Inspiration
I wanted to a create a project on my own where I implemented most of the deep learning theory concepts in Deeplearning.ai specialization. I also wanted to learn to read and implement papers. This is how I ended up working on implementing this project. Also, this can be extended to video captioning or enhanced to support blind people.
What it does
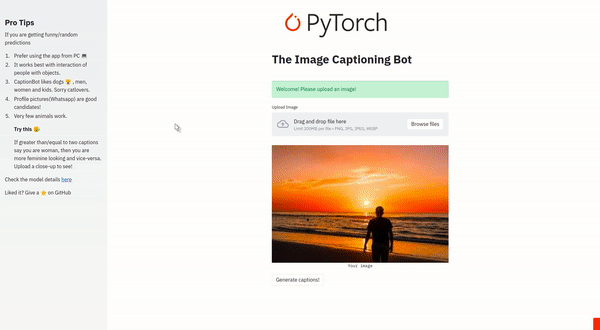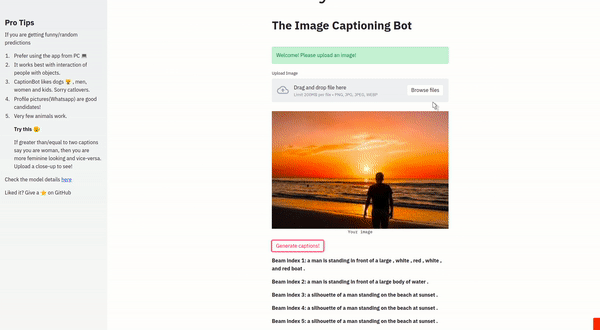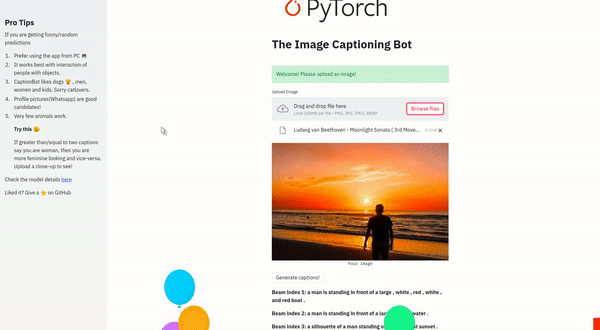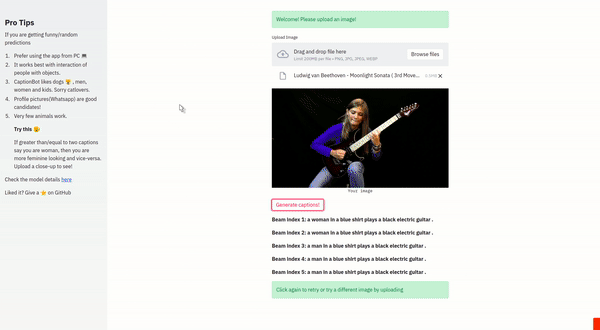
Takes an image. Analyzes the image and then provide captions describing what is happening in the image. It is a Seq2Seq based Image Captioning system with attention mechanism
How I built it
It is the implementation of the research paper "Show, Attend and Tell". Used Pytorch, spaCy, torchtext, torchvision to implement it.
- Used Resnet-50 as encoder to extract the features to send into attention network
- Decoder uses LSTM with soft-attention mechanism and Beam Search
- Trained on Flickr30K dataset with 31,783 images and 158,915 captions
- Implemented using Pytorch DL framework and deployed using Streamlit
- Achieved results close to the actual paper with BLEU1 : 59.2 and BLEU4 : 19.56
Challenges we ran into
- Interpreting and implementing using the mathematical notation in the research paper "Show, Attend and Tell"
- Thousands of bugs during training and initially making the codebase
- Keeping the size of weights low so as to deploy using the free credits/memory provided by Streamlit
- Figuring out how to download the weights in background
- Figuring out how to deploy on Streamlit
- Implementing beam search was very hard
An anecdote
The first deployed model was giving correct predictions but every time gave different captions. Now it is a deterministic model and not a randomized model and input does not modfiy the model so output should be the same each time. So after a week of thinking in the background, reading on forums, I found that this was happening because I was not saving pretrained resnet weights. I thought that it's pretrained so no need to save but actually, even in pretrained models, the batch norm still tracks mean,median for each batch.
So i trained the whole model again with this correction. Then I thought of making it bigger and trained on Flickr30K. And then I deployed it. That's how the name CaptionBot v2 comes
Accomplishments that I am proud of
I am really proud that I was able to implement the paper fully of course with the help of several other resources which can be found in the reference section of the README.
What I learnt
- Strengthening of deep learning concepts and got better at using Pytorch
- Using attention network, LSTM, transfer learning, feature extraction
- Being able to understand the research paper notation and able to implement it
- Gain more understanding of basic NLP and Computer Vision
- Patience and Perseverance is the key
What's next for CaptionBotv2
Maybe try on a larger dataset or using Transformers + CNN.



Log in or sign up for Devpost to join the conversation.