Inspiration
We wanted to do something AI-related that also contributes to helping with prevalent issues in society, especially ones highlighted by the United Nations Sustainable Development Goals. Preserving the environment is a major focus, and giving people visibility into their carbon footprint, along with simple ways to improve it, can make a meaningful impact on the health of our planet.
What it does
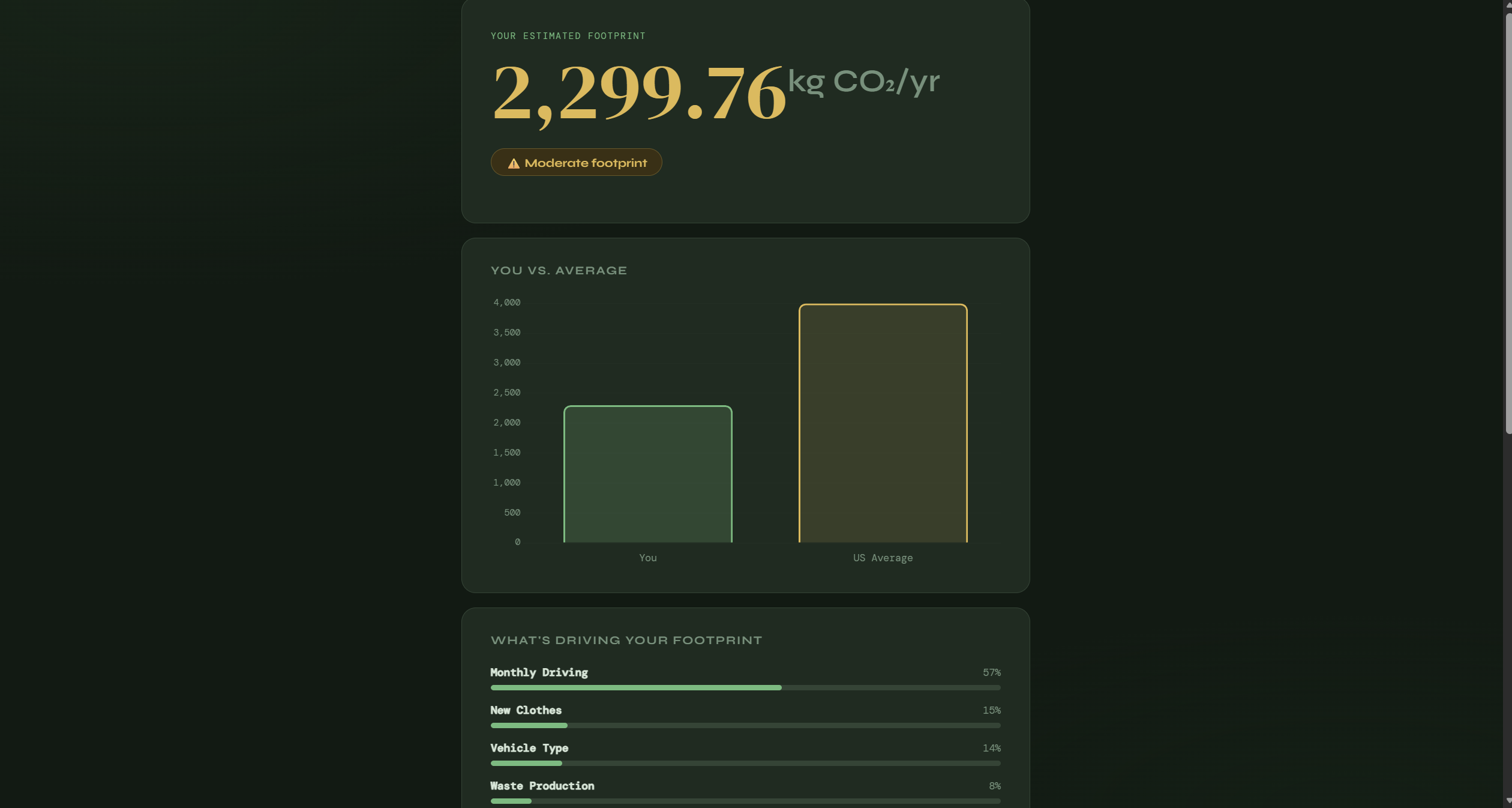
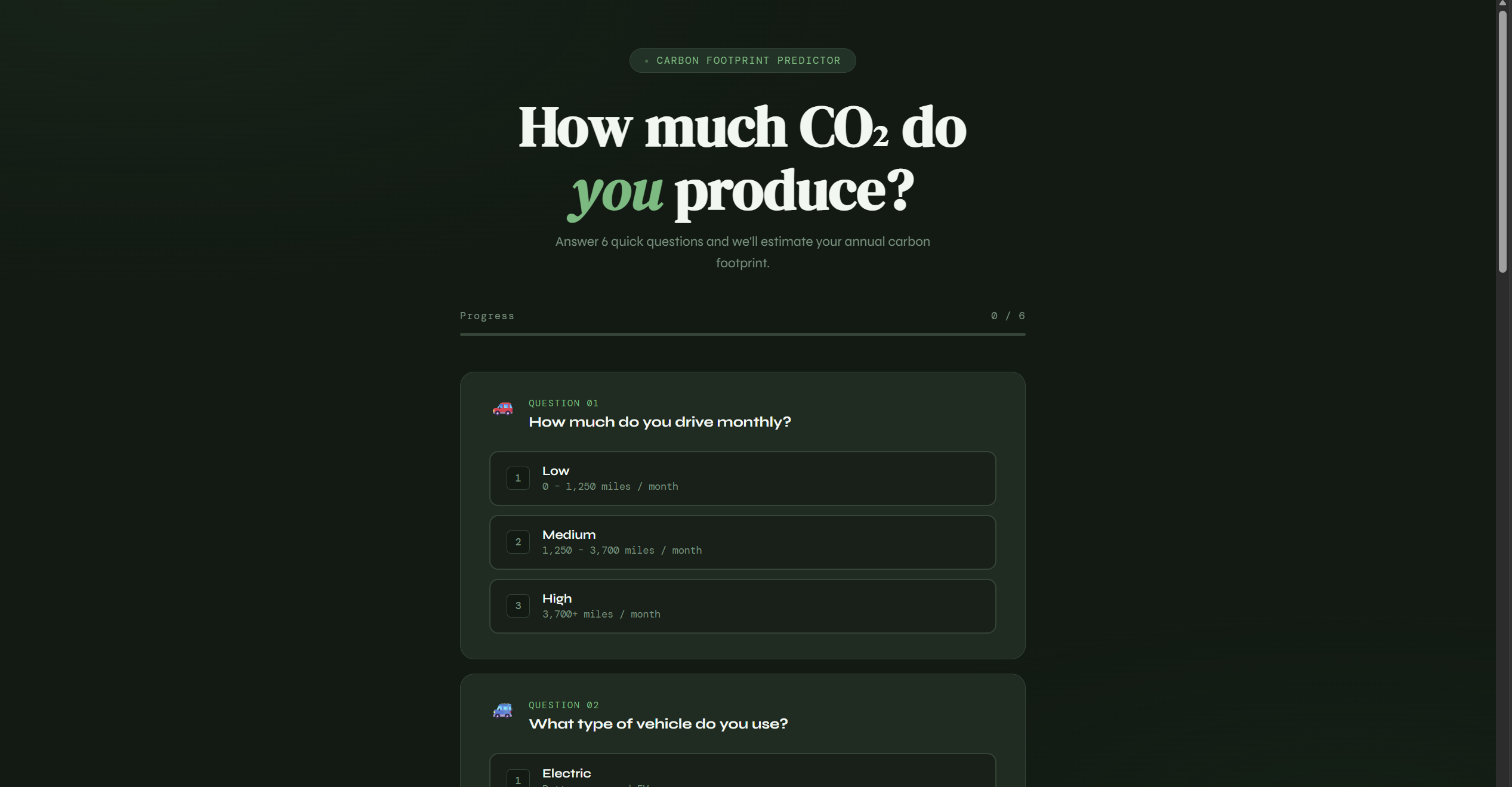
This application allows the user to input factors such as travel time, how often they dispose of trash bags, etc. (determined using machine learning models to identify the features that most affect carbon footprint). It then displays their estimated carbon footprint along with a breakdown of which habits contribute most to it.
An LLM, using the Gemini API, provides recommended actionable steps to help users strategically lower their footprint without disrupting their daily routines.
How we built it
We used Visual Studio Code with Python as our primary language, and Flask for the backend. For training our models, we used random forest regression to identify key contributing factors and predict carbon footprint based on user inputs. We sourced our dataset from Kaggle.
We leveraged Claude Code as a support tool for frontend development, helping us bridge gaps in our experience while we reviewed and refined the implementation ourselves.
Git and GitHub were used for version control, along with Git LFS (Large File Storage) to manage and store the larger model file used for predictions, since it exceeded GitHub’s standard size limits.
HTML and CSS were used for structuring and styling the frontend, and Render was used for deployment. We also used AI tools to assist with initial templating and development workflows, while making significant refinements to fit our application’s needs.
Challenges we ran into
We faced several challenges with Git, including merge conflicts and versioning issues throughout the hackathon. However, this helped us learn new tools and strategies such as Git LFS and better collaboration practices.
We also encountered inconsistencies in numerical outputs. At one point, the model and Gemini responses were not aligned (e.g., showing high vehicle usage despite selecting “No vehicle”), which required debugging and better synchronization between components.
Accomplishments that we're proud of
We are proud that we successfully trained, integrated, and deployed our model for real use.
We’re also proud of combining multiple models within a single application to enhance the user experience, while keeping the system focused and not overloaded with unnecessary features.
What we learned
We learned about fine-tuning models, handling null values in datasets, and understanding how feature importance translates into real-world insights.
We also gained experience with Git, version control, and handling POST/GET requests in Flask.
Additionally, we learned how to effectively leverage AI as a tool to support development, improve workflows, and help fill knowledge gaps when needed.
What's next for CarbonCoach
We plan to incorporate containerization tools like Docker or Kubernetes to streamline deployment and reduce latency when using trained models, an industry-standard approach for scalable ML systems.
We also want to add more data visualizations and charts to give users deeper insights into the factors influencing their carbon footprint.

Log in or sign up for Devpost to join the conversation.