-
-
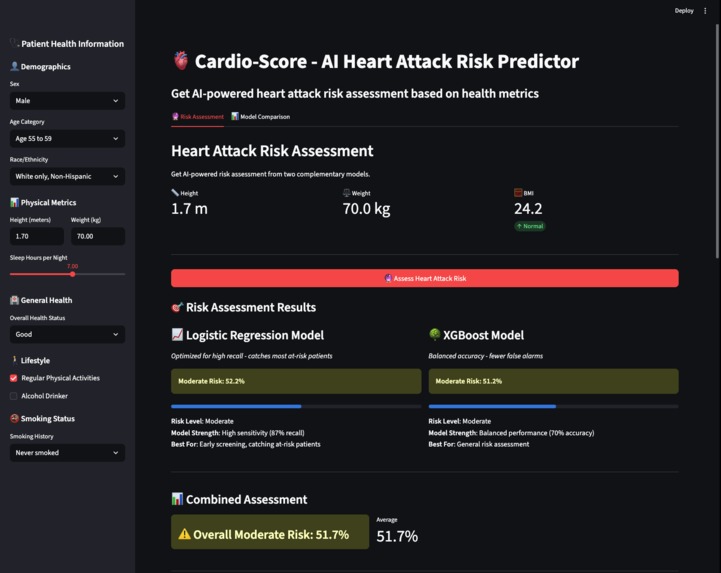
Main features with sample user data
-

LLM-generated recommendations based on user information
-

Model comparisons based on initial training
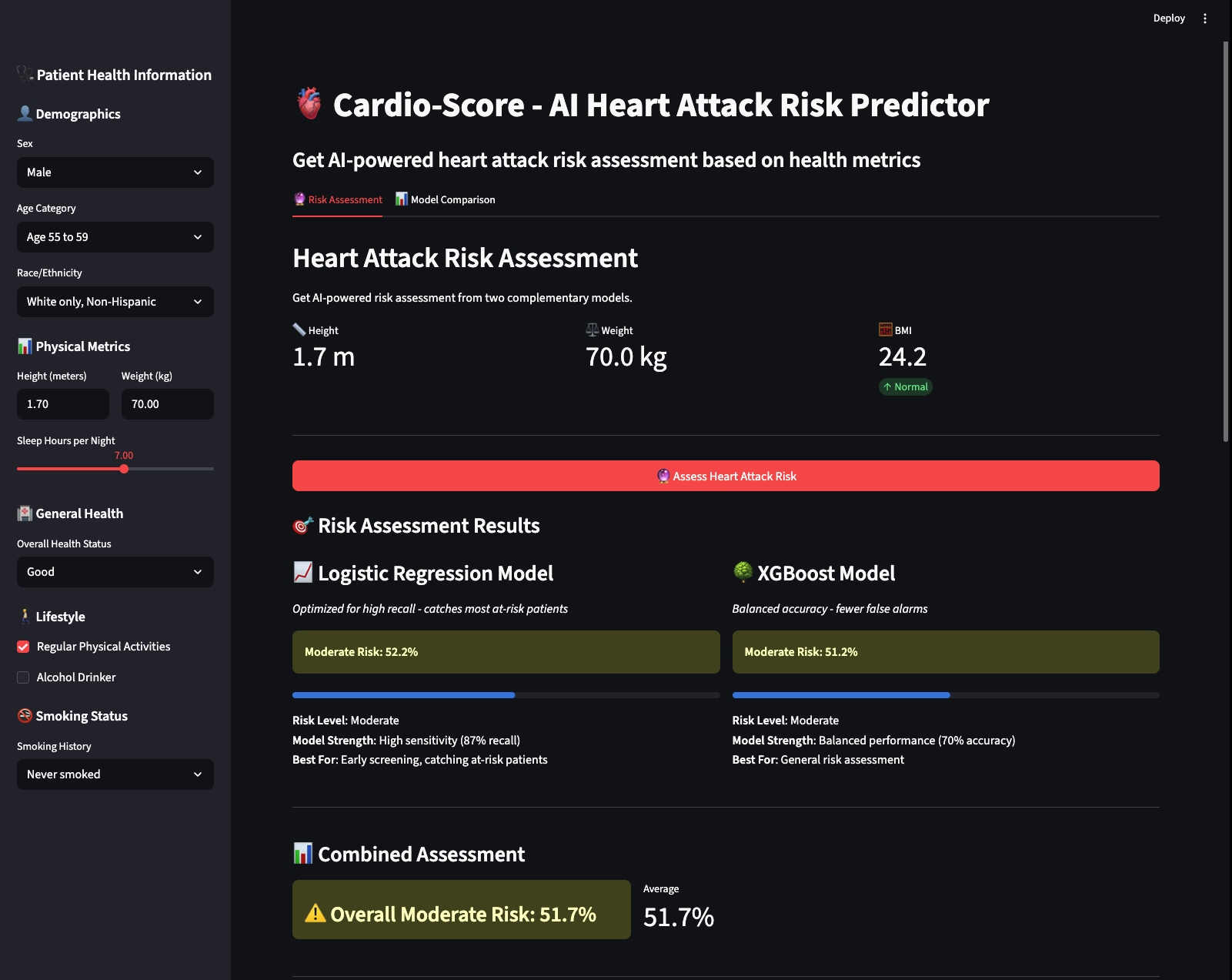


Inspiration
The hackathon's overall objective was to bridge the gap between the past and the future. We decided to target the major problem of medical diagnostics, as the Canadian medical system lacks the capacity to provide Medicare to the majority of incoming patients. The solution we have developed is a diagnostic system trained on real-world data from Medicare facilities to provide an accurate numerical probability of a heart attack.
What it does
We have specifically selected two distinct models: Logistic Regression and XGBoost. By implementing two models, we provide a dynamic range of probabilities because the models differ in how they evaluate inputs. We then developed a user-friendly interface that leverages passive data collection to create a sense of simplicity and comfort.
How we built it
We built our system using Python, Pandas, and scikit learn to preprocess data and train an AI model that predicts medical and healthcare risk as a probability-based percentage. To improve reliability and comparison, we implemented two algorithms Logistic Regression and XGBoost each producing independent risk predictions from the same inputs. We designed a complete machine learning pipeline for preprocessing, model inference, and prediction aggregation. After generating numerical risk scores, we integrated an AI-powered API that summarizes the prediction into a clear, human-readable explanation. The entire system was deployed using Streamlit, enabling live user input and real-time, explainable results.
Challenges we ran into
One of the biggest challenges was selecting the most appropriate algorithms to achieve accurate and stable results from real world data. Balancing model performance, scalability, and interpretability required careful experimentation. Implementing gradient-boosted decision trees at scale while ensuring correct precision and accuracy was particularly challenging. Tuning hyperparameters and validating results took multiple iterations. Through testing and evaluation, we were able to improve overall model accuracy and successfully compare the performance of both algorithms.
Accomplishments that we're proud of
We are proud of our deep understanding and successful implementation of both Logistic Regression and Extreme Gradient Boosting (XGBoost) models. Additionally, we successfully trained our models on a real-world dataset with over 300,000 records, producing precise and meaningful probability based risk predictions. Building a full end-to-end pipeline from raw data to live predictions was a major achievement for our team.
What we learned
Through this project, we learned how machine learning works in practice beyond theoretical coursework especially model training, fine-tuning, evaluation, and probability based outputs ranging from 0 to 1. We also gained hands-on experience building a complete ML pipeline and deploying it through a user-facing interface. Beyond technical skills, we strengthened our teamwork by practicing sprint planning, task distribution, and collaboration through structured issue tracking.
What's next for Cardio Score
To further enhance this project, we plan to train the model on a scaled version of the dataset to improve diagnostic accuracy and reliability. Additionally, fine-tuning individual attribute weights and balancing the overall data dependency may improve the model's precision. Lastly, we would like to extend the user interface to build an app that further simplifies data collection and fosters a friendly, neighbourly environment.
Built With
- numpy
- pandas
- python
- scikit-learn
- streamlit
- tensorflow

 Oh")
 Oh")
Log in or sign up for Devpost to join the conversation.