Inspiration
A desire to share disparate environmental impact data in a meaningful and clear way for online shoppers at their point of sale Minimize resistance for users to reduce their environmental impact.
How we built it
- Created the website using wordpress, HTML and Javascript
- Checked some online sources for data containing values such as GHGEs per 100g median and GHGEs per 100 Kcal median.
- Used the data available online to create a sample dataset in the form of a csv file
- Performed web scraping on amazon to get the product names of the products user comes across to buy.
- Web scraping resulted in data collected in the form of a JSON file.
- Used the JSON file containing scraped data and matched the carbon emission value with respect to each product, with the csv dataset created before.
- Use the values obtained for all matched products, to display on the website to show the track record of a user’s shopping profile and carbon footprint.
What it does
Track carbon footprint of peoples groceries and compare against data from: A Drewnowski, CD Rehm, A Martin, EO Verger, M Voinnesson, P Imbert. (2014). Energy and nutrient density of foods in relation to their carbon footprint. Am J Clin Nutrition, 101(1), p: 184–191.
Some of these functions are not at full functionality, but the theoretical experience is as follows:
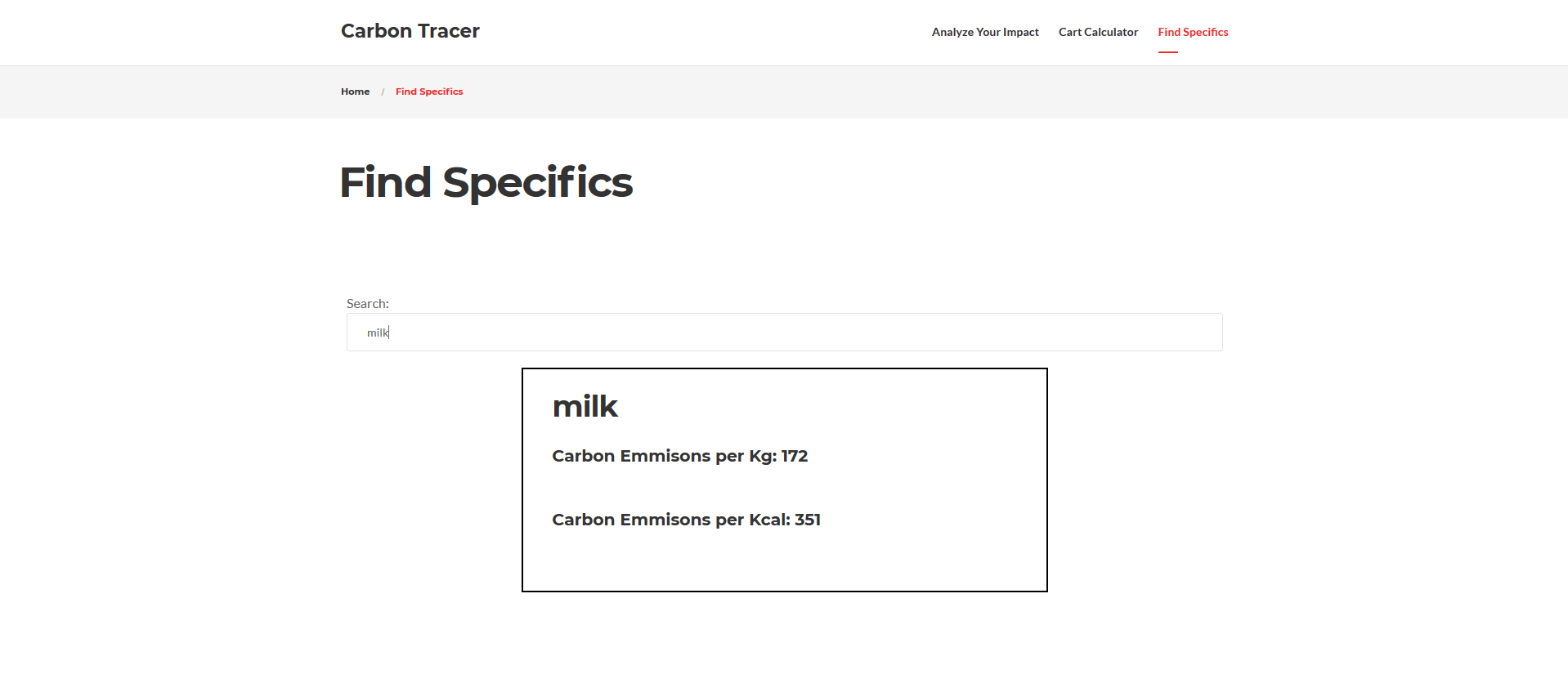
User has a shopping cart on an online website User visits Carbon Tracer webapp and clicks "crunch my numbers" This scrapes their cart page for data on all the items in the cart The cart items are compared against our carbon footprint database (read from csv and processed into json format) and the user is presented with the data for their cart. The user can search for individual items to learn more about potential greenhouse gas impacts
Challenges we ran into
We wanted to Combine our various skillsets, which include python and html/css/javascript, and find a way to bridge those in different parts of our data gathering and sharing process. This may have been a rather roundabout process that stacked up many challenges of translating data between python, json, and Wordpress.
Our webpage scraper also proved tricky, in large part because we were aiming for the ability to read cart pages that involve user login. Such sites were usually secure and thus made it much harder for a third party to read data.
It was a comedy of workarounds!
Accomplishments that we're proud of
Although we were not able to accomplish our final goal of creating a plugin, even when we started with little knowledge about the programming languages we used, we were able to create a website and a web scraper to calculate the carbon footprint of a customer trying to buy products on an online store. We did our research on what exactly should we be implementing and have a solution that we can further enhance to achieve what we planned for. This project has just started and we’re proud to give it such a wonderful start with the whole idea of how to go ahead and how it will we helpful in creating a sustainable environment.
Each individual step where we were able to connect different parts of our process, and get those parts working, was a small victory, and those were numerous!
What we learned
We learned a lot during the entire hackathon as all of us were new to the technology we were trying to implement. All four of us come from different backgrounds and experiences. We learned how to leverage the potential of each person in the team to bring out the best collaboratively. Following are the technical skills we incorporated:
- Use of HTML and Javascript for front-end development
- WordPress is an online, open source website creation tool written in PHP. We learned to use this tool for our website creation, including integrating themes, theme builders, and custom html/css/js and more
- Running python via wordpress php, and writing json to be read by javascript previously enqueued in wordpress
- Working with csv and JSON files for data storage and retrieval. We used these for their ease of use. This can be replaced with database implementation when we want to increase the amount of data.
- How and why web scraping is used to scrap data from websites. There are various tools available to scrape data. We tried to create a scraper using BeautifulSoup and requests module of Python.
- Web scraping, also called web data mining or web harvesting, is the process of constructing an agent which can extract, parse, download and organize useful information from the web automatically.
- We learned how to implement a web scraper by handling session and cookies in order to do scrapping for websites that require login.
- We learned how to use amazon’s Product Advertisement API to fetch various product details like names, reviews, prices, availability, etc. from
- Ultimately, we integrated each part of our implementation including website, scraper and data to create a plugin prototype for carbon tracer in online grocery shopping. This plugin would show a customer the carbon footprint value of all items together in the customer’s shopping cart. With this value customer can decide which products to buy or not to buy considering what impact their shopping would create on the environment.
What's next for Carbon Tracers
We envision broad and flexible expansions for our Carbon Tracer project. First and foremost would be acquiring a more comprehensive database of consumer items and greenhouse gas (GHG) emissions associated with production of the item.
Next, we will greatly increase the cross-platform integration and reduce the barrier to entry for users by adapting the cart selection scraper into a browser extension capable of easily collecting product information. The extension would be launched by the user while working within the online vendor of choice, and will allow access on secure user accounts, allowing this to expand to websites such as Amazon that dominant the online shopping world. We also envision the possibility to be incorporated in physical stores, such as new Amazon popup stores to allow real-time reports of the environmental impact of items and potential alternatives with lower footprints.
UX-wise, we hope to expand far beyond a single carbon footprint metric. Ideally, users will see that stat broken down into supplier and distributor components so they can gain a more robust understanding of their part in the product-sourcing process. They will receive automatic suggestions and comparisons for each individual product so they can easily adjust individual elements of their overall footprint. We intend to include a focus on social impacts for the communities where ingredients are produced, and provide human explanations of the production and distribution practices so users have the tools they need to become more conscious of their impact.

Log in or sign up for Devpost to join the conversation.