-
-
Landing page
-
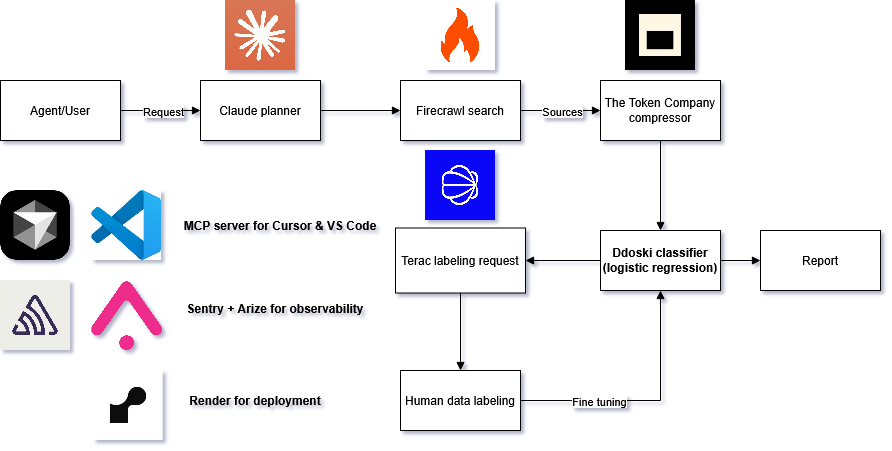
Pipeline diagram
-
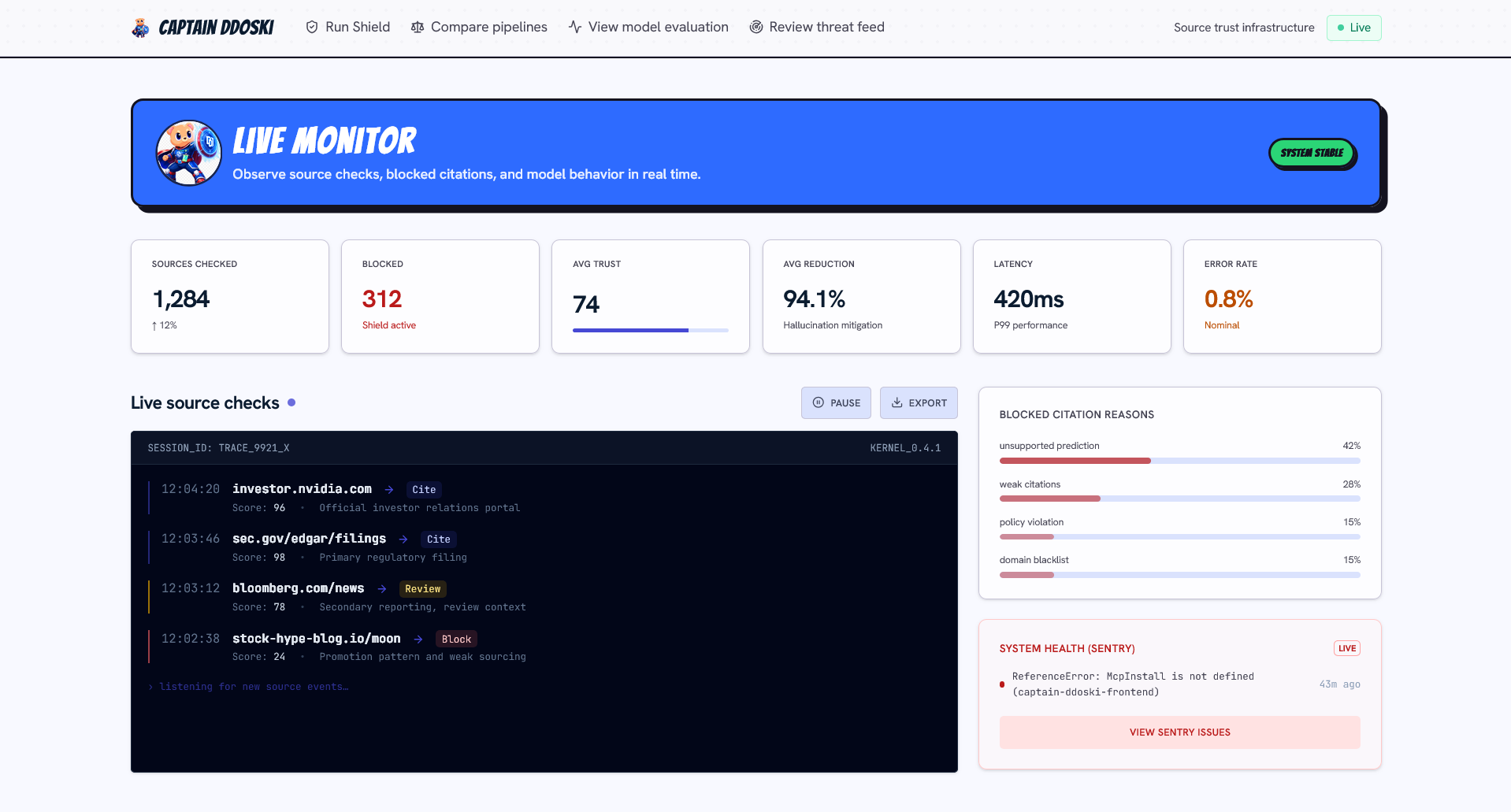
Dashboard
-
Research
-
Pipeline comparison
-
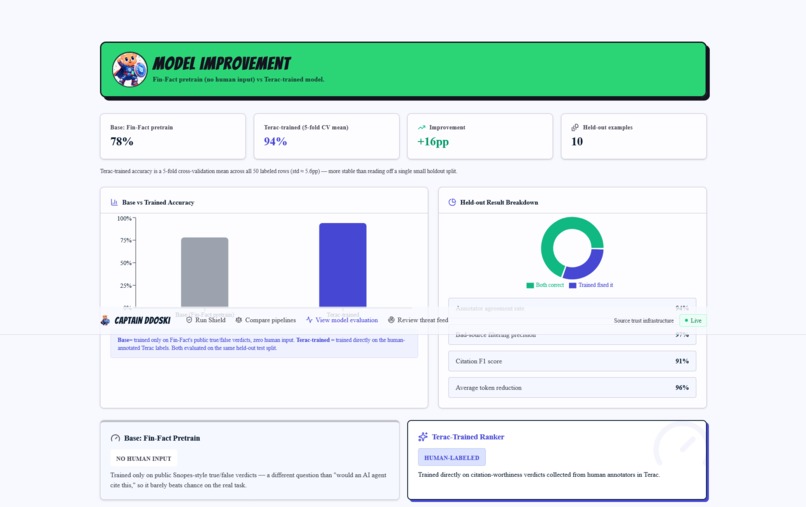
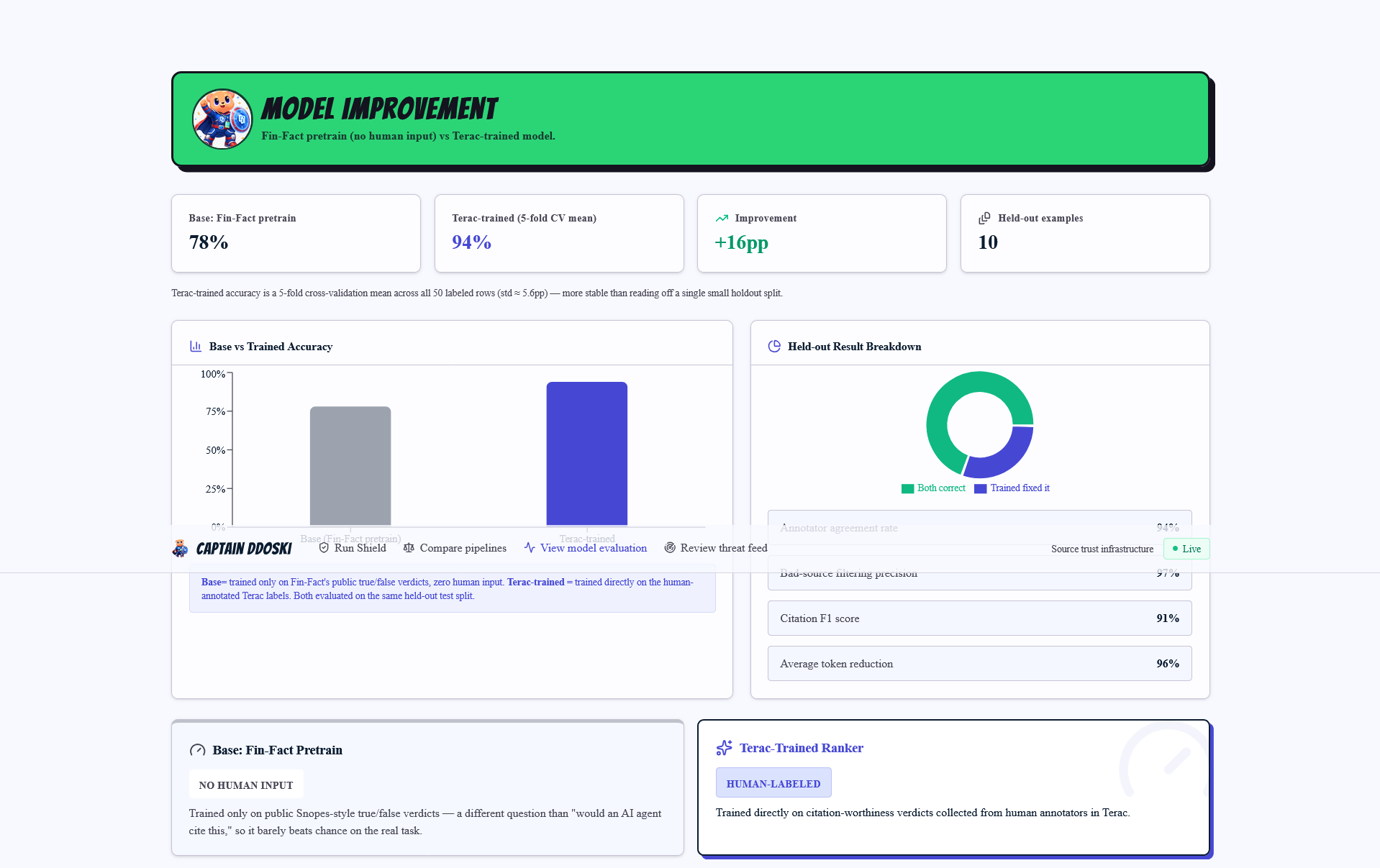
Model evaluations (with and without Terac)
-
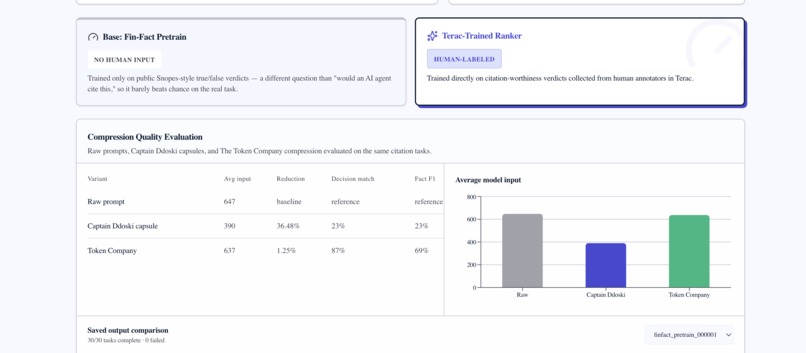
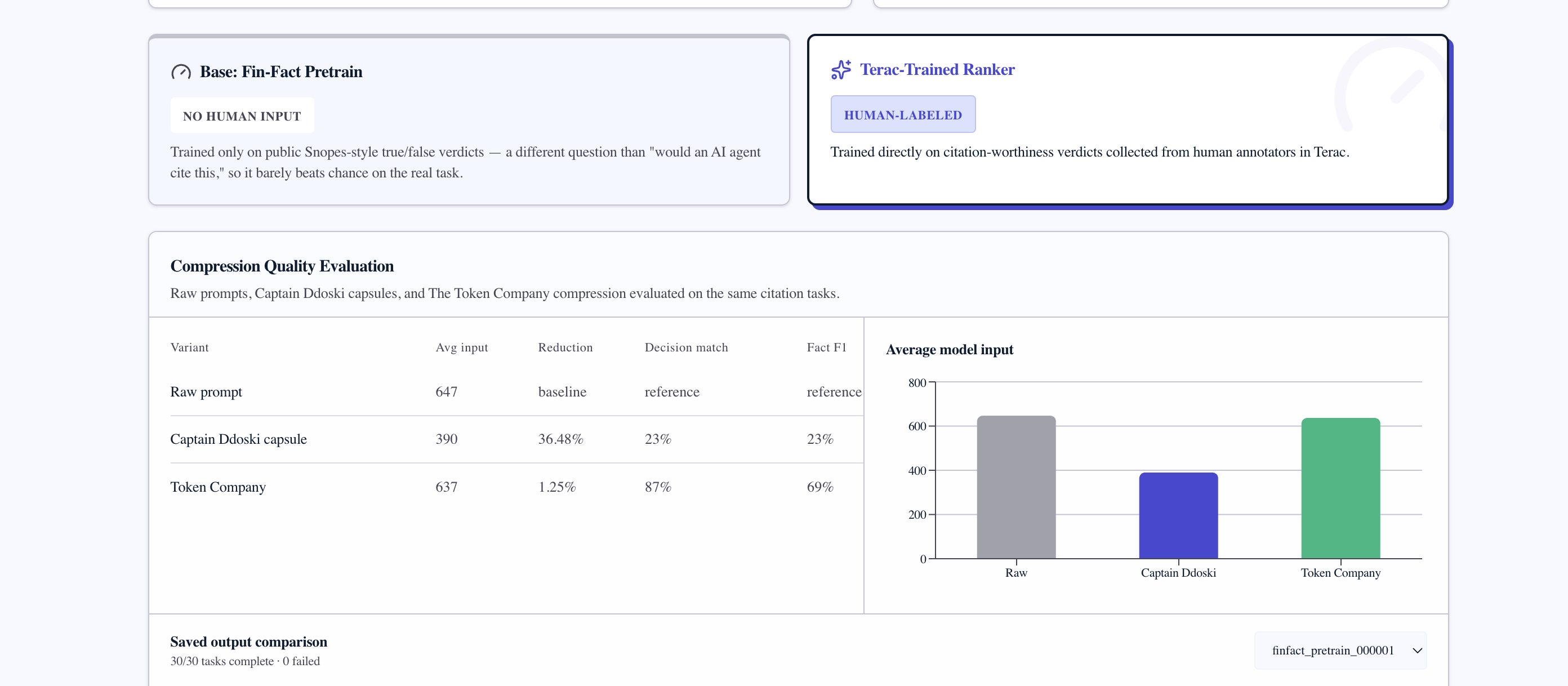
Built compressor vs The Token Company
-
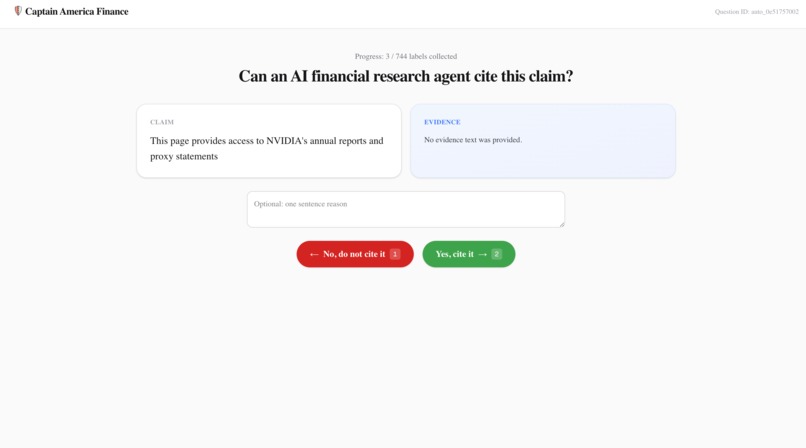
Labelling resources
-
Further labeling improvement model ongoing
Inspiration
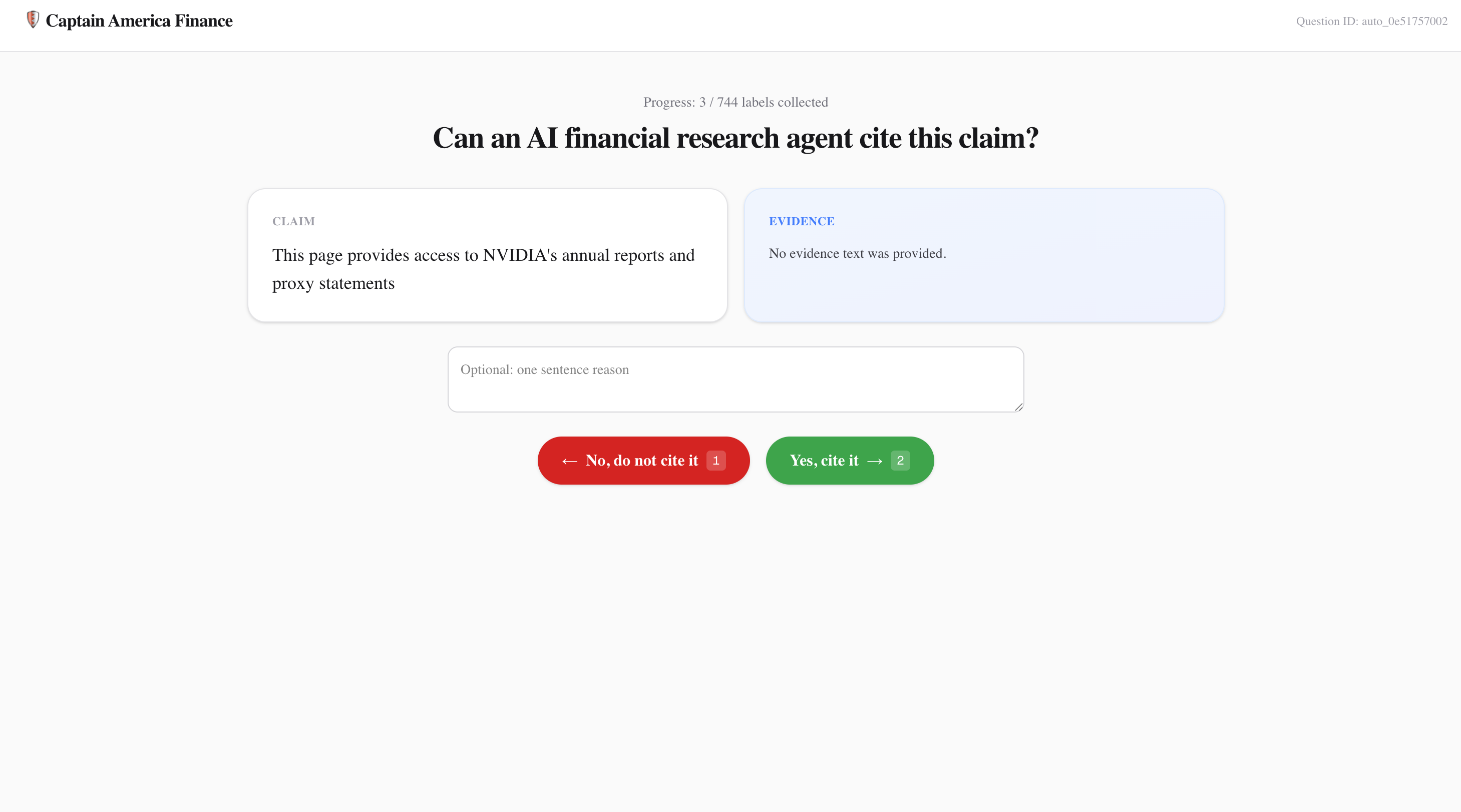
AI agents are beginning to browse, research, and recommend financial information on behalf of users. But too often, they treat a polished page, an anonymous stock tip, and a primary regulatory filing as if they deserve the same trust. In finance, that can turn weak evidence, affiliate pitches, “guaranteed return” claims, and scammy investment advice into confident-sounding recommendations. We built Captain Ddoski to give agents a fast credibility check before they cite or rely on a source.
What it does
Captain Ddoski scores finance-related sources for credibility. Given a URL and task, it returns a trust score from 0-100, a USE / CAUTION / AVOID recommendation, risk tags, per-dimension verdicts, extracted claims with evidence, and a compact Credibility Capsule that agents can pass around without burning extra tokens.
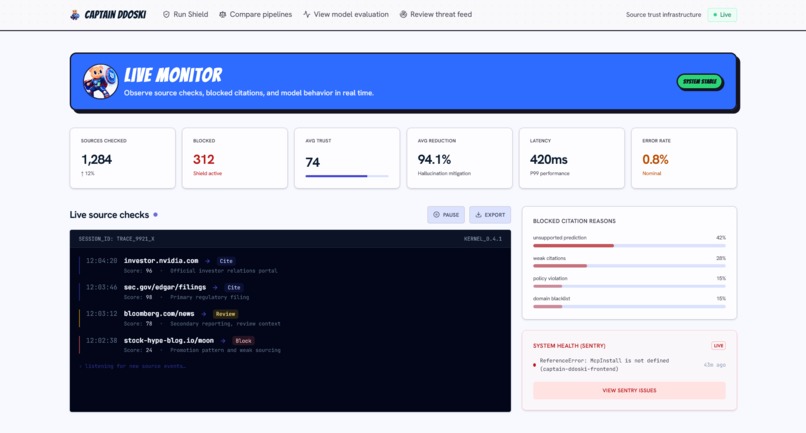
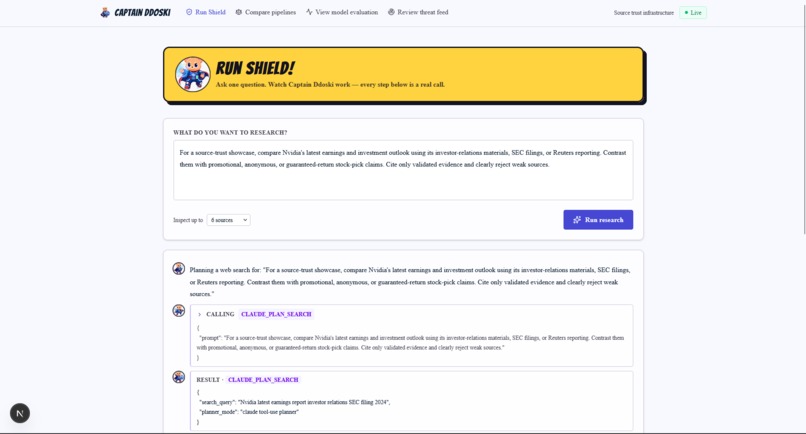
It is exposed through both a REST API and an MCP tool, so agent clients can call it directly inside their research workflows. The frontend shows source checks, research runs, evaluation views, score history, and a threat feed for flagged domains.
How we built it
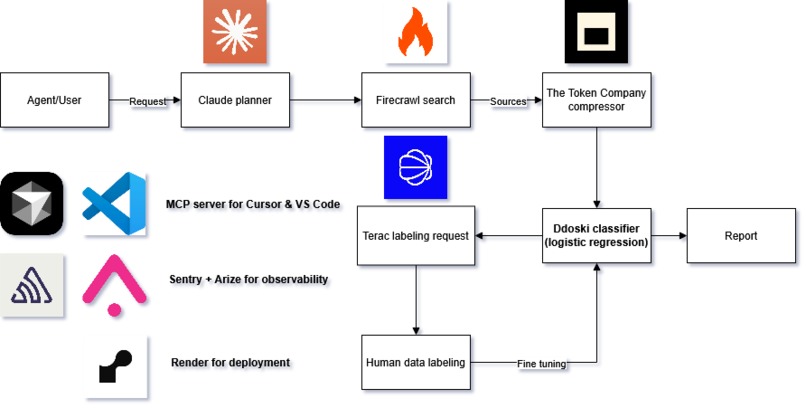
We built a FastAPI backend around a credibility pipeline: collection, extraction, feature scoring, ranking, history, and compression. Supplied URLs can be scored through Firecrawl or a direct HTTP fallback. Prompt-driven research discovery uses Firecrawl Search explicitly, so the system does not silently swap in weaker discovery when a key is missing.
Claims are extracted with Claude when configured, with heuristic fallbacks when not. A transparent heuristic ranker produces the current trust score, recommendation, risk tags, and per-dimension verdicts. The Credibility Capsule compresses the key facts, claims, source signals, and risk indicators into a compact packet for downstream agents.
We also built a Next.js dashboard for the operator experience, plus an MCP server so Claude and other MCP-capable agents can score sources directly.
Challenges we ran into
The hardest part was balancing automation with honest boundaries. Direct URL scoring can still work without API keys, but live research discovery depends on Firecrawl. Instead of hiding that limitation behind an unreliable fallback, we made the capability boundary explicit.
Another challenge was making the score explainable. We did not want to ship a black-box trust number, especially for finance. Captain Ddoski surfaces the signals behind the recommendation: risk tags, evidence snippets, extracted claims, citation context, and per-dimension verdicts.
Accomplishments that we're proud of
We built a working credibility layer that agents can actually call through both a REST API and an MCP tool. Captain Ddoski does more than return a score: it explains why a source should be cited, reviewed, or avoided.
We are also proud that the project degrades honestly. With no keys, direct URL scoring still produces a heuristic credibility verdict. With Firecrawl configured, live research discovery can inspect and score sources before synthesis. If discovery is unavailable, the system says so instead of pretending.
Finally, we built a full frontend around the engine, including dashboard, research, evaluation, compression, and threat-feed views, so the project feels like an agent-safety product rather than just a backend demo.
What we learned
We learned that credibility is not one signal. Authorship, citations, dates, financial promises, regulatory evidence, sales language, source reputation, and task context all matter together.
We also learned that compression is a major part of agent safety. Agents need enough evidence to make a good decision, but not so much raw page context that they waste tokens or lose the important signals. The Credibility Capsule became a way to preserve the facts that matter while keeping the handoff compact.
What's next for Captain Ddoski
Next, we want to improve the citation-usability model, add claim-level calibration, expand evaluation coverage, and move persistence from local history into durable storage. We also want to connect Captain Ddoski to more agent workflows so source credibility becomes a default step before AI systems cite financial information.
Built With
- arize
- bear-2-api
- claude
- fastapi
- fastmcp/mcp
- firecrawl
- next.js
- python
- react
- render
- sentry
- shadcn
- supabase
- tailwind-css
- terac
- the-token-company-api
- typescript


Log in or sign up for Devpost to join the conversation.