-
-
App Interface
-
App Interface
-
App Interface
-
App Interface
-
Signal Generator
-
Stage2
-
Signal Generator
-
Stage2
What Inspired Us
Atrial fibrillation affects roughly 33 million people worldwide, and an estimated 40% of those cases go undiagnosed until a major event occurs — a stroke, a clot, or an emergency hospitalization. The diagnostic gap exists because AFib is paroxysmal: episodes come and go, often resolving before a patient reaches a clinic. Detecting it reliably requires continuous ambulatory monitoring, which in turn demands hardware that is wearable, software that runs on the edge, and an interface that is unobtrusive enough to be worn for days at a time.
Existing consumer cardiac monitoring tools fall into two categories, both unsatisfying. The first refuses to commit to a clinical interpretation — typically due to regulatory constraints — and merely displays raw waveforms. The second produces confident classifications even when the underlying signal is corrupted, because the model was trained to always select a class. We saw an opportunity for a third option: a system that classifies confidently when the signal supports it, and explicitly defers when it does not.
A third motivation was data privacy. Cardiac data is among the most sensitive biometric information a person can produce. We were uncomfortable with architectures that route raw ECG to cloud services for inference. CardioSense was therefore designed from the outset to perform every step — capture, cleaning, classification, and display — locally, with no patient data leaving the user's own devices.
The project began with a single, focused question: Could a small team build the entire pipeline a real arrhythmia patch would require — from electrode to phone — within 36 hours, on commodity hardware, without cloud infrastructure?
How We Built Our Project
CardioSense is a four-layer system: hardware capture, signal processing, machine-learning classification, and an iOS dashboard. Each layer communicates with the next through a versioned JSON contract, allowing components to be developed and replaced independently.
Architecture-first design. Before writing any production code, we defined three JSON schemas — one for each interface boundary. This allowed our four contributors to develop in parallel against mocked counterparts, eliminating cross-team blocking and minimizing integration friction.
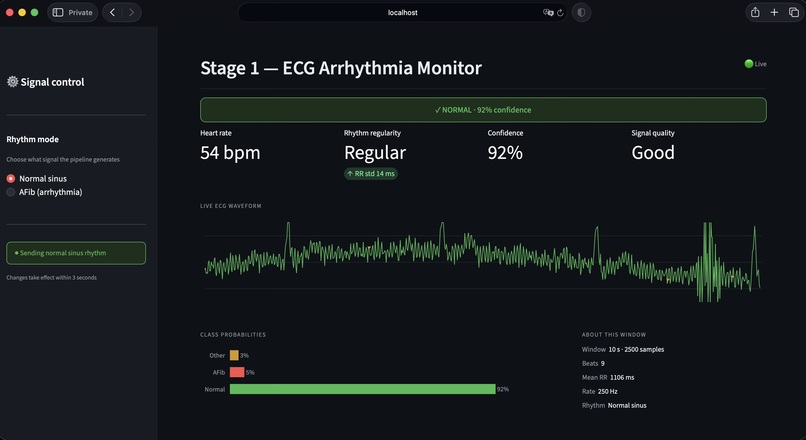
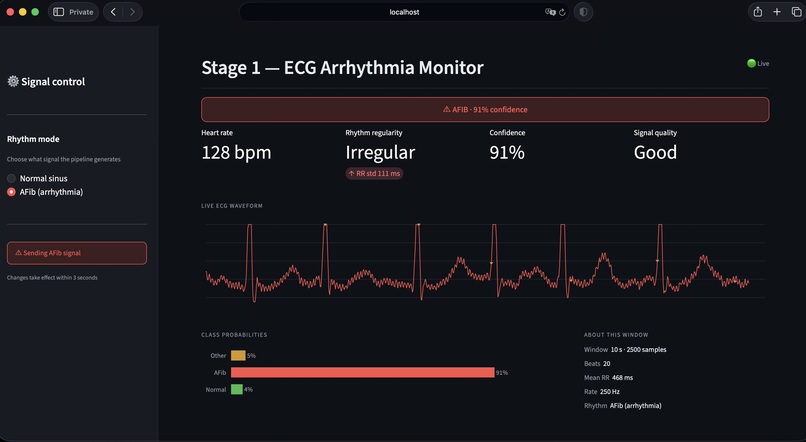
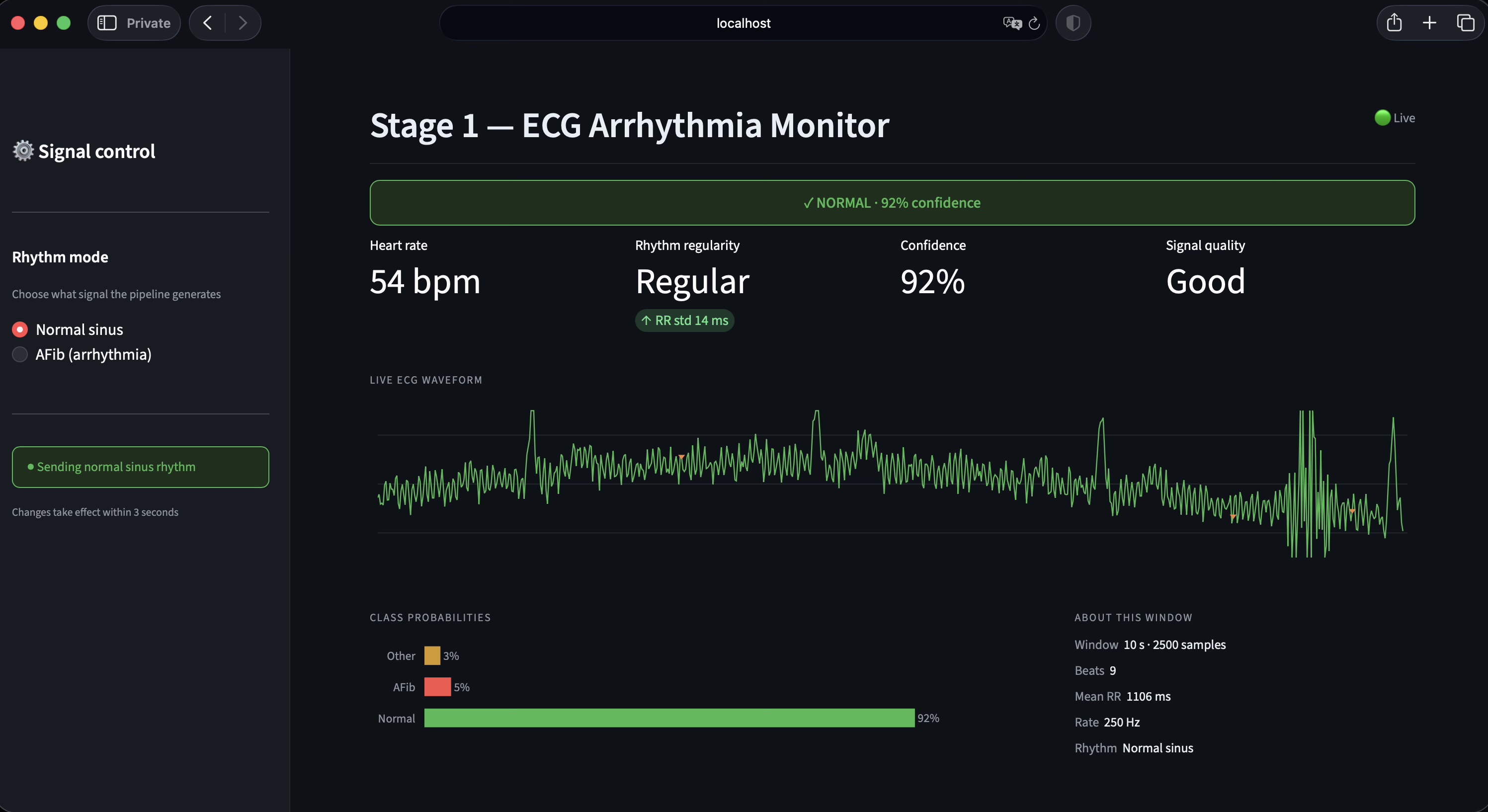
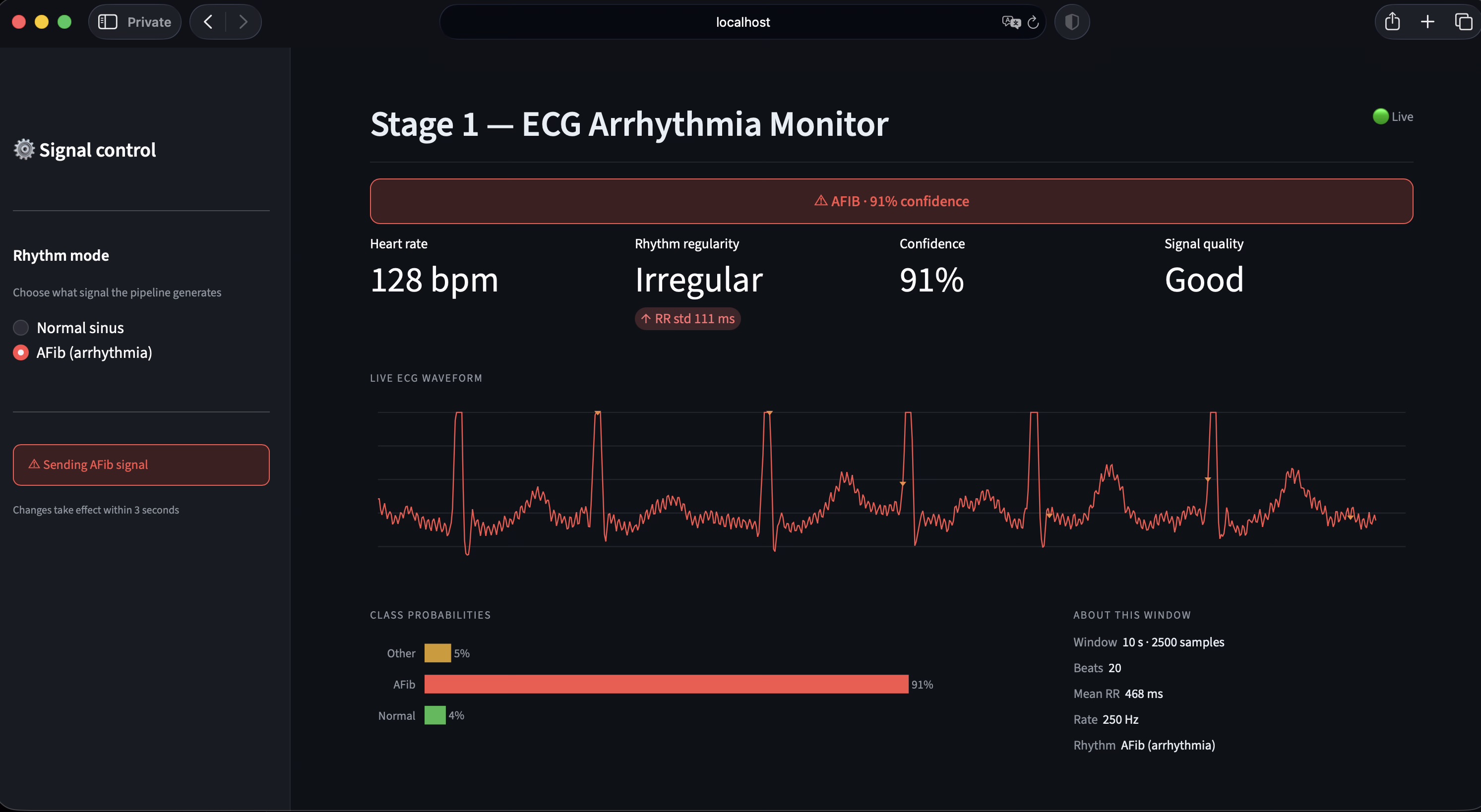
Stage 1 — Signal source. Stage 1 emits a continuous 250 Hz ECG stream that mimics the output of a Bluetooth ECG patch. A Streamlit control surface allows the operator to toggle between Normal sinus rhythm and atrial fibrillation modes during the demo.
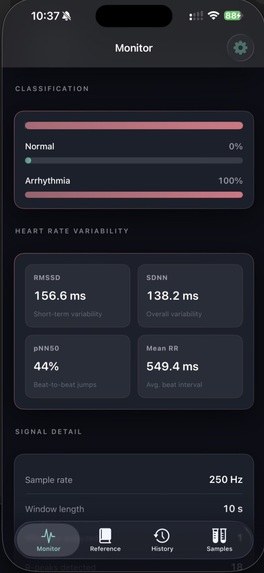
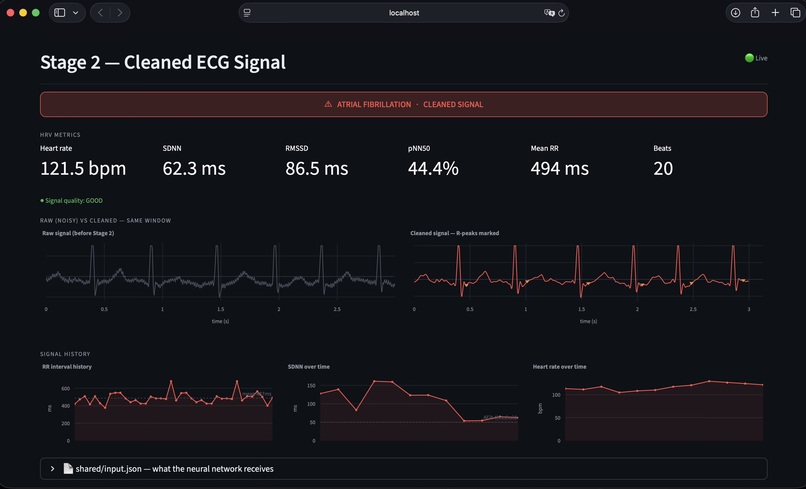
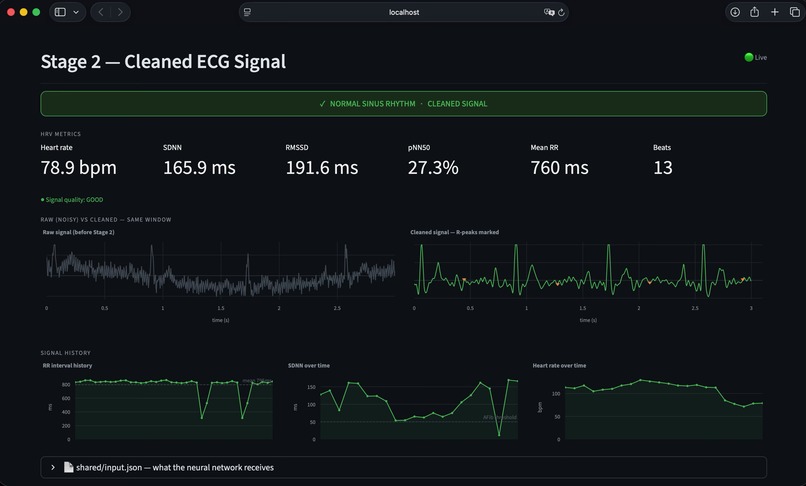
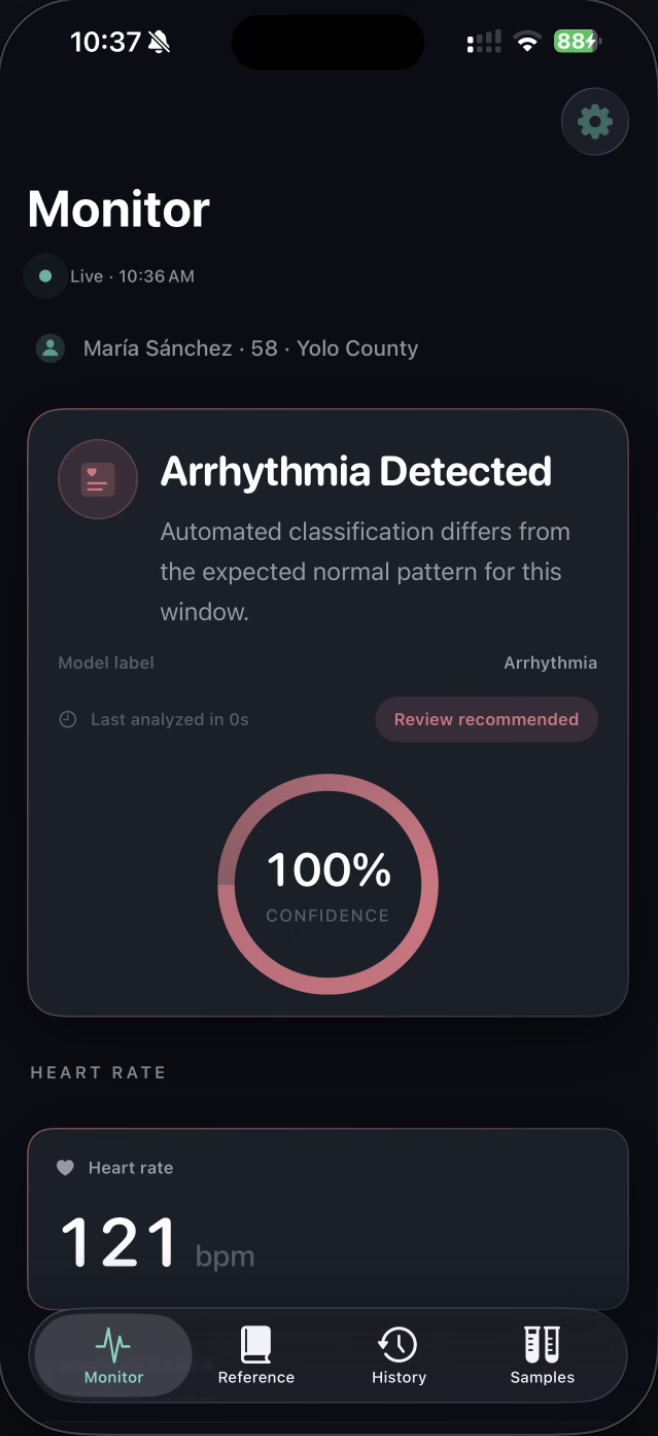
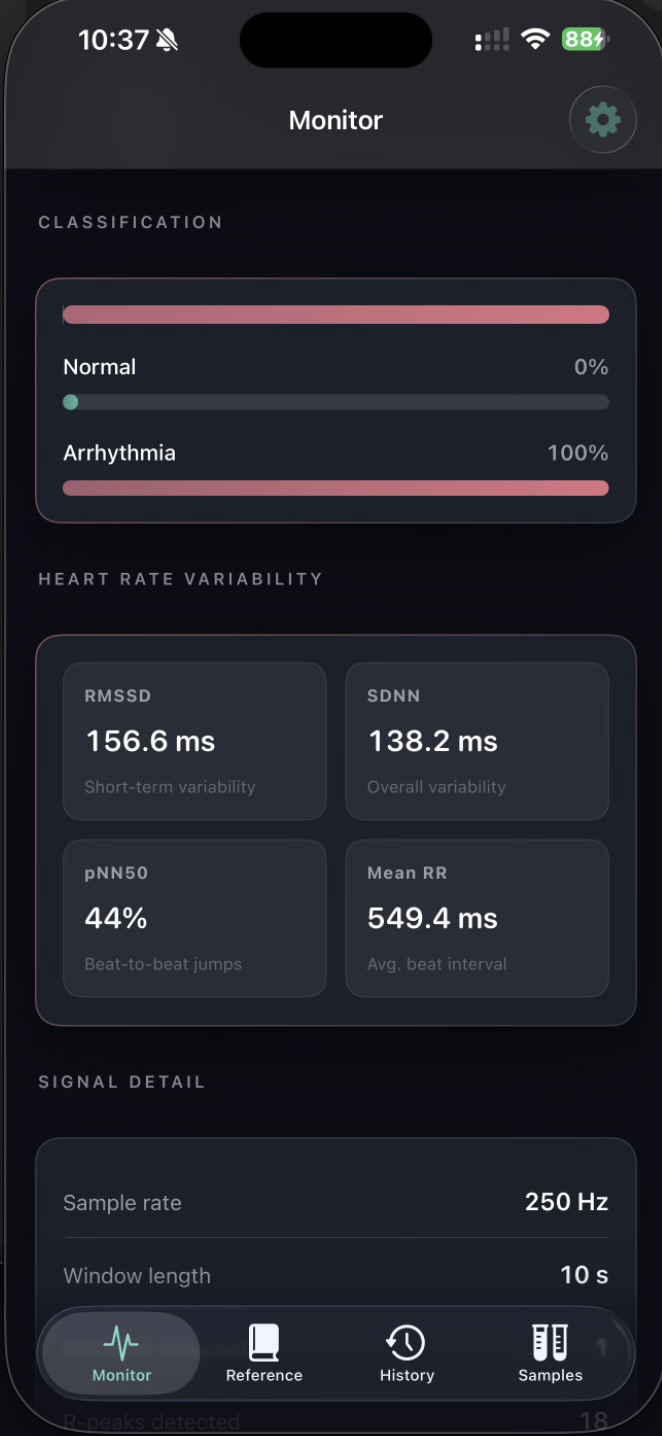
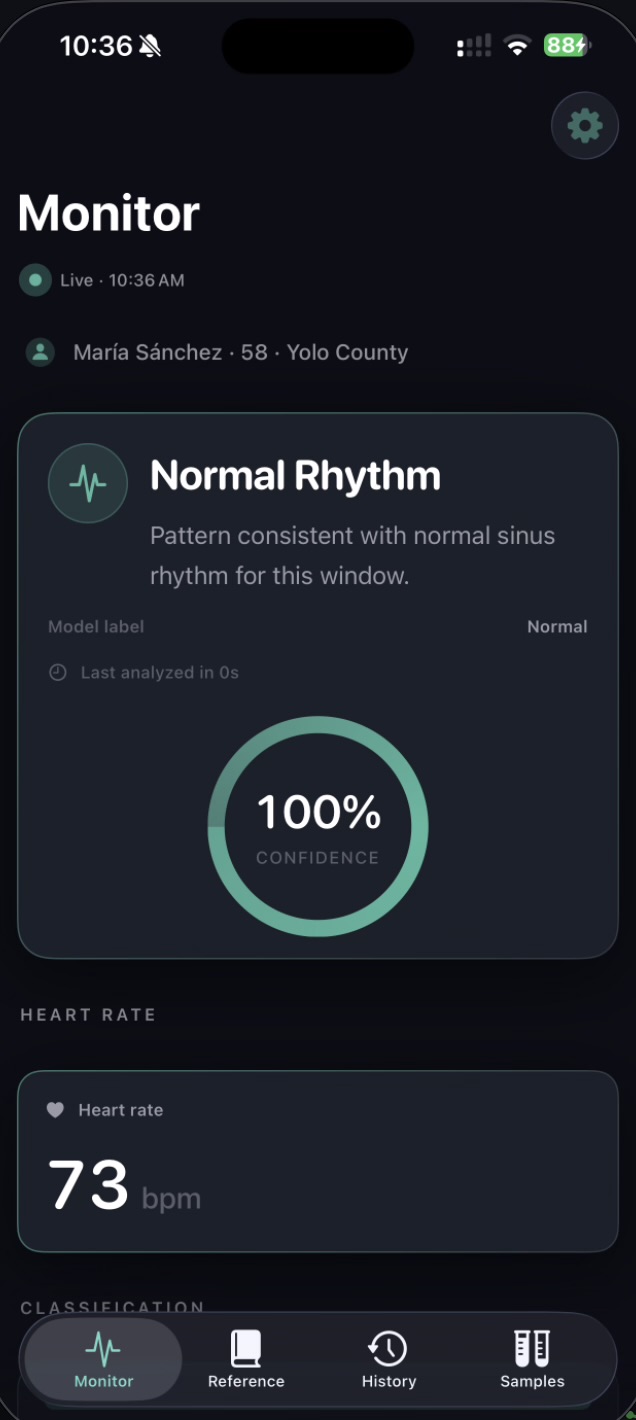
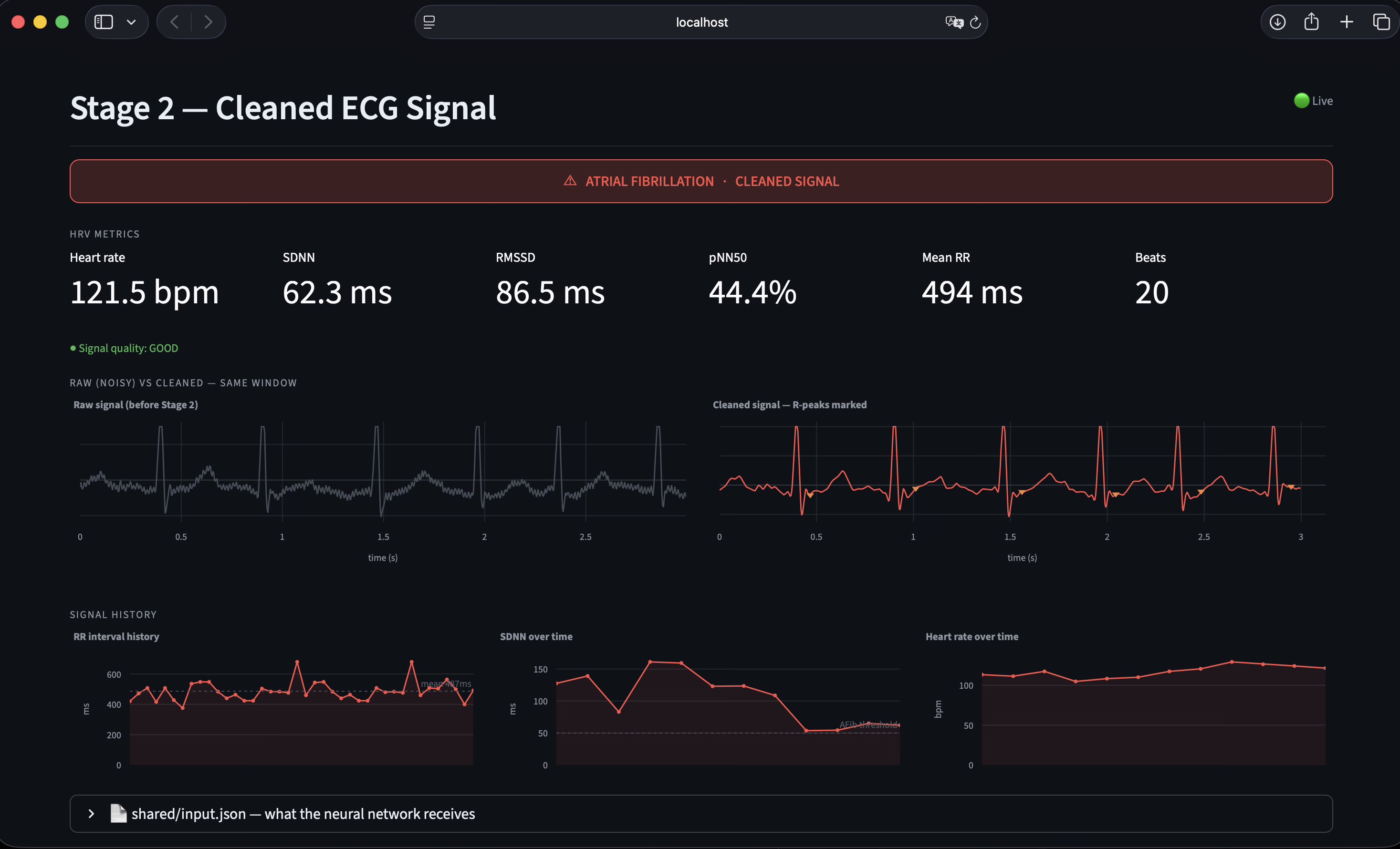
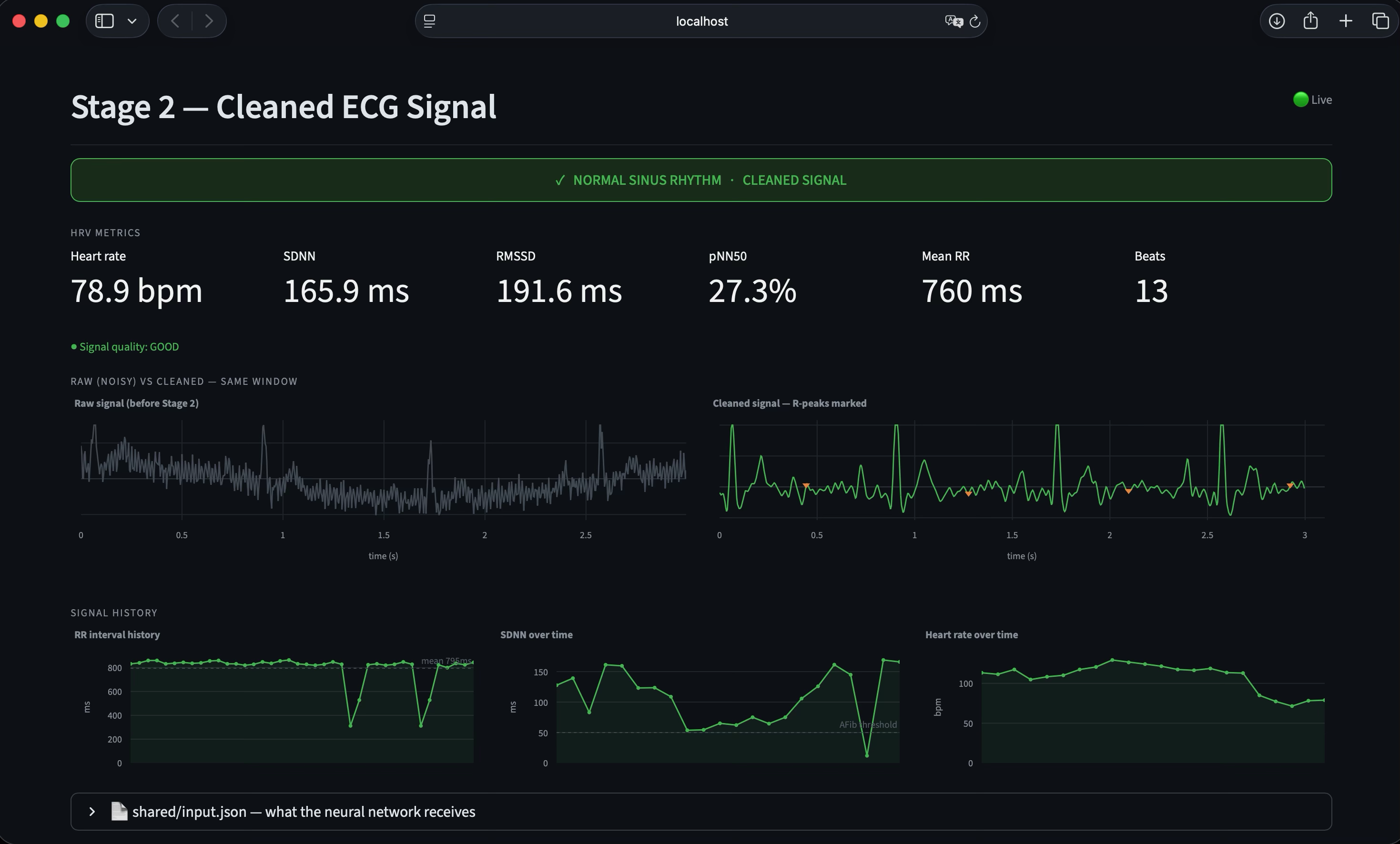
Stage 2 — Signal processing. Stage 2 applies a Butterworth bandpass filter, a 60 Hz notch filter for powerline interference, and a sliding-window baseline correction. It then performs Pan-Tompkins-style R-peak detection and computes standard heart-rate-variability metrics: RMSSD, SDNN, pNN50, and mean RR interval. The cleaned signal, R-peak indices, and RR intervals are written to a shared JSON file.
Stage 3 — Machine-learning classification. This was our primary contribution. We implemented a compact 1D Convolutional Neural Network in PyTorch, comprising 43,362 trainable parameters (approximately 200 KB on disk). The architecture consists of four convolutional blocks with progressively wider receptive fields, followed by adaptive pooling and a two-class softmax output. The input is a single ECG channel sampled at 250 Hz over a 10-second window (2,500 samples). The output is a probability distribution over Normal and Arrhythmia. End-to-end inference latency, including preprocessing and HRV computation, is approximately 10 milliseconds per window on commodity laptop hardware.
Training methodology. The model was trained on the MIT-BIH Atrial Fibrillation Database and the MIT-BIH Arrhythmia Database from PhysioNet, totaling 71 patient recordings. We constructed approximately 10,000 labelled 10-second windows after applying a per-beat purity filter to ensure label fidelity in the Normal class. Critically, train/test partitioning was performed at the patient level to prevent data leakage — the test set contains only patients the model has never seen during training. We resampled the Arrhythmia database from 360 Hz to 250 Hz to ensure rate-agnostic inference.
Performance. On 100 stratified clips from held-out patients, the model achieves 97% overall accuracy, with both Normal and Arrhythmia recall at 96%. Macro F1 is 0.91 on the full test set of 2,741 windows, exceeding the hackathon target of 85% per class. Class balance is preserved, indicating the model is not biased toward a single label.
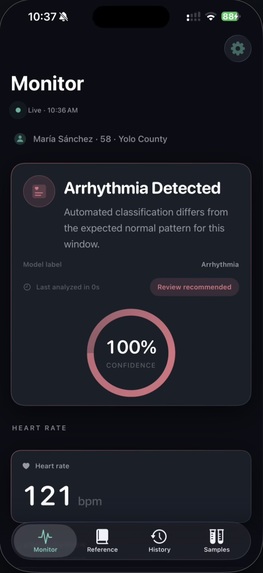
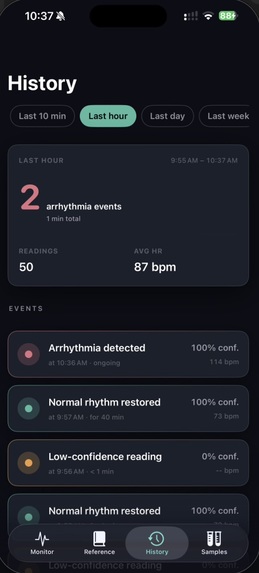
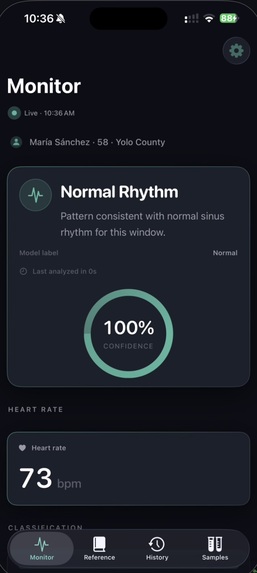
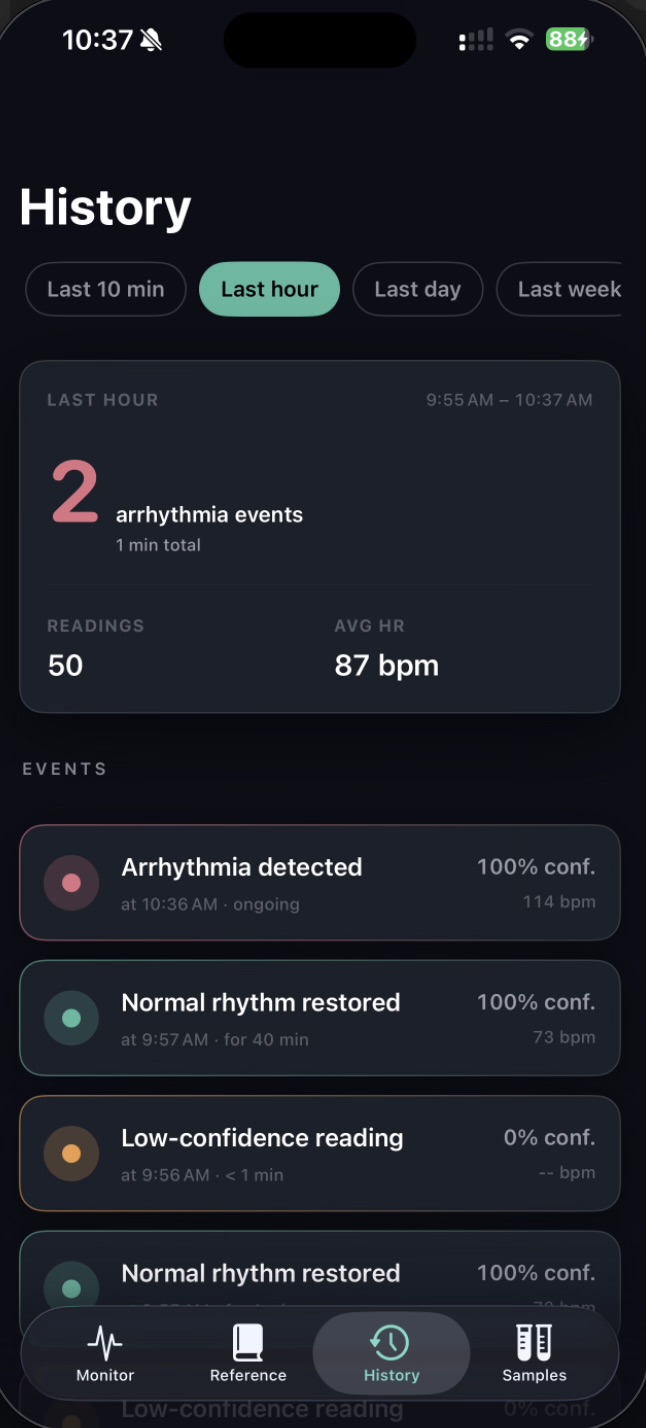
Calibrated uncertainty. A distinguishing design decision was the introduction of an explicit Uncertain runtime state. The model emits this label when softmax confidence falls below 0.60, when no R-peaks are detected, or when the input signal is flat — typically indicating electrode disconnection. The iOS app surfaces this as an amber state, distinct from the green Normal and red Arrhythmia states. This behavior reflects a clinical principle: false negatives are dangerous, but unacknowledged sensor failures are worse. The output JSON additionally exposes raw softmax probabilities, the underlying model verdict (raw_label), and a structured list of quality reasons for downstream interpretation.
Stage 4 — iOS dashboard. The iPhone client is a SwiftUI application that polls the prediction JSON over the local network every 2 seconds. It renders a color-coded status badge, the current heart rate, and the four HRV metrics. The endpoint URL is editable at runtime, allowing the app to operate on any local network without a rebuild.
Integration layer. A Python file watcher monitors the Stage 2 output, invokes the model on each new window, and writes predictions atomically (via a temporary file and os.replace) so that consumers never observe partial writes. NaN and infinity values are coerced to null before serialization. A standard Python static HTTP server delivers the prediction JSON to the iOS client. The entire pipeline is orchestrated by a single shell script that launches all four processes and cleans them up on termination.
The Challenges We Faced
Distribution mismatch in synthetic AFib data. Our initial integration test produced a paradoxical result: heart-rate-variability metrics correctly indicated atrial fibrillation (RMSSD spiked from approximately 15 ms to 200 ms), but the model continued to classify the signal as Normal with high confidence. Investigation revealed the cause: the synthetic AFib generator varied only RR intervals, while our model — trained on the MIT-BIH AFib database — had learned to rely on additional morphological markers, specifically absent P-waves and chaotic baseline f-waves, that the synthetic signal did not reproduce. We resolved this by replacing synthetic AFib generation with playback from real MIT-BIH AFib recordings, rotated across five patient records to provide variety in heart rate and morphology. The Normal path remained synthetic. After this change, AFib detection became consistently reliable in the live demo.
Label contamination in the Normal class. Combining the two MIT-BIH datasets initially caused Normal recall to collapse from 0.96 to 0.80. The root cause was a granularity mismatch: the Arrhythmia database annotates rhythms at the minute level, but a 10-second window inside a "Normal" rhythm interval may contain ectopic beats (PVCs, APCs). The model learned that windows containing ectopic morphology could still be Normal, and consequently misclassified clean Normal windows at test time. We implemented a per-beat purity filter that admits a window into the Normal class only if every beat annotation within it is a normal beat. This recovered Normal recall to 0.93 and macro F1 to 0.91.
iOS App Transport Security. Connecting the iOS client to the Mac host required navigating Apple's App Transport Security restrictions. The system blocks plain HTTP traffic by default and requires explicit per-domain exceptions in the app's Info.plist. Combined with the fact that the Mac's LAN IP changes per-network, this introduced unnecessary friction for any operator running the demo on a different Wi-Fi network. We addressed this with a runtime-editable URL field in the app and a permissive ATS configuration scoped to the demo build.
Buffer transition latency. Stage 1 maintains a 10-second rolling buffer of ECG samples. When the rhythm mode is toggled, the buffer requires approximately 10 seconds to fully refill with the new rhythm. During this transition window, the model receives a mixed signal and produces alternating predictions. We chose to document this behavior rather than mask it — the system is correctly reporting what it observes, and the brief Uncertain state during transition is a faithful representation of the underlying signal state.
Cross-machine portability. Mid-hackathon, we needed to deploy the project to a teammate's laptop. Several environment-specific issues surfaced: virtual-environment binaries contained absolute paths from the original host, the target Python version differed, the Mac LAN IP changed, and the Apple Developer signing identity required reconfiguration. We resolved these and produced a portable setup checklist that allows the project to be cloned to any macOS machine and brought to a working state in under ten minutes.
What We Learned
Calibrated honesty outweighs marginal accuracy. The introduction of the Uncertain state added almost no engineering cost but substantially changed how trustworthy the system feels in operation. For medical applications, a model that defers appropriately is more valuable than a model that is marginally more accurate but always confident.
Most apparent model failures are data failures. Each significant debugging episode in this project — the synthetic AFib distribution mismatch, the Normal label contamination, an early bandpass-band mismatch between training and inference — turned out to be a data definition issue rather than a model defect. Investigating data first, and the model second, is a discipline that paid for itself repeatedly.
Patient-level splits are essential. Random window-level splits would have produced misleadingly high accuracy that would not have generalized. Splitting at the entity level — patient, session, or device — is a non-negotiable methodological standard for medical ML and is the foundation of our 97% held-out performance.
JSON-based contracts enable parallelism. Defining the inter-stage interfaces as plain JSON before writing implementation code allowed four contributors to work concurrently without blocking. The architectural simplicity is itself a feature: it makes layers testable in isolation and replaceable without coordination.
Compact models unlock deployment. A 43,362-parameter model with 10 ms inference latency on a laptop CPU is well within the operating envelope of a wearable microcontroller. Designing for size from the outset preserves a deployment path that larger architectures would have foreclosed.
Integration is the dominant engineering cost. The model itself was among the more straightforward components of this project. The majority of hackathon hours were spent on integration concerns: file-watcher race conditions, atomic writes, network configuration, App Transport Security, dependency portability, and process orchestration. This is consistent with the pattern observed in production ML systems and reinforces the value of investing early in clean inter-component contracts.
What's Next
Several extensions are immediate. First, training on data from real wearable patch hardware will close the simulation-to-reality gap and validate generalization beyond the MIT-BIH databases. Second, expanding from binary to multi-class classification will allow detection of additional clinically significant rhythm types, including premature ventricular contractions, bundle branch blocks, and ST-segment changes. Third, conversion of the PyTorch model to Core ML will allow inference to run natively on the iPhone, eliminating the host laptop. Fourth, temperature scaling on a held-out validation set will provide formal confidence calibration. Finally, BLE integration with a physical ECG patch is the natural endpoint of the current architecture.
The long-term objective is a wrist-worn or patch-form-factor device capable of continuous arrhythmia screening without requiring a phone, a cloud connection, or a clinician in the loop — and capable of detecting the 40% of undiagnosed AFib cases before they progress to a stroke. CardioSense, in its current form, is a working scaffold for that system.





Log in or sign up for Devpost to join the conversation.