-
-
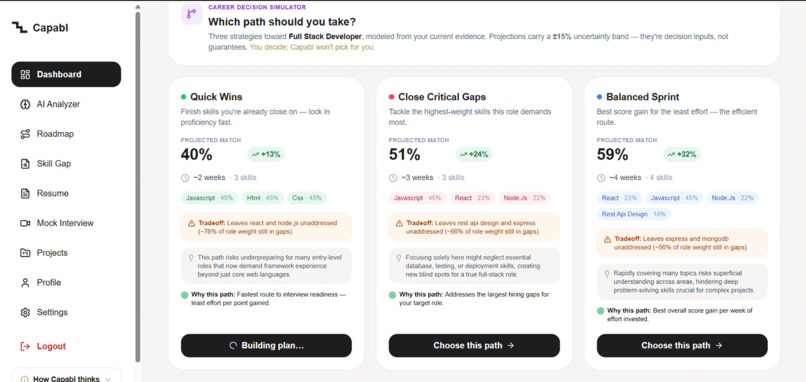
Three strategies, each with its tradeoff + a ±15% band. You decide—Capabl won't pick for you.
-
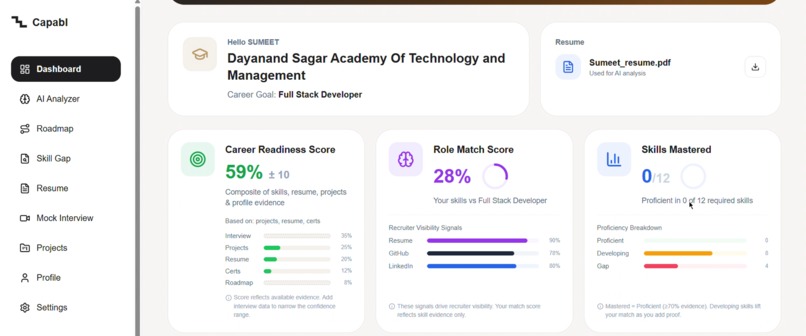
Honest readiness: 59% with a ±10 band, 0/12 skills proven. No false confidence—only what evidence supports.
-
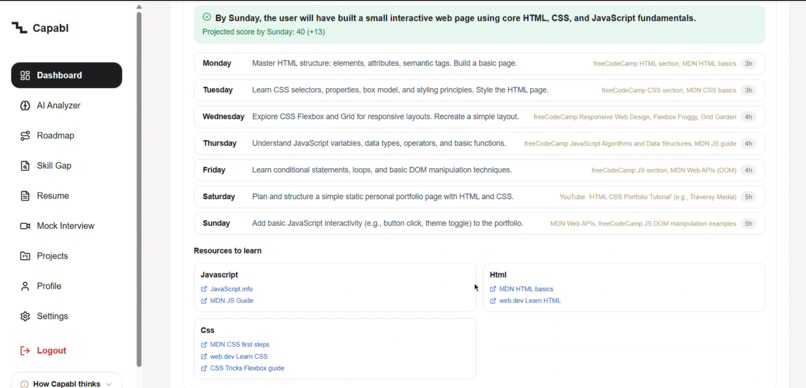
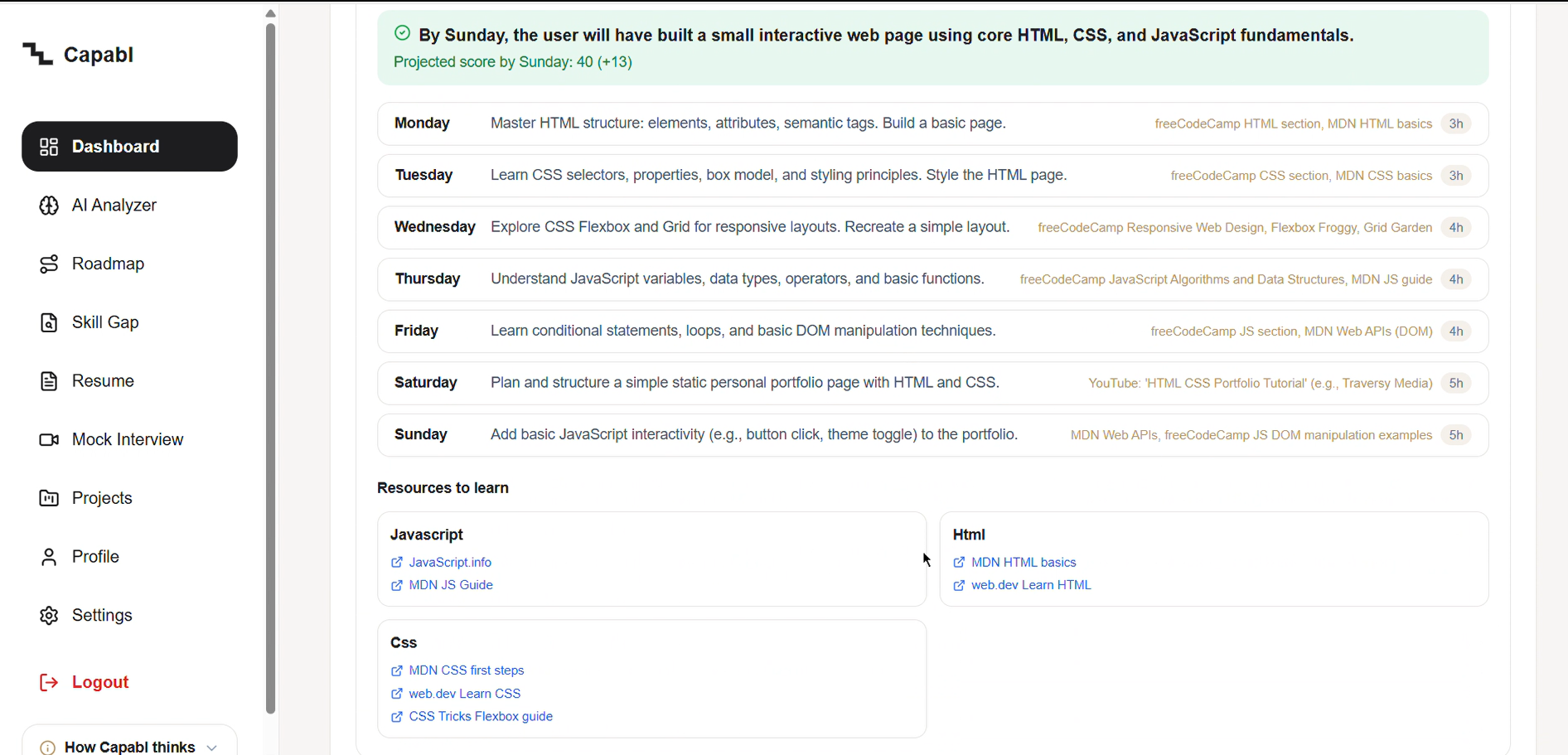
Decision becomes action: your chosen path turns into a day-by-day plan with free resources.
-
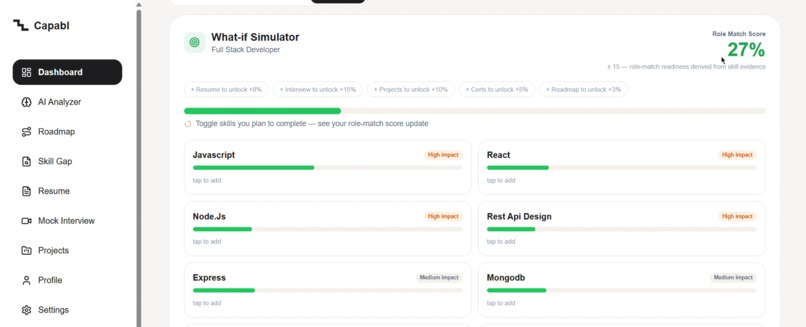
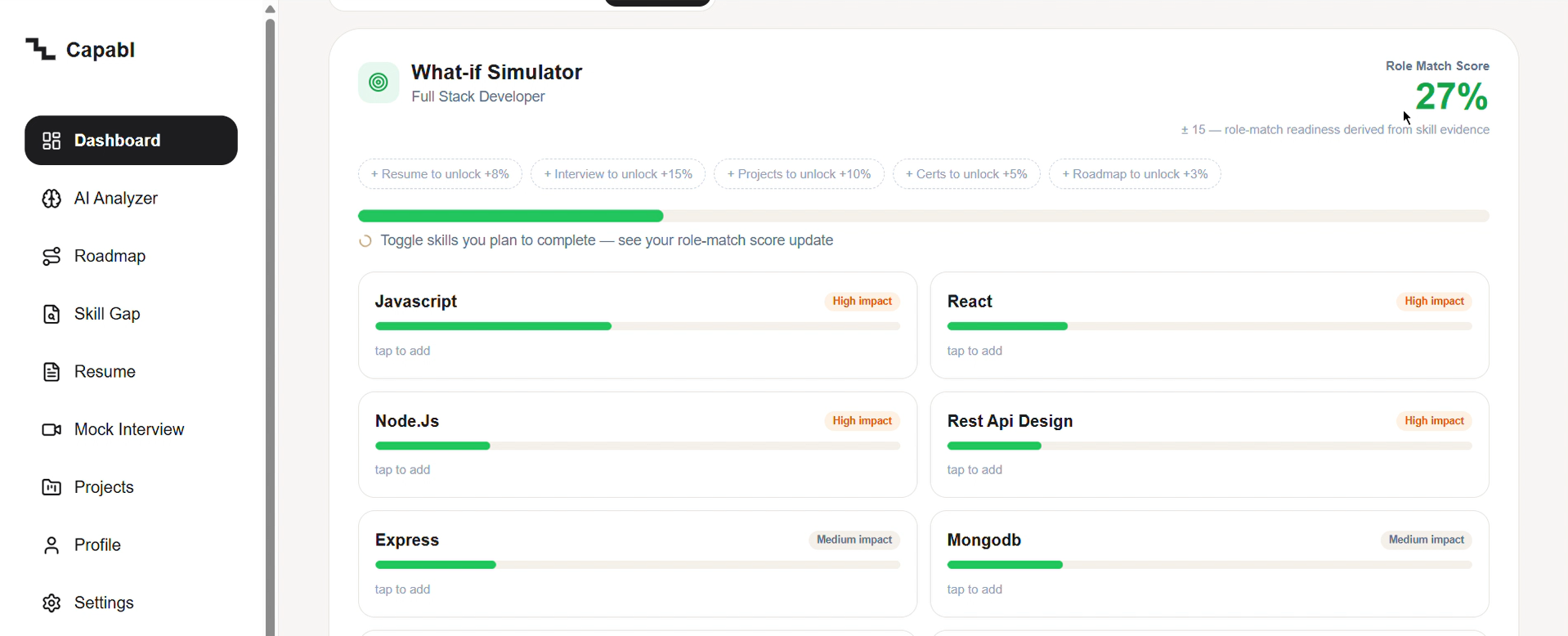
What-If: toggle a skill you'll learn and watch your match climb live—test the impact before committing.
-
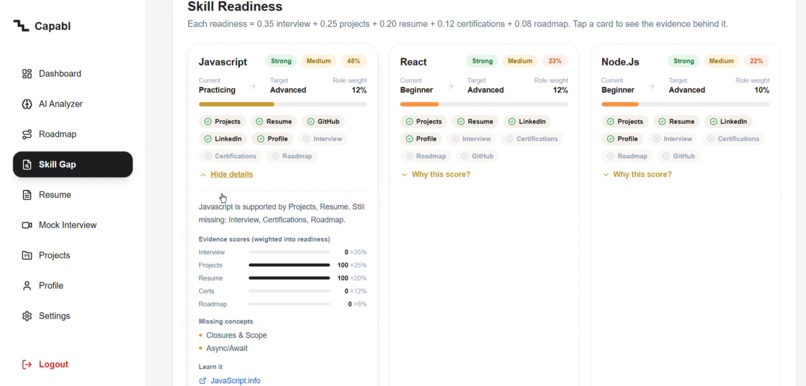
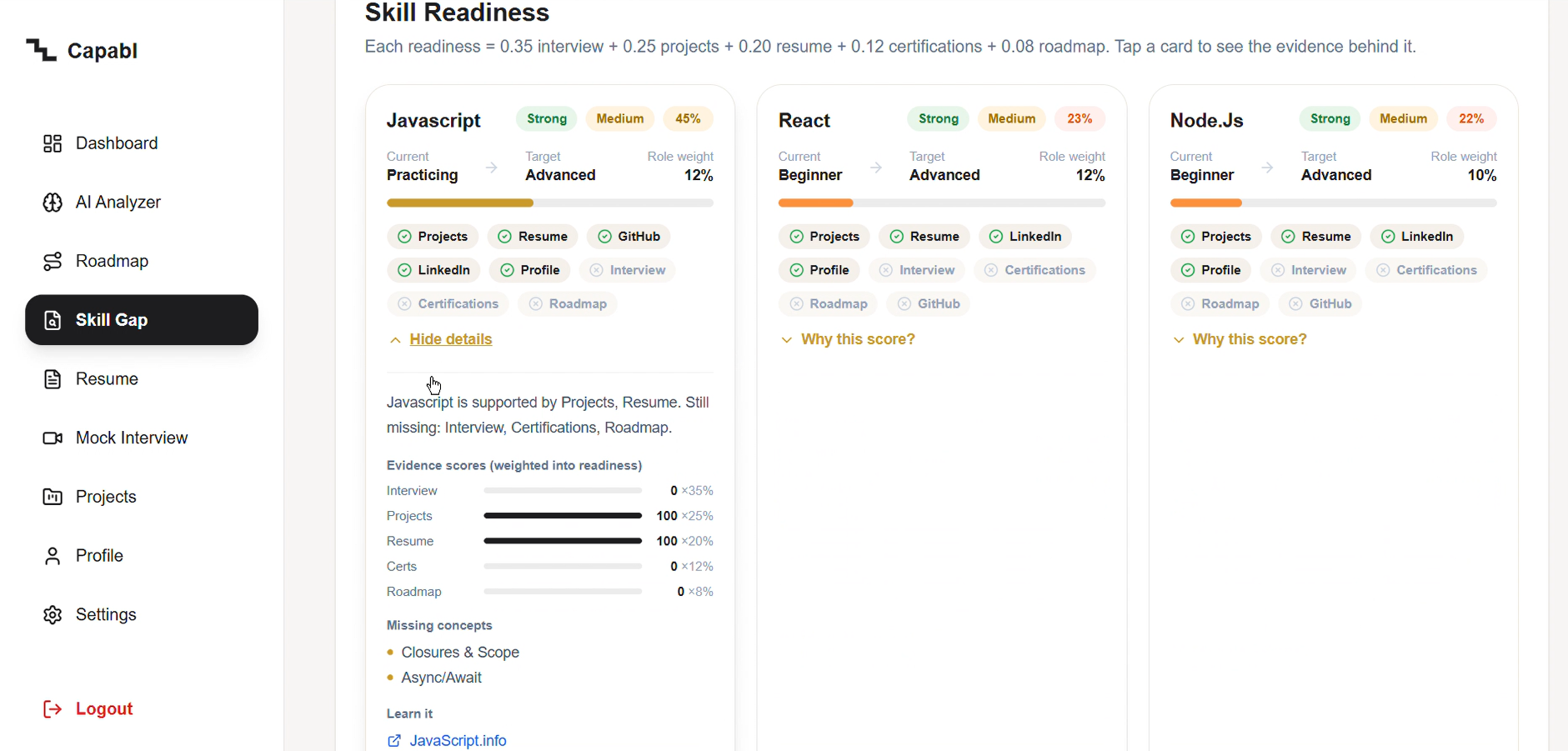
Every score from one documented formula. Tap "Why this score?" for the evidence. The AI never invents a number.
-
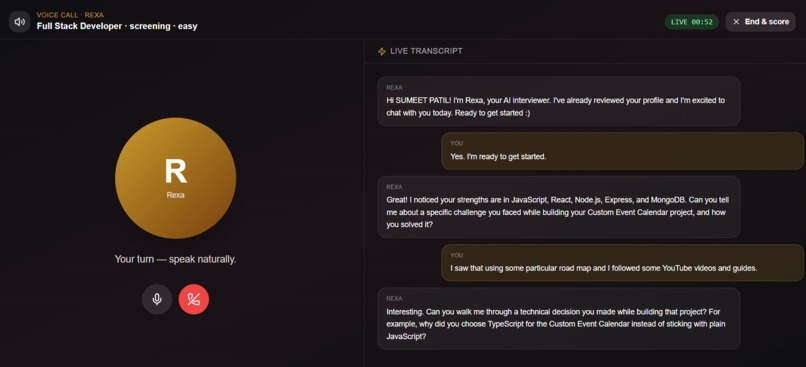
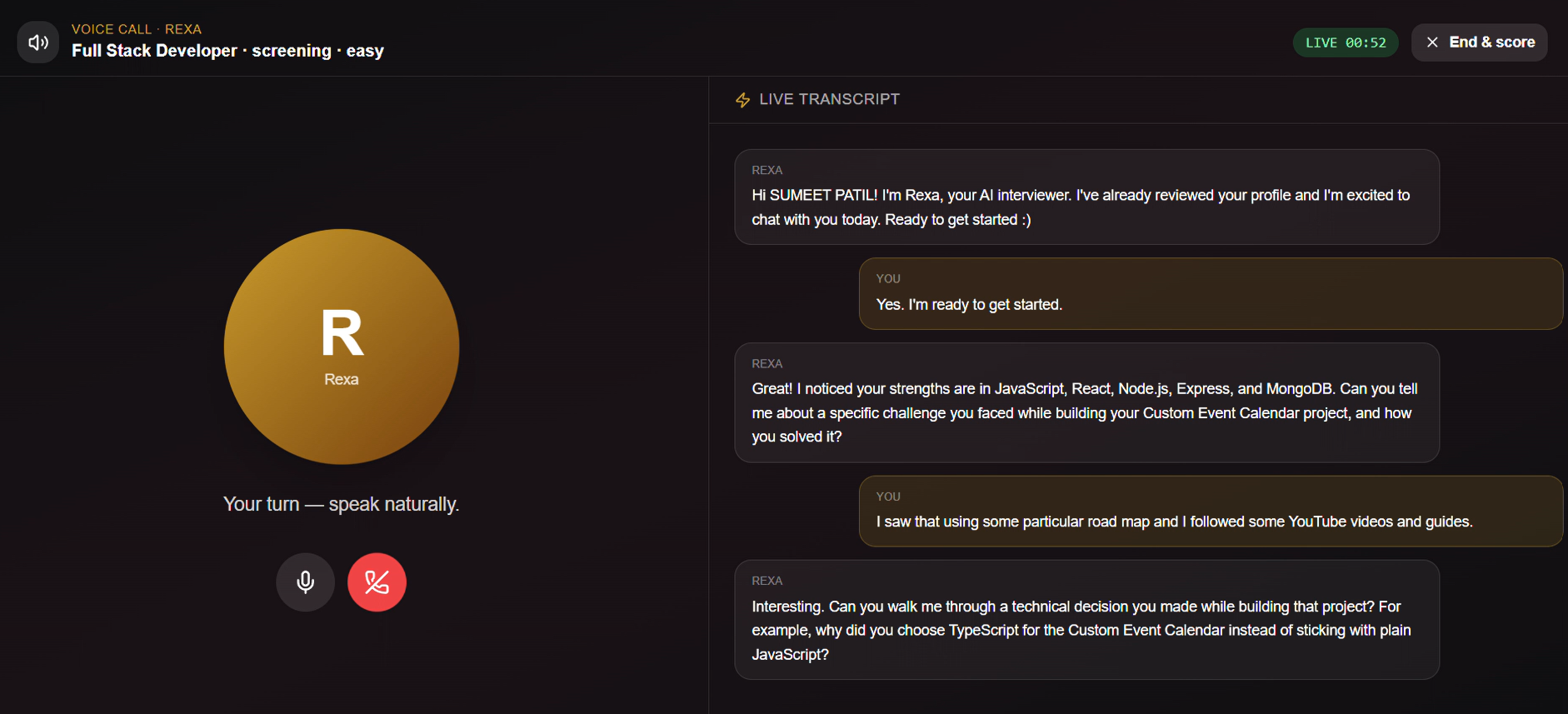
Rexa probes real decisions ("why TypeScript over JS?"), not trivia. Your heaviest evidence source (35%).
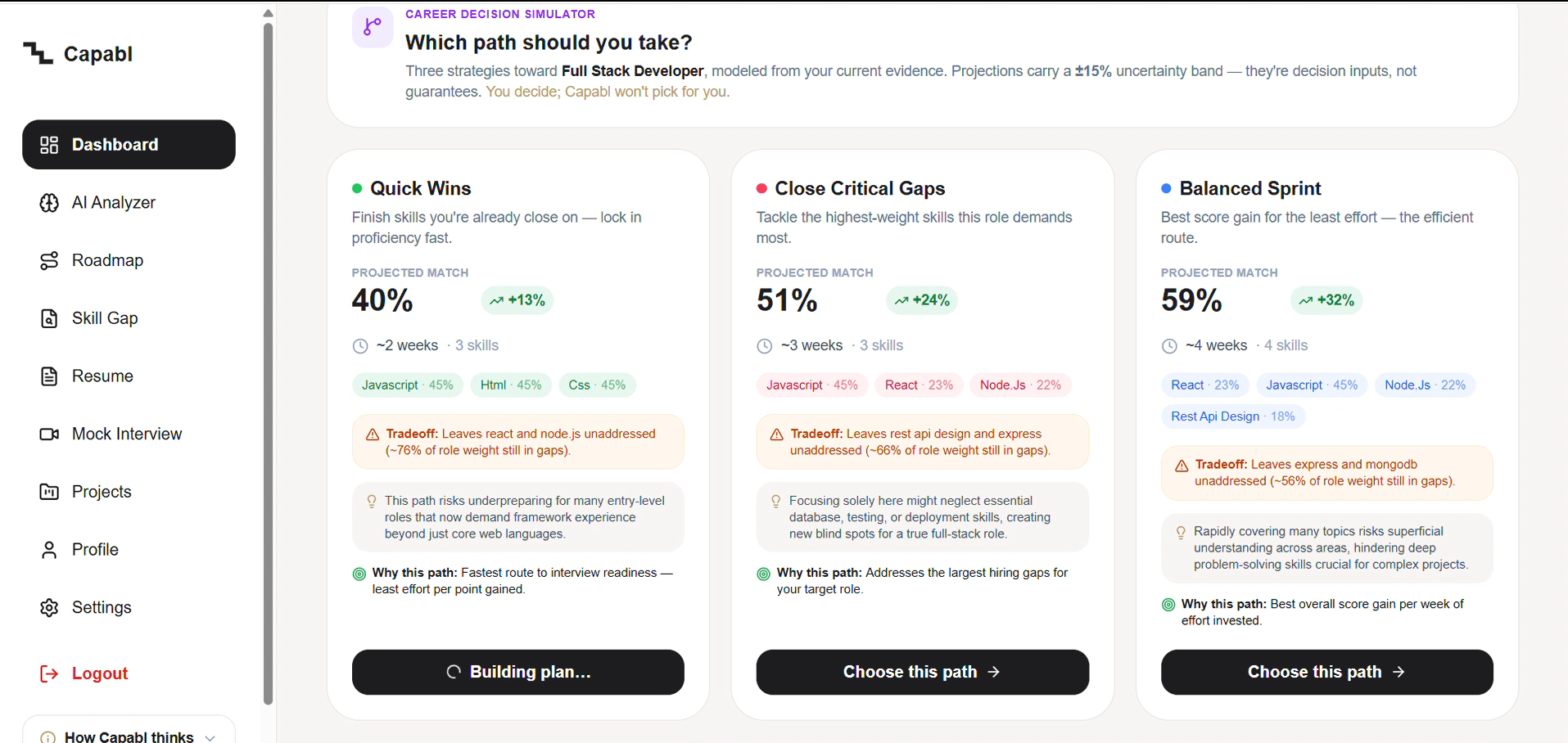
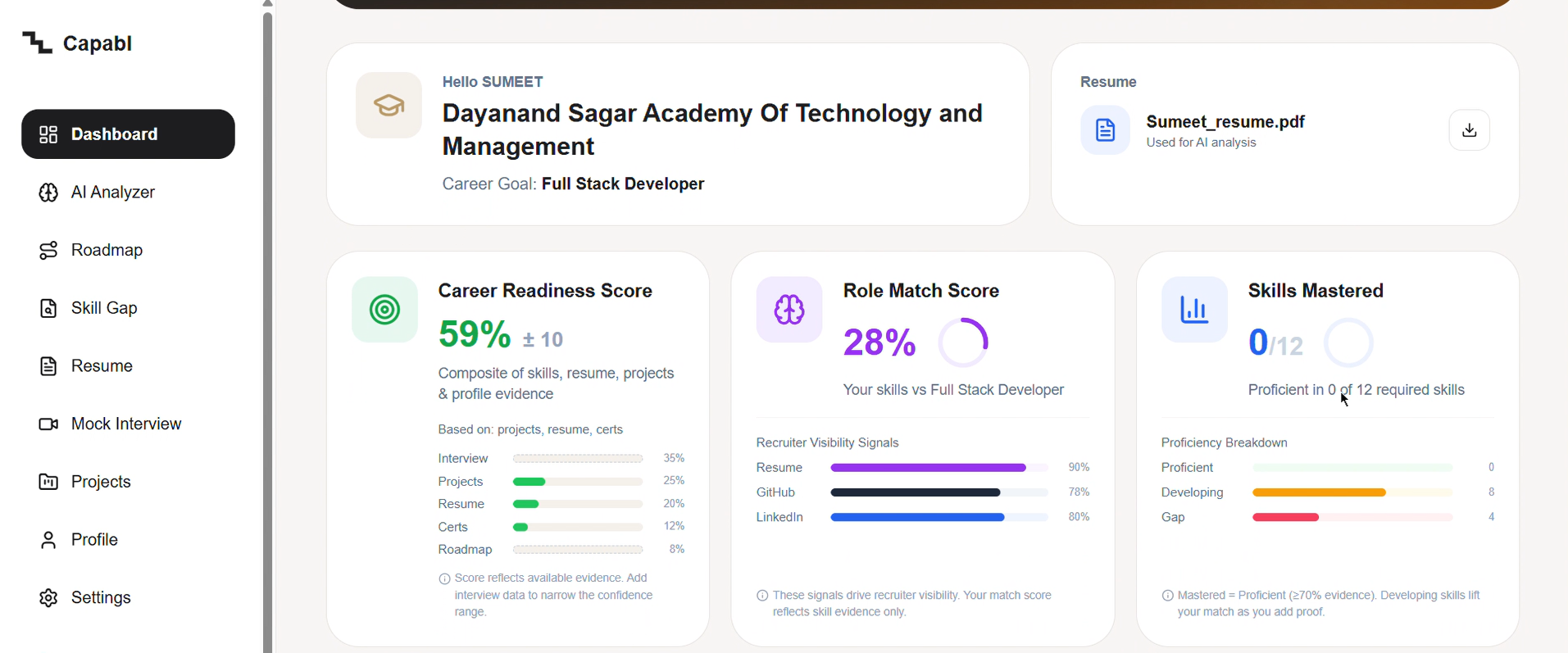
Inspiration
A college student staring at "what do I learn next to actually get hired?" faces overload: dozens of skills, conflicting advice, and no idea what moves the needle. Existing tools either oversimplify ("Learn React!") or overwhelm with 100-item skill checklists. Almost none help you reason through the tradeoffs of competing strategies. We built Capabl around one decision moment:
"Given my real evidence, which learning path do I commit to this month — and what am I giving up by choosing it?"
What it does
Capabl takes a student's real evidence — resume, projects, certifications, a mock interview, optional GitHub/LinkedIn — and a target role, then:
- Builds the role. An LLM reads the goal + resume and returns the 12 skills this exact role demands today, each with an importance weight summing to 100.
- Scores the evidence honestly. For each skill it measures five evidence sources and computes a readiness % using a fixed, auditable formula — never a number the AI made up.
- Simulates three real paths. For example, for one student profile: Quick Wins (+13%, ~2 weeks), Close Critical Gaps (+24%, ~3 weeks), and Balanced Sprint (+32%, ~4 weeks) — each generated by a different objective, so they're genuinely distinct, not one list reshuffled. Each shows the score gain, the effort, and the tradeoff (what you delay by choosing it).
- Hands the decision back to the student. Capabl never auto-picks. The student commits to one path, and it becomes a 7-day plan with free resources.
Confusion → clarity → action.
How we built it
- Role intelligence & explanations: an LLM (Gemini 2.5 Flash) parses the open-ended goal and messy resume, infers required skills + weights, and writes the human-readable reasoning and weekly plan.
- Evidence matching: semantic similarity using
gemini-embedding-001embeddings (cosine similarity), so "built a chatbot" correctly matches "LLM integration" despite different wording. Each skill score is the stronger of a structural keyword match and a semantic match. - The scoring engine (deterministic): every score, gain, and projection comes from a documented formula — not the LLM. Per skill:
$$readiness = 0.35 \cdot interview + 0.25 \cdot projects + 0.20 \cdot resume + 0.12 \cdot certifications + 0.08 \cdot roadmap$$
Role Match is the weight-blended sum of skill readiness; overall Career Readiness blends match, semantic fit, resume strength, profile, skill count, and ATS signals.
Our core design principle: LLM where meaning matters, rules where trust matters. The LLM never outputs a score, so it can't fabricate numbers — every figure a student sees is reproducible and explainable.
Why this needs AI: parsing an open-ended goal and free-text resume needs genuine language understanding (a rules engine can't infer which 12 skills a niche role demands); matching messy evidence despite different vocabulary needs embeddings (keyword matching misses real matches). But every number runs on deterministic rules — that separation is the difference between reasoning and hallucination.
Challenges we ran into
- Keeping the three simulated paths genuinely distinct. We solved it by generating each from a different objective (closest-to-done, highest-weight unmet, best gain-per-effort) rather than re-sorting one list. We verified across 6 synthetic user profiles that paths come out distinct and gains rise coherently.
- Drawing a hard line so the LLM never touches the math — it receives no scores and only writes explanations, which keeps every number reproducible.
- Representing uncertainty honestly instead of handing students a false "correct answer" — solved with confidence bands that widen when evidence is thin.
Accomplishments that we're proud of
- A decision tool that genuinely reasons through tradeoffs instead of generating a pros/cons list.
- A fully auditable scoring pipeline where the AI never invents a number — rare for an LLM-powered tool.
- A clean input → reasoning → output → decision → action pipeline that keeps the human in control at the one moment that matters: the choice.
What we learned
The hard part of a "decision tool" isn't generating options — it's representing uncertainty and tradeoffs honestly so a person can actually reason, instead of being handed a false answer. We also learned where AI genuinely earns its place (meaning) versus where it must stay out (trust-critical numbers).
What's next for Capabl — AI Career Decision Simulator
Wider role coverage, longer-horizon 30/60/90-day plans, and letting students re-run the simulation as their evidence grows to watch their paths shift over time.
Built With
- axios
- bcrypt
- css3
- express.js
- gemini-embeddings
- github-api
- google-gemini
- google-oauth
- html5
- javascript
- jwt
- multer
- node.js
- passport.js
- pdf-parse
- postgresql
- prisma
- react
- react-router
- rest-api
- retell-ai
- tailwindcss
- typescript

Log in or sign up for Devpost to join the conversation.