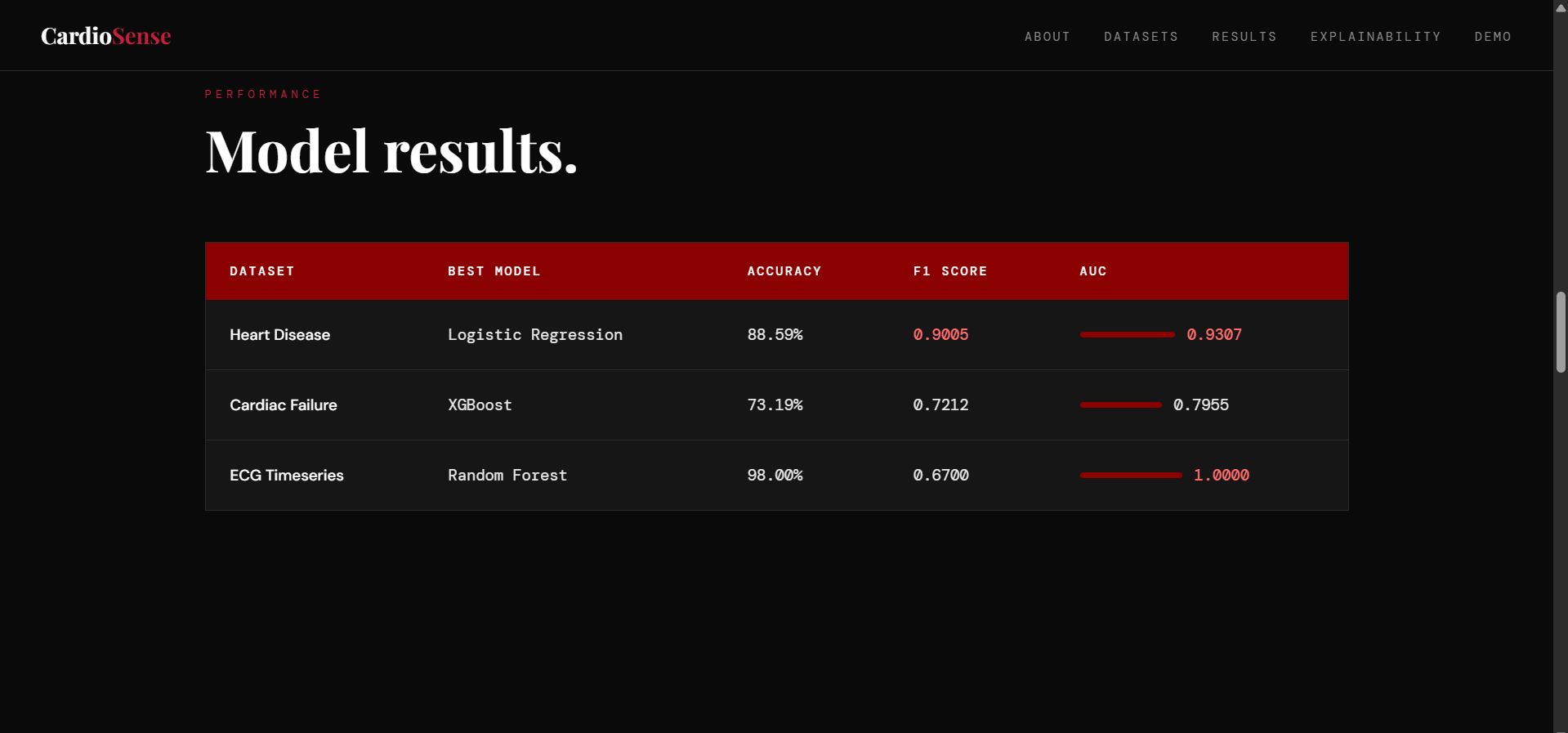
Data Pipeline: Three datasets were preprocessed independently. The Heart Disease dataset required boolean-to-integer conversion for sklearn compatibility. The Cardiac Failure dataset was normalised using StandardScaler to handle heterogeneous feature scales. The ECG Timeseries dataset presented a dimensionality challenge, 123,993 feature columns for 528 patients, which we solved using PCA, reducing to 50 components while retaining 99.68% of explained variance.
Modelling: For each dataset, we ran a comparative experiment across three algorithms, like Logistic Regression, Random Forest, and XGBoost and using stratified 80/20 train-test splits with fixed random seeds for full reproducibility. Models were evaluated on F1 score, precision, recall, accuracy, and ROC AUC.
Challenges we ran into
Dimensionality of the ECG dataset was the biggest technical challenge. With nearly 124,000 columns and only 528 rows, standard modelling approaches would either crash or overfit severely. We solved this with PCA dimensionality reduction, which made the dataset tractable without significant information loss. Class imbalance in the ECG dataset was a second challenge, only 21 positive cases out of 528 patients. This resulted in a perfect AUC score that must be interpreted carefully. We acknowledged this limitation honestly rather than presenting it as a clean win.
Working across three completely different data types, clinical, lifestyle, and electrophysiological , where each required a different pre-processing strategy, which added significant complexity to the pipeline.
Accomplishments that we're proud of
We are proud of building a complete, end-to-end machine learning pipeline across three datasets, not just a single model on a single dataset, which is the typical approach.
We are proud of achieving 93% AUC on the Heart Disease dataset, a clinically meaningful result that aligns with published research benchmarks.
We are proud of the SHAP explainability layer, the finding that ST slope and exercise-induced angina are the strongest predictors matches established cardiology literature, which validates that our model is learning genuine medical patterns rather than noise.
We are proud of building something that works in real time, a patient's data can be entered and a risk prediction returned in under one second.
Most of all, we are proud of building this as a solo participant with limited skills on certain areas of coding, still I managed to bridge the gap between vision and execution.
What we learned
We learned that different types of medical data require fundamentally different pre-processing strategies, there is no one-size-fits-all pipeline in healthcare machine learning.
We learned that model performance metrics must be interpreted in context, a perfect AUC is not always a genuine result, and acknowledging limitations honestly is more valuable than presenting inflated numbers.
We learned the importance of explain ability in healthcare AI. A model that cannot explain its reasoning is not deployable in a clinical setting, regardless of its accuracy.
We learned that Logistic Regression, often considered a simple baseline, can outperform complex ensemble methods when the underlying relationships in the data are linear. Complexity is not always better.
Most personally, we learned that technology built with genuine purpose is more powerful than technology built for its own sake.
What's next for CardioSense
Long term Vision Collect and incorporate Indian demographic data. Current training datasets are predominantly Western in origin, which limits the system's reliability for Indian patients. Partnering with Indian hospitals and clinics for anonymised patient data would be a critical next step.
Wrap the inference pipeline in a lightweight web API using Flask or FastAPI, enabling integration with existing clinic management software. The goal is to offer CardioSense as a free AI-assisted screening tool, first in small clinics and hospitals, and eventually in gyms and fitness centres where early detection could reach people before they ever visit a doctor.
Expand the CardioSense framework beyond cardiovascular disease. The same multi-signal, multi-model approach could be applied to liver disease, lung conditions, and diabetes screening, building toward a generalised AI health screening platform accessible to everyone.
Built With
- code
- coder
- matplotlib
- numpy
- pandas
- provisioning
- python
- reproducible
- scikit-learn
- seaborn
- shap
- terraform
- via
- visual
- vscode
- workspace
- xgboost

Log in or sign up for Devpost to join the conversation.