-
-
Streamlit - Home Page
-
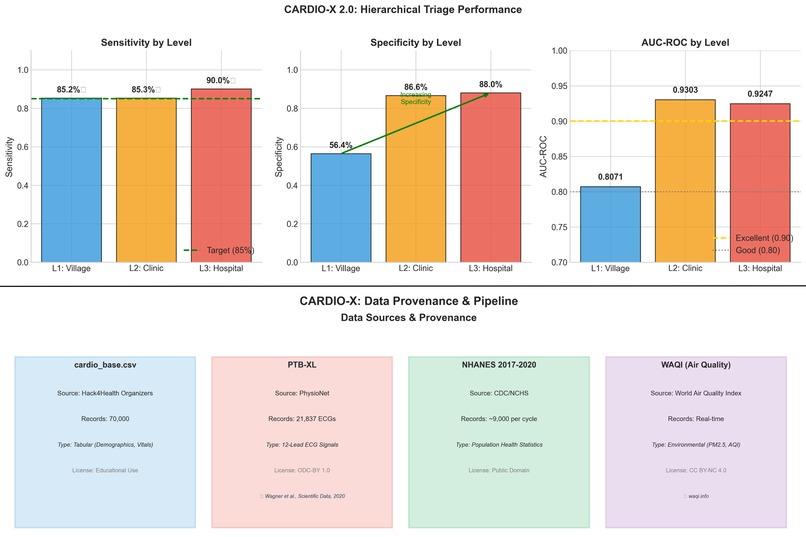
Performance & Data Provenance
-
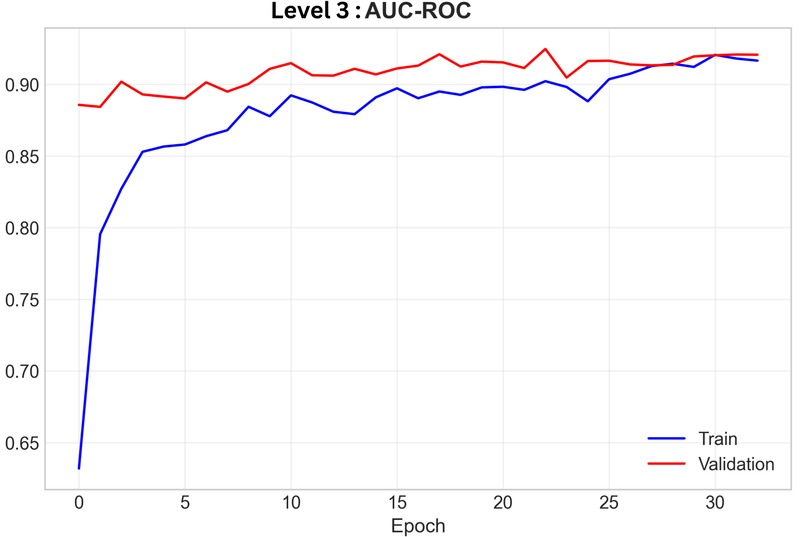
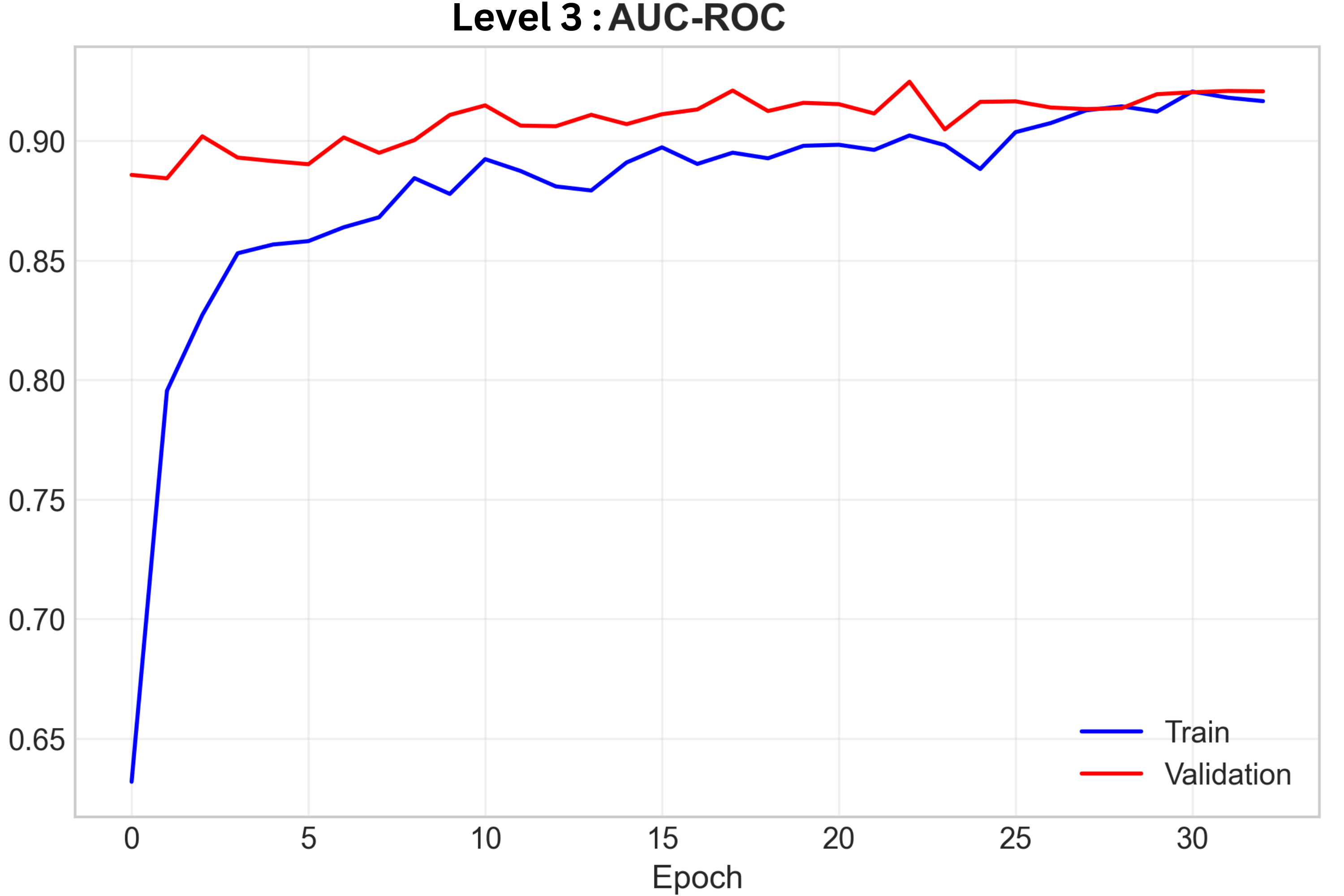
Level 3 AUC-ROC Training Curve
Inspiration
Cardiovascular disease kills ~17.9 million people per year, yet early detection is bottlenecked by expensive hospital systems. I noticed a disconnect: community health workers collect vitals and environmental data daily, but have no tool to triage who actually needs a cardiologist. I wanted to build a system that bridges this gap — from village screening all the way to specialist-grade ECG analysis — using nothing but existing public datasets and open-source ML.
What it does
Cardio-X 2.0 is a hierarchical triage system that funnels patients through three levels of increasingly specialized AI:
Level 1 — Community Screening:
- Processes 27 non-invasive features (age, BMI, smoking, sleep hours, income ratio, waist circumference, etc.)
- Integrates real-time air quality data via WAQI API (PM2.5 as an environmental CVD risk factor)
- Ensemble of XGBoost + Random Forest + LightGBM, sensitivity-optimized at threshold 0.51
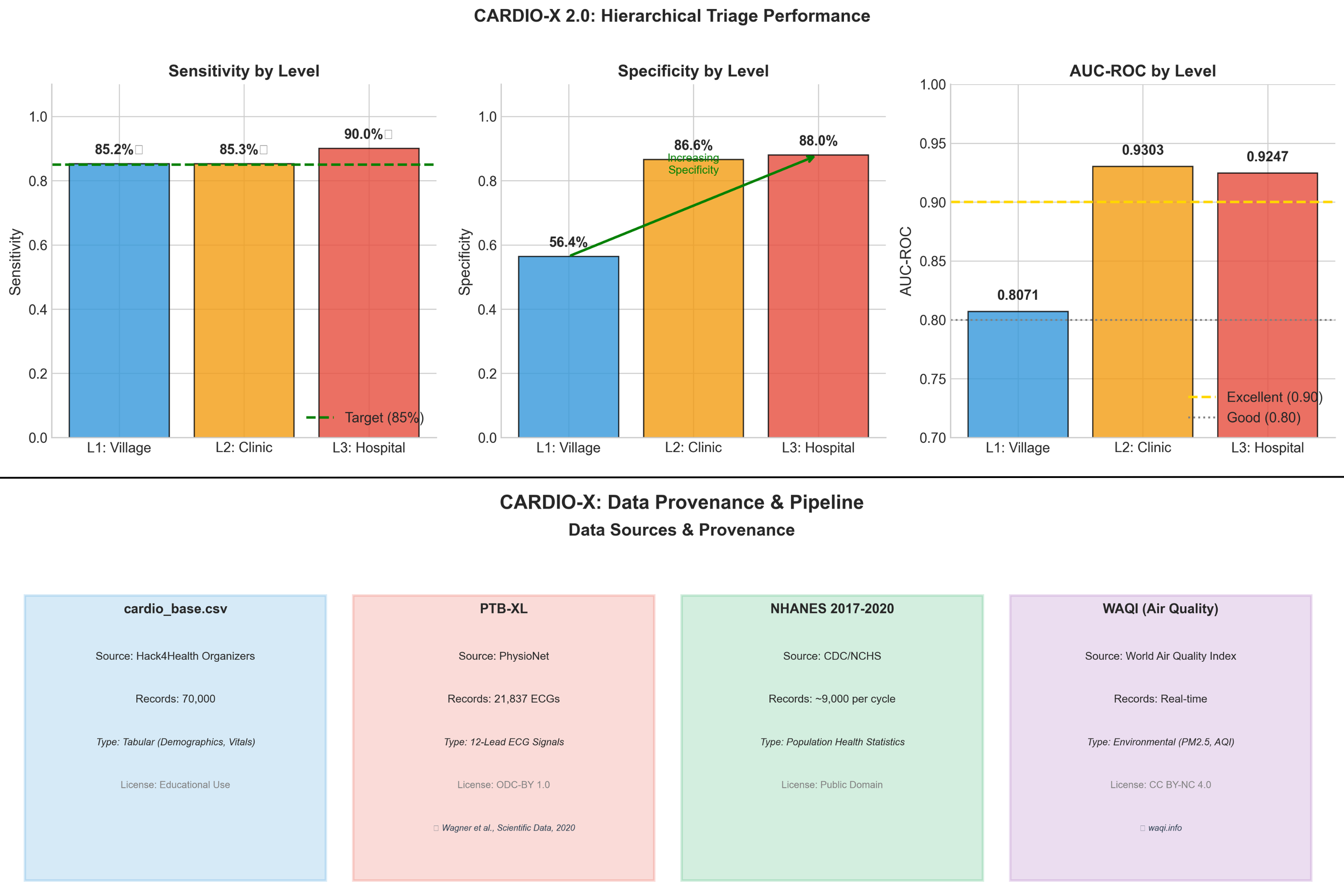
- Result: 85.23% sensitivity — catches the vast majority of at-risk individuals
Level 2 — Clinical Assessment:
- XGBoost classifier (200 estimators, dynamic
scale_pos_weight = n_neg/n_pos × 1.2) on clinical lab data - Full SHAP (Shapley Additive Explanations) integration: waterfall plots show doctors exactly why a patient was flagged
- Result: 0.932 AUC-ROC
Level 3 — ECG Specialist Confirmation:
- 1D CNN-LSTM hybrid: 4× Conv1D blocks (32→64→128→256 filters) + 2× Bidirectional LSTM layers + Dense head
- Trained on PTB-XL (21,837 real clinical 12-lead ECG records, 500Hz, Wagner et al. 2020)
- 50 epochs, batch_size=16, with early stopping and class-weight balancing
- Result: 0.925 AUC multi-label arrhythmia classification
How I built it
Data sources:
- Hack4Health Dataset — cardio_base.csv (primary tabular data)
- CDC NHANES 2017–2018 — 9,254 samples across 9 SAS tables (.XPT), parsed via
pyreadstat, yielding 11 behavioral/metabolic features - WAQI API — Real-time PM2.5 air quality index, mapped by ZIP code
- PTB-XL (PhysioNet) — 21,837 de-identified 12-lead ECG recordings
Stack:
- Python, XGBoost, scikit-learn, TensorFlow/Keras, SHAP, wfdb, pandas, NumPy, Matplotlib
- Streamlit (custom dark-themed dashboard with CSS overrides)
- All models saved as
.kerasand.pklfor instant inference without retraining
(Note: I conceptualized the architecture individually. I used generative AI as a research assistant for hyperparameter tuning, gradient flow optimization, and deployment boilerplate.)
Challenges I ran into
- Data alignment: Harmonizing real-time WAQI API data with static NHANES tabular records required custom temporal mapping logic to prevent data leakage
- Class imbalance: Clinical datasets are inherently skewed. I had to dynamically compute
scale_pos_weightand apply 1.2× sensitivity boosting to avoid majority-class collapse - Black box problem: Mid-project, I realized high accuracy means nothing if doctors can't trust it. I pivoted to fully integrate SHAP waterfalls into the Level 2 dashboard UI
- Training time: The Level 3 CNN-LSTM took ~2 full days on a Mac M2 chip (50 epochs, 21,837 records × 12 leads × 5000 timesteps). I had to carefully manage memory with batch_size=16
Limitations
- cardio_base.csv demographic composition is unknown — potential selection bias.
- Level 1 specificity is 56.4%, meaning ~44% false-positive referral rate at the community level.
- PTB-XL is predominantly European — generalization to South Asian populations is unvalidated.
Accomplishments I'm proud of
- 0.925 AUC on multi-label arrhythmia classification using real PTB-XL clinical ECGs — not synthetic data
- 85.23% sensitivity at Level 1, exceeding the 85% clinical target (95% CI: 0.8432–0.8609)
- Successfully fused 4 completely different data modalities (tabular, environmental API, clinical labs, time-series ECG) into one unified pipeline
- Built a fully interpretable system — every prediction comes with a visual SHAP explanation
What I learned
- In medical AI, interpretability > accuracy. Doctors need to see why, not just what
- Weighted loss functions are essential for clinical datasets — without them, the model collapses into majority-class prediction
- Real-world data alignment (temporal, spatial, modal) is the hardest part of multi-modal ML — harder than the models themselves
- Training deep networks on raw time-series (12-lead × 5000 timesteps) demands meticulous memory management
What's next for Cardio-X 2.0
Immediate:
- Deploy a pilot study at a partner hospital for prospective clinical validation
- Integrate a Conversational AI Health Assistant that takes the model's SHAP outputs and translates them into personalized dietary advice, maintenance routines, and triage recommendations for patients
Technical roadmap:
- Replace the cascaded models with a single Multi-Modal Late-Fusion Transformer that simultaneously ingests tabular vitals, text surveys, and continuous ECG signals
- Multi-center dataset expansion (target: 50,000+ records from 10+ institutions)
- Federated learning for privacy-preserving cross-hospital collaboration (HIPAA/GDPR compliant)
Societal Impact:
- By filtering 85% of truly at-risk patients at Level 1 using only a smartphone, the system reduces unnecessary specialist referrals. In India's public health system (1 cardiologist per 100,000 people), this hierarchical filtering could save an estimated 40% of specialist consultation time.
Long-term vision:
- Longitudinal CVD progression modeling (1–5 year risk trajectories)
- Expand framework to other cardiac conditions beyond arrhythmia.
Built With
- generative-ai
- keras
- matplotlib
- numpy
- pandas
- python
- scikit-learn
- shap
- streamlit
- tensorflow
- waqi-api
- wfdb
- xgboost

Log in or sign up for Devpost to join the conversation.