Inspiration
The idea came to me during finals season as I found myself pulling late nights and wondering if I was drinking too much coffee to maximize my studying, or not enough!
Cappugeno is a simple AI assistant designed to easily plan out or understand your caffeine intake based on your genetic information. It links directly to your Google account, meaning you can talk to Cappugeno from your phone, computer, or Google Home!
What it does
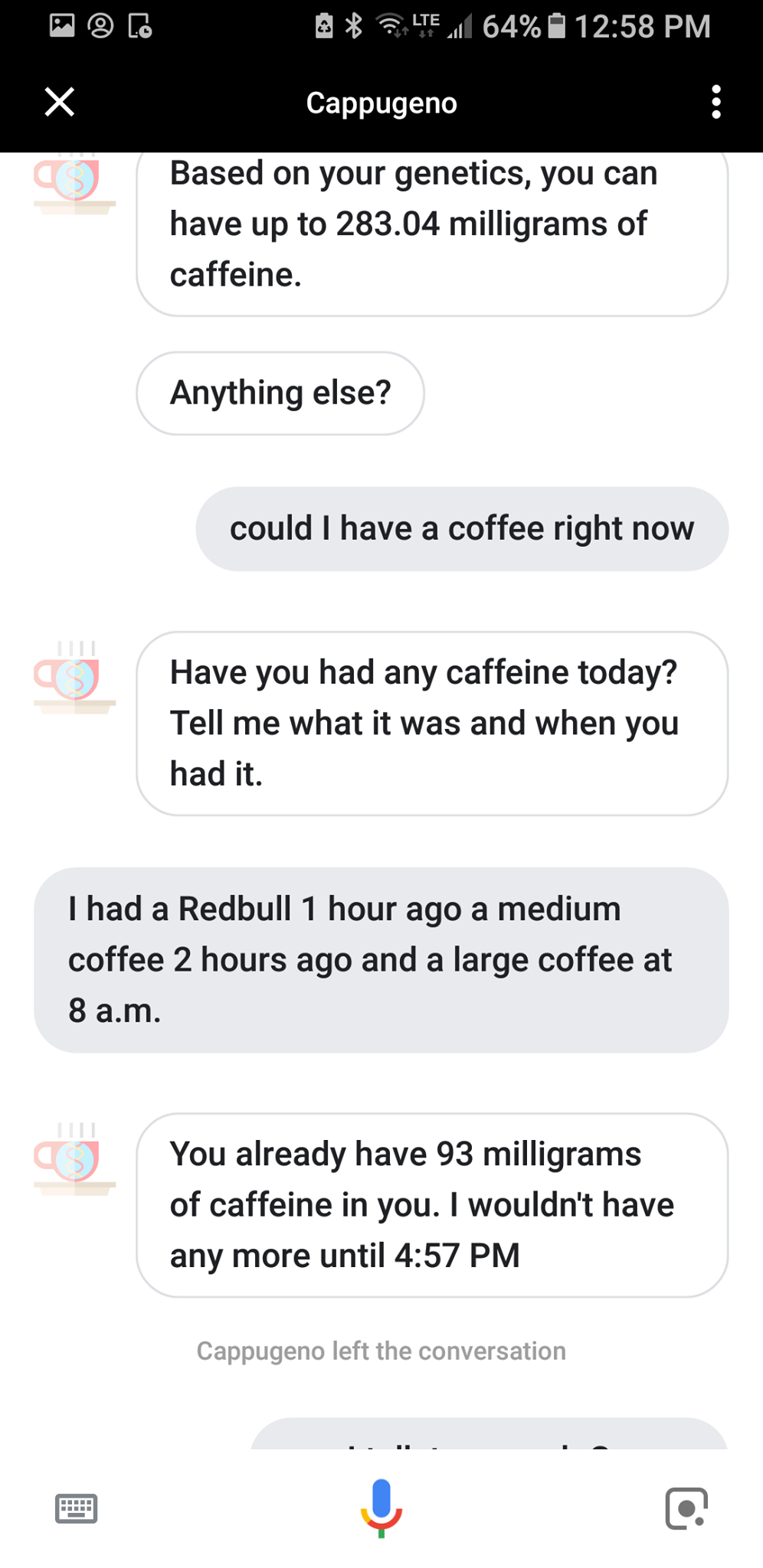
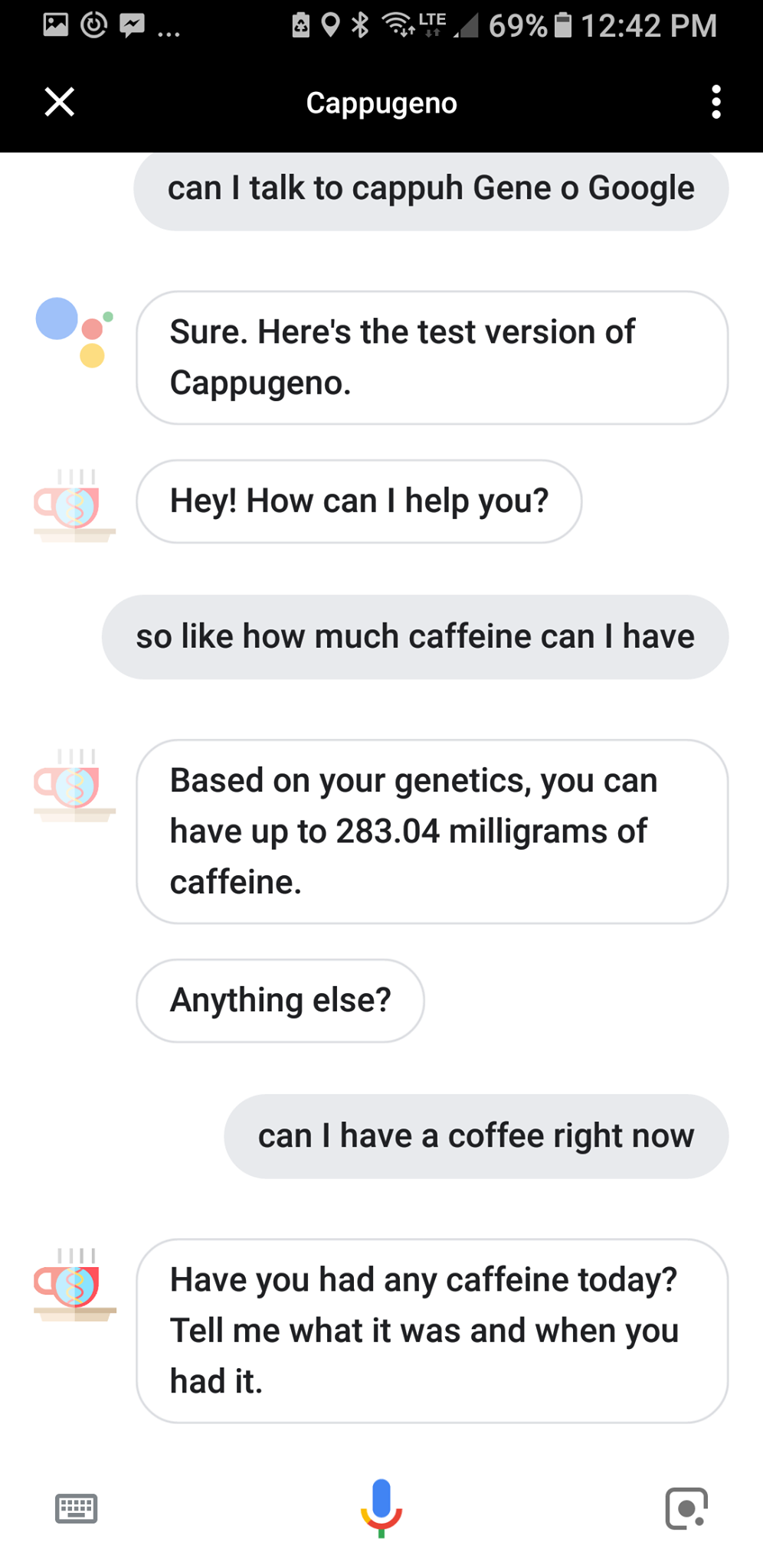
The goal with Cappugeno is to allow people to simply list off caffeinated drinks and a general idea of when they had them in natural language, figure out how much caffeine has already been metabolized based on their genetics, and tell them if that extra coffee really is such a good idea.
As well, Cappugeno acts as your personal assistant to answer questions on what your caffeine limit is, so unlike a real cappuccino, it's not just all froth and no substance.
How I built it
Frontend: Javascript using Dialogflow/Actions on Google
Website: Python/Django/HTML/Javascript
Backend: Firebase Cloud Functions/Realtime Database, Genomelink API
To accomplish all these goals, I employed Actions on Google with Dialogflow to train a chatbot using ML. It needed to be able to figure out what kinds of coffee the user was having (ex "large iced coffee") and when ("at noon"/"an hour ago"/"8:00 PM").
I used Firebase Cloud Functions with Javascript to actually write the chatbot, and Python/Django/HTML to serve as a website for you to login to to see your stats and grant access to your DNA. The info is stored with Firebase's Realtime Database.
Challenges I ran into
Originally I actually envisioned this as an app, before realizing it could be much more intuitive and simplistic as an AI assistant.
Figuring out how OAuth worked was probably the most challenging thing I ran into - it was actually pretty straightforward after the learning curve!
Accomplishments that I'm proud of
I'm probably most proud of the half-life calculations that allow the user to list off using natural language all the caffeinated drinks they've consumed over the day and have that converted into a numeric value.
What I learned
I found out a ton about OAuth, how to work with both Dialogflow and Firebase, and about how your genetics affect how you metabolize different substances. I could definitely say I learned a "latte".
What's next for Cappugeno
I'd love to find more studies (or do them?) to more accurately connect caffeine metabolic ratio, caffeine consumption and excessive daytime sleepiness pulled from Genomelink to exact values. If I deployed this, I could compare user feedback alongside tensorflow to increase accuracy even more.




Log in or sign up for Devpost to join the conversation.